透过Linux内核看无锁编程
}
voiddo_gettimeofday(structtimeval*tv)
{
unsignedlongseq;
unsignedlongusec,sec;
unsignedlongmax_ntp_tick;
……
do{
unsignedlonglost;
seq=read_seqbegin(xtime_lock);
……
sec=xtime。tv_sec;
usec+=(xtime。tv_nsec/1000);
}while(read_seqretry(xtime_lock,seq));
……
tv->tv_sec=sec;
tv->tv_usec=usec;
}
intdo_settimeofday(structtimespec*tv)
{
……
write_seqlock_irq(xtime_lock);
……
write_sequnlock_irq(xtime_lock);
clock_was_set();
return0;
}
Seqlock实现原理是依赖一个序列计数器,当写者写入数据时,会得到一把锁,并且将序列值加1。当读者读取数据之前和之后,该序列号都会被读取,如果读取的序列号值都相同,则表明写没有发生。反之,表明发生过写事件,则放弃已进行的操作,重新循环一次,直至成功。不难看出,do_gettimeofday函数里面的while循环和接下来的两行赋值操作就是CAS操作。
采用顺序锁seqlock好处就是写者永远不会等待,缺点就是有些时候读者不得不反复多次读相同的数据直到它获得有效的副本。当要保护的临界区很小,很简单,频繁读取而写入很少发生(WRRM---WriteRarelyReadMostly)且必须快速时,就可以使用seqlock。但seqlock不能保护包含有指针的数据结构,因为当写者修改数据结构时,读者可能会访问一个无效的指针。
3。Lock-free应用场景三——RCU
在2。6内核中,开发者还引入了一种新的无锁机制-RCU(Read-Copy-Update),允许多个读者和写者并发执行。RCU技术的核心是写操作分为写和更新两步,允许读操作在任何时候无阻碍的运行,换句话说,就是通过延迟写来提高同步性能。RCU主要应用于WRRM场景,但它对可保护的数据结构做了一些限定:RCU只保护被动态分配并通过指针引用的数据结构,同时读写控制路径不能有睡眠。以下数组动态增长代码摘自2。4。34内核:
清单7。2。4。34RCU实现代码
其中ipc_lock是读者,grow_ary是写者,不论是读或者写,都需要加spinlock对被保护的数据结构进行访问。改变数组大小是小概率事件,而读取是大概率事件,同时被保护的数据结构是指针,满足RCU运用场景。以下代码摘自2。6。10内核:
清单8。2。6。10RCU实现代码
#definercu_read_lock()preempt_disable()
#definercu_read_unlock()preempt_enable()
#definercu_assign_pointer(p,v)({
smp_wmb();
(p)=(v);
})
structkern_ipc_perm*ipc_lock(structipc_ids*ids,intid)
{
……
rcu_read_lock();
entries=rcu_dereference(ids->entries);
if(lid>=entries->size){
rcu_read_unlock();
returnNULL;
}
out=entries->p[lid];
if(out==NULL){
rcu_read_unlock();
returnNULL;
}
……
returnout;
}
staticintgrow_ary(structipc_ids*ids,intnewsize)
{
structipc_id_ary*new;
structipc_id_ary*old;
……
new=ipc_rcu_alloc(sizeof(structkern_ipc_perm*)*newsize+
sizeof(structipc_id_ary));
if(new==NULL)
returnsize;
new->size=newsize;
memcpy(new->p,ids->entries->p,sizeof(structkern_ipc_perm*)*size
+sizeof(structipc_id_ary));
for(i=size;inew->p[i]=NULL;
}
old=ids->entries;
/*
*Usercu_assign_pointer()tomakesurethememcpyedcontents
*ofthenewarrayarevisiblebeforethenewarraybecomesvisible。
*/
rcu_assign_pointer(ids->entries,new);
ipc_rcu_putref(old);
returnnewsize;
}
纵观整个流程,写者除内核屏障外,几乎没有一把锁。当写者需要更新数据结构时,首先复制该数据结构,申请new内存,然后对副本进行修改,调用memcpy将原数组的内容拷贝到new中,同时对扩大的那部分赋新值,修改完毕后,写者调用rcu_assign_pointer修改相关数据结构的指针,使之指向被修改后的新副本,整个写操作一气呵成,其中修改指针值的操作属于原子操作。在数据结构被写者修改后,需要调用内存屏障smp_wmb,让其他CPU知晓已更新的指针值,否则会导致SMP环境下的bug。当所有潜在的读者都执行完成后,调用call_rcu释放旧副本。同Spinlock一样,RCU同步技术主要适用于SMP环境。
环形缓冲区是生产者和消费者模型中常用的数据结构。生产者将数据放入数组的尾端,而消费者从数组的另一端移走数据,当达到数组的尾部时,生产者绕回到数组的头部。
如果只有一个生产者和一个消费者,那么就可以做到免锁访问环形缓冲区(RingBuffer)。写入索引只允许生产者访问并修改,只要写入者在更新索引之前将新的值保存到缓冲区中,则读者将始终看到一致的数据结构。同理,读取索引也只允许消费者访问并修改。
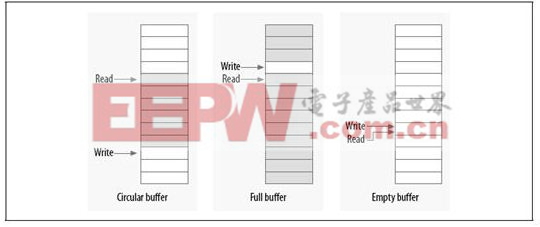
图2。环形缓冲区实现原理图
如图所示,当读者和写者指针相等时,表明缓冲区是空的,而只要写入指针在读取指针后面时,表明缓冲区已满。
清单9。2。6。10环形缓冲区实现代码
/*
*__kfifo_put-putssomedataintotheFIFO,nolockingversion
*Notethatwithonlyoneconcurrentreaderandoneconcurrent
*writer,youdon'tneedextralockingtousethesefunctions。
linux操作系统文章专题:linux操作系统详解(linux不再难懂)
linux相关文章:linux教程







评论