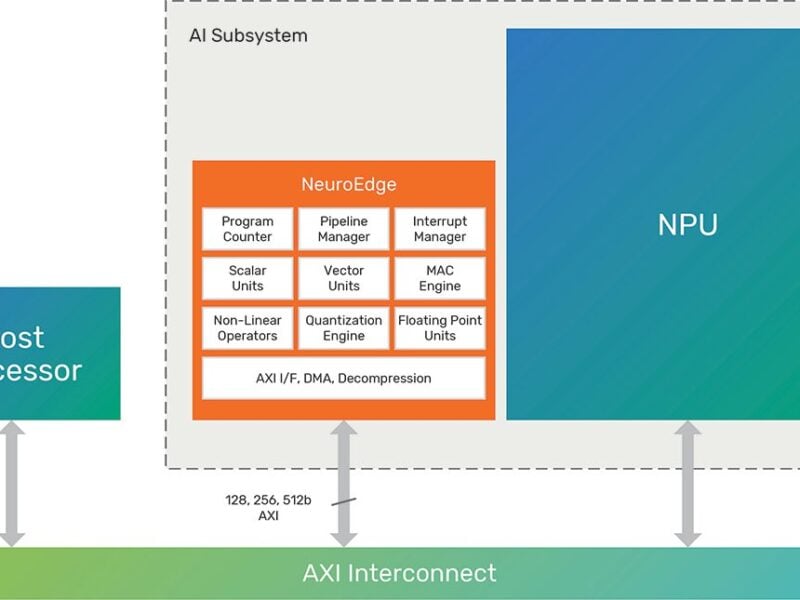
Tensilica全球发布Xtensa LX2和Xtensa 7可配置处理器内核

Tensilica推出Xtensa®可配置处理器内核第七代产品 – Xtensa LX2和Xtensa 7。两款处理器内核在结构上进行了多项改进,并且是第一批内建高速纠错ECC(Error Correcting Code)功能的可授权可配置处理器内核。ECC功能针对诸如存储、网络、汽车电子和事务处理等应用非常重要。Tensilica新一代处理器内核继续保持着最低功耗,最高性能的市场地位,巩固了Tensilica在可配置处理器内核技术的领导地位。两款内核现均已现货发售。
业界最低功耗、最高性能
与传统固定架构的内核相比,Xtensa 7和Xtensa LX2处理器两款内核的基本Xtensa指令集架构提供了业界最低的功耗和最高的性能。由于两款内核均完全可配置,设计工程师可采用Tensilica专利的自动处理器生成器向基本处理器添加专用指令。与其它相竞争的处理器可提供的性能相比,能够对处理器配置扩展是很重要的。例如,一款不带高速缓存,没有设计工程师定义的指令扩展的Xtensa 7最小配置内核跟ARM7TDMI内核的配置大约相当,但具有更好的性能和低的功耗。
基于Xtensa LX2架构的一款高性能处理器配置方案(Diamond 570T)的面积和功耗小于ARM 1136J-S的一半。注:这并不是基本Xtensa LX处理器内核,而是基于Xtensa LX2架构配置得到的一款实用的高性能的通用CPU内核。
功耗降低百分之三十
改进后的Xtensa 7和Xtensa LX2处理器内核降低了近30%功耗(内核加上存储器),其中关键因素包括: 可分别配置主系统存储器接口、本地数据存储器接口和指令存储器接口等诸项接口的宽度减少数据存储器使能和存取的执行判断,令数据高速缓存器和紧耦合的本地数据存储器在长时间不使用情况下处于断电状态。一个可选的更宽的取指令缓冲区可使指令读取的时间和由这些读取指令周期带来的功耗,降低最多75%,具体节电结果视代码长度而定。
同时,Tensilica设计的电源关电模式,包括外部的控制调试端口和片上调试模块的关电,降低了整个系统的功耗。
新ECC功能选项
Tensilica引入两个选项以检测和/或纠正随着硅工艺的尺寸缩小而增加的存储器错误。Tensilica的可配置Xtensa处理器内核的设计工程师现在能够在全部本地紧耦合的存储器中选择校奇偶验位或者ECC保护。当在高速数据缓存阵列、高速缓存标记阵列或者本地存储器(指令和/或数据存储器)中检测到一个单比特软错误时,奇偶校验位产生一个异常。ECC检测并纠正单比特错误和检测双比特错误。Tensilica公司是第一家内建高速ECC纠错能力的处理器架构的IP公司。纠错在诸如存储器和网络应用等非常关注可靠性和精确性的关键应用中极为重要, 比如在汽车应用中将用以满足无差错汽车安全标准的要求。
Rowen博士进一步表示,“随着工艺尺寸的缩小,更小的Cell电容和更低的电压导致软存储器错误的增加。因此,处理器能够检测并纠正软存储器错误越来越重要。这正是Tensilica公司在所有新一代Xtensa内核中添加内建高速ECC纠错功能选项的重要原因。”
其它部分新增功能
Tensilica公司新增多项应用于Xtensa 7和Xtensa LX2处理器内核的功能:
1) 新增处理器接口PIF(Processor Interface)设计工程师选项可用来控制缓冲区(令其更小)进行微调和降低SoC设计中非影响性能的关键路径的功耗。
2) 可以同时配置一个快速本地指令和数据存储器的宽接口和一个系统总线的窄系统接口的选项,使得系统接口和总线设计在降低设计复杂度、减少面积和功耗的同时还可以快速地以高带宽访问本地存储器。
3) TIE(Tensilica指令扩展)语言基础架构已经改进为大型开发团队和公司共享已有的TIE指令模块库提供了更好的机制,可以对多个TIE文件进行操作。
Tensilica公司同时新增支持Xtensa LX处理器内核的高级功能:
1) 新TIE指令查找表端口功能,使得创新存储器的接口的功能超出了已有的做为本地指令和数据存储器接口的功能。与这些设计工程师定义的新的TIE指令查找表端口相连的存储器可直接通过处理器的数据通路来进行读写而无需采用load和store指令。视频系统的设计工程师可将一个TIE指令查找表端口与一个存储视频帧数据的本地缓冲区相连。视频帧数据被外部硬件填充或再填充到处理器数据处理通路中,而无需采用功耗很大的DMA(直接内存存取)。网络设计工程师可将TIE指令查找表端口跟更大的查找表相连,从而能够被处理器快速访问。
2) 一个可选的连接方法是一个cross bar功能,它可将属于两个bank的单端口的本地数据RAM和配置有2个 load/store端口的Xtensa LX2处理器内核相连接。通过这种方式,当这些操作针对相反的bank时,处理器可在每个时钟周期维持2个load/store操作。因此,当采用Xtensa LX2作为带2个load/store端口的XY型DSP架构时,系统设计被极大地简化了。
3) 存储器管理单元(MMU)支
持所有的配置,甚至是7级流水线和Tensilica公司获有专利权的FLIX™(可变长度指令扩展)技术,从而可支持多发射指令的高性能CPU配置。MMU是可运行Linux操作系统必需的,目前的Linux系统支持来自Tensilica的合作伙伴Monta Vista公司。采用FLIX的带MMU功能的Xtensa LX2处理器内核非常适合高性能的、需要运行复杂协议栈的网络应用,以及作为移动和手持应用中的高端处理器。 (注:MMU在Xtensa 7中也是一个选项。)
新型Xtensa 7 处理器内核
第七代Xtensa可配置处理器内核经过优化适合低功耗应用,对控制和DSP(数字信号处理)操作都是理想的选择。Xtensa 32位比特架构有5级流水线、32比特ALU(算术逻辑单元)、高达64个通用物理寄存器、6个专用寄存器和80条基本指令(包括改进的16比特和24比特RISC指令编码,及可最大化代码密度的无模式切换)。在90nm GT工艺下,以针对速度优化的网表,最差的运行环境,时钟速度可达600MHz。在130nm LV工艺下,以针对面积优化的网表,典型的运行环境,一个最小配置(20,000门)内核的功耗为0.038mW/MHz,而在90nm GT工艺下,以针对面积优化的网表,典型的运行环境,功耗为0.048mW/MHz。
新型Xtensa LX2处理器内核
Tensilica公司Xtensa LX2处理器内核包括了Xtensa 7中的全部功能和3项其他不具备的功能:
1) 更加快速的数据输入和输出(I/O),。包括一个增加第二个load/store单元选项和向处理器执行单元中添加设计工程师定义的GPIO(通用输入/输出目的)TIE指令端口和FIFO(先入先出)队列以进行直接数据存取这一Tensilica公司突破性的技术能力。TIE指令端口和队列全都不需要通过总线, 因此无需多条load/store运算来处理数据。
2) Tensilica公司创新的FLIX技术可以令创造出来的处理器配置在每个周期以一种VLIW处理器的方式发射多条指令。Xtensa C/C++编译器(XCC)从C/C++代码中自动地抽取指令层和循环层中的并行运算,并将其打包进FLIX指令集中。这些多发射的FLIX指令可以是32位比特宽或者64位比特宽,并可与基本16位比特和24位比特的指令进行无模式混合。通过将多条指令封装进一个宽32位或者64位的指令字,设计工程师能够在嵌入式应用中加速更多的应用性能瓶颈。
3) Xtensa LX2与带有7级高性能流水线选项的Xtensa 7拥有相同的指令集。Xtensa LX的7级流水线版本在90nm GT 工艺下,以针对速度优化的网表,最差的运行条件能够超过650MHz。在130nm LV工艺下,以面积优化的网表,典型的运行环境,一个最小配置(20,000门)的功耗为0.038mW/MHz,而在90nm GT工艺下,以面积优化的网表,典型的运行环境,功耗为0.048nW/MHz。
广泛的合作伙伴基础
Tensilica公司处理器内核的可配置能力从未危及根本的基本Xtensa指令集,所以确保了一个第三方合作伙伴应用软件和开发工具的强大的生态系统的有效性。所有Xtensa处理器可能的配置经常与主要的操作系统、调试工具和ICE解决方案相兼容;并且常伴有一套自动生成的、完整的软件开发工具链,包括一个基于ECLIPSE框架的高级集成开发环境、一个世界级的编译器、一个周期精确(cycle-accurate)并兼容SystemC的指令集仿真器、以及完整的工业标准的GNU工具链。
可配置、可扩展的Xtensa架构
Xtensa处理器拥有300多项独立的配置选项,设计工程师可根据不同的应用选择恰当的功能进行组合。这些选项包括:乘法器、浮点运算单元、一个音频处理器、一个基本DSP引擎或一个3路VLIW(超长指令字)SIMD(单指令多数据)DSP引擎、处理器总线接口、MMU、32个中断、优化的EDA脚本和操作系统支持等等更多的选项。
为提高2~100倍甚至更高的性能,
设计工程师可采用TIE语言增加专用指令,或者用Tensilica公司的XPRES (Xtensa 处理器扩展综合)编译器自动评估C/C++算法,从而自动开发出优化的TIE指令以加速算法。TIE语言能够描述一条完整的新路径以节省面积和功耗,新路径包括的要素如:新寄存器、寄存器文件、多周期执行单元、设计工程师定义的 GPIO和FIFO接口、SIMD执行单元、一条VLIW数据路径和自定义的多种数据类型,例如面向音频应用的24位数据,面向安全处理的56位数据,或者面向包处理的256位数据。TIE指令编译器读入这条新路径的描述和新指令,然后更新整个编译器工具链(编译器、调试器、分析器等等)、指令集模拟器和系统模型。它同时向处理器硬件中插入优化的门控时钟的执行单元、寄存器、寄存器文件、控制逻辑、旁路逻辑等等。这些操作都是自动执行的,并且Tensilica公司保证其正确性。
采用Xtensa 处理器内核取代硬逻辑模块
Tensilica公司的Xtensa处理器内核经常因为多种原因被用于取代特定的硬连线RTL(寄存器传输级)模块。首先,因为它是可编程的,Xtensa处理器可提供的灵活性是基于纯RTL有限状态机设计无法提供的;第二,流片后算法问题的修复可通过软件更新来实现,可显著减少反复流片的风险;第三,与RTL设计相比,Xtensa处理器内核可降低整个SoC设计和验证的时间;第四,通常Xtensa处理器内核可以比用RTL实现更低的功耗,因为Xtensa处理器生成器可即时自动进行流水线操作分析和插入门控时钟,而用RTL设计来手动进行如此操作一般来说不可能;第五,因为Xtensa处理器内核可以绕过总线,采用GPIO TIE指令端口和FIFO TIE指令队列直接进行数据传输,所以它传输和操作数据的速度和效率能够跟RTL模块一样。








评论