透过Linux内核看无锁编程

多核多线程已经成为当下一个时髦的话题,而无锁编程更是这个时髦话题中的热点话题。Linux内核可能是当今最大最复杂的并行程序之一,为我们分析多核多线程提供了绝佳的范例。内核设计者已经将最新的无锁编程技术带进了2。6系统内核中,本文以2。6。10版本为蓝本,带领您领略多核多线程编程的真谛,窥探无锁编程的奥秘,体味大师们的高雅设计!
本文引用地址:https://www.eepw.com.cn/article/149034.htm非阻塞型同步(Non-blockingSynchronization)简介
如何正确有效的保护共享数据是编写并行程序必须面临的一个难题,通常的手段就是同步。同步可分为阻塞型同步(BlockingSynchronization)和非阻塞型同步(Non-blockingSynchronization)。
阻塞型同步是指当一个线程到达临界区时,因另外一个线程已经持有访问该共享数据的锁,从而不能获取锁资源而阻塞,直到另外一个线程释放锁。常见的同步原语有mutex、semaphore等。如果同步方案采用不当,就会造成死锁(deadlock),活锁(livelock)和优先级反转(priorityinversion),以及效率低下等现象。
为了降低风险程度和提高程序运行效率,业界提出了不采用锁的同步方案,依照这种设计思路设计的算法称为非阻塞型算法,其本质特征就是停止一个线程的执行不会阻碍系统中其他执行实体的运行。
当今比较流行的Non-blockingSynchronization实现方案有三种:
Wait-free
Wait-free是指任意线程的任何操作都可以在有限步之内结束,而不用关心其它线程的执行速度。Wait-free是基于per-thread的,可以认为是starvation-free的。非常遗憾的是实际情况并非如此,采用Wait-free的程序并不能保证starvation-free,同时内存消耗也随线程数量而线性增长。目前只有极少数的非阻塞算法实现了这一点。
Lock-free
Lock-Free是指能够确保执行它的所有线程中至少有一个能够继续往下执行。由于每个线程不是starvation-free的,即有些线程可能会被任意地延迟,然而在每一步都至少有一个线程能够往下执行,因此系统作为一个整体是在持续执行的,可以认为是system-wide的。所有Wait-free的算法都是Lock-Free的。
Obstruction-free
Obstruction-free是指在任何时间点,一个孤立运行线程的每一个操作可以在有限步之内结束。只要没有竞争,线程就可以持续运行。一旦共享数据被修改,Obstruction-free要求中止已经完成的部分操作,并进行回滚。所有Lock-Free的算法都是Obstruction-free的。
综上所述,不难得出Obstruction-free是Non-blockingsynchronization中性能最差的,而Wait-free性能是最好的,但实现难度也是最大的,因此Lock-free算法开始被重视,并广泛运用于当今正在运行的程序中,比如linux内核。
一般采用原子级的read-modify-write原语来实现Lock-Free算法,其中LL和SC是Lock-Free理论研究领域的理想原语,但实现这些原语需要CPU指令的支持,非常遗憾的是目前没有任何CPU直接实现了SC原语。根据此理论,业界在原子操作的基础上提出了著名的CAS(Compare-And-Swap)操作来实现Lock-Free算法,Intel实现了一条类似该操作的指令:cmpxchg8。
CAS原语负责将某处内存地址的值(1个字节)与一个期望值进行比较,如果相等,则将该内存地址处的值替换为新值,CAS操作伪码描述如下:
清单1。CAS伪码
BoolCAS(T*addr,Texpected,TnewValue)
{
if(*addr==expected)
{
*addr=newValue;
returntrue;
}
else
returnfalse;
}
在实际开发过程中,利用CAS进行同步,代码如下所示:
清单2。CAS实际操作
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS(内存地址,备份的旧数据,新数据))
就是指当两者进行比较时,如果相等,则证明共享数据没有被修改,替换成新值,然后继续往下运行;如果不相等,说明共享数据已经被修改,放弃已经所做的操作,然后重新执行刚才的操作。容易看出CAS操作是基于共享数据不会被修改的假设,采用了类似于数据库的commit-retry的模式。当同步冲突出现的机会很少时,这种假设能带来较大的性能提升。
加锁的层级
根据复杂程度、加锁粒度及运行速度,可以得出如下图所示的锁层级:
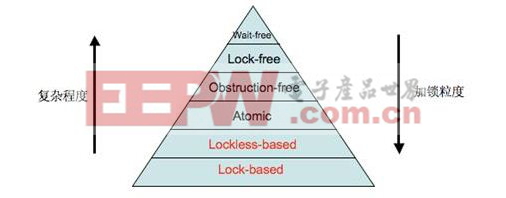
图1。加锁层级
其中标注为红色字体的方案为Blockingsynchronization,黑色字体为Non-blockingsynchronization。Lock-based和Lockless-based两者之间的区别仅仅是加锁粒度的不同。图中最底层的方案就是大家经常使用的mutex和semaphore等方案,代码复杂度低,但运行效率也最低。
Linux内核中的无锁分析
Linux内核可能是当今最大最复杂的并行程序之一,它的并行主要来至于中断、内核抢占及SMP等。内核设计者们为了不断提高Linux内核的效率,从全局着眼,逐步废弃了大内核锁来降低锁的粒度;从细处下手,不断对局部代码进行优化,用无锁编程替代基于锁的方案,如seqlock及RCU等;不断减少锁冲突程度、降低等待时间,如Double-checkedlocking和原子锁等。
无论什么时候当临界区中的代码仅仅需要加锁一次,同时当其获取锁的时候必须是线程安全的,此时就可以利用Double-checkedLocking模式来减少锁竞争和加锁载荷。目前Double-checkedLocking已经广泛应用于单例(Singleton)模式中。内核设计者基于此思想,巧妙的将Double-checkedLocking方法运用于内核代码中。
当一个进程已经僵死,即进程处于TASK_ZOMBIE状态,如果父进程调用waitpid()系统调用时,父进程需要为子进程做一些清理性的工作,代码如下所示:
清单3。少锁操作
984staticintwait_task_zombie(task_t*p,intnoreap,
985structsiginfo__user*infop,
986int__user*stat_addr,structrusage__user*ru)
987{
……
1103if(p->real_parent!=p->parent){
1104write_lock_irq(tasklist_lock);
linux操作系统文章专题:linux操作系统详解(linux不再难懂)
linux相关文章:linux教程






评论