多年来,英伟达在许多机器学习基准测试中占据主导地位,现在它又多了两个档次。MLPerf,有时被称为“机器学习的奥林匹克”的人工智能基准测试套件,已经发布了一套新的训练测试,以帮助在竞争计算机系统之间进行更多更好的同类比较。MLPerf 的一项新测试涉及对大型语言模型的微调,该过程采用现有的训练模型,并用专业知识对其进行更多训练,使其适合特定目的。另一个是图神经网络,一种机器学习,一些文献数据库背后的一种机器学习,金融系统中的欺诈检测,以及社交网络。即使使用谷歌和英特尔的人工智能加速器的计算机增加和参与,由
关键字:
GPU 神经网络 LLM MLPerf 基准测试 英伟达
IT之家 6 月 19 日消息,中国电信人工智能研究院(TeleAI)和智源研究院联合发布全球首个单体稠密万亿参数语义模型 Tele-FLM-1T,该模型与百亿级的 52B 版本,千亿级的 102B 版本共同构成 Tele-FLM 系列模型。TeleAI 和智源研究院基于模型生长和损失预测等技术,Tele-FLM 系列模型仅使用了业界普通训练方案 9% 的算力资源,基于 112 台 A800 服务器,用 4 个月完成 3 个模型总计 2.3T tokens 的训练。模型训练全程做到了零调整零重试
关键字:
LLM AI 大语言模型
1 前言在前一期里,介绍过大语言模型(LLM)幕后核心的注意力(Attention)机制。本期就来继续扩大,介绍大名鼎鼎的转换器(Transformer)模型。其中,要特别阐述:为什么当今主流LLM都采用<仅译码器>(Decoder-Only Transformer)模型。在 2017 年, 首先在「Attention is All You Need」这篇论文中提出了经典的Transformer架构,它内含编码器(Encoder)和译码器(Decoder)两部分。后来,自从GPT-2之后,整个
关键字:
202406 LLM
人工智能芯片研发及基础算力平台公司爱芯元智宣布,近日,Meta、Microsoft相继发布具有里程碑意义的Llama 3系列和Phi-3系列模型。为了进一步给开发者提供更多尝鲜,爱芯元智的NPU工具链团队迅速响应,已基于AX650N平台完成 Llama 3 8B和Phi-3-mini模型适配。Llama 3上周五,Meta发布了Meta Llama 3系列语言模型(LLM),具体包括一个8B模型和一个70B模型在测试基准中,Llama 3模型的表现相当出色,在实用性和安全性评估中,与那些市面上流行的闭源模
关键字:
爱芯通元 NPU Llama 3 Phi-3 大模型
在Meta发布Llama 3大语言模型的第一时间,英特尔即优化并验证了80亿和700亿参数的Llama 3模型能够在英特尔AI产品组合上运行。在客户端领域,英特尔锐炫™显卡的强大性能让开发者能够轻松在本地运行Llama 3模型,为生成式AI工作负载提供加速。在Llama 3模型的初步测试中,英特尔®酷睿™Ultra H系列处理器展现出了高于普通人阅读速度的输出生成性能,而这一结果主要得益于其内置的英特尔锐炫GPU,该GPU具有8个Xe核心,以及DP4a AI加速器和高达120 GB/s的系统内存带宽。英特
关键字:
英特尔 锐炫 GPU Llama 3
近日,Meta重磅推出其80亿和700亿参数的Meta Llama 3开源大模型。该模型引入了改进推理等新功能和更多的模型尺寸,并采用全新标记器(Tokenizer),旨在提升编码语言效率并提高模型性能。在模型发布的第一时间,英特尔即验证了Llama 3能够在包括英特尔®至强®处理器在内的丰富AI产品组合上运行,并披露了即将发布的英特尔至强6性能核处理器(代号为Granite Rapids)针对Meta Llama 3模型的推理性能。图1 AWS实例上Llama 3的下一个Token延迟英特尔至强处理器可
关键字:
英特尔 至强6 Meta Llama 3
近年来,人工智能发展迅速,尤其是像 ChatGPT 这样的基础大模型,在对话、上下文理解和代码生成等方面表现出色,能够为多种任务提供解决方案。但在特定领域任务上,由于专业数据的缺乏和可能的计算错误,它们的表现并不理想。同时,虽然已有一些专门针对特定任务的 AI 模型和系统表现良好,但它们往往不易与基础大模型集成。为了解决这些重要问题,TaskMatrix.AI 破茧而出、应运而生,这是由微软(Microsoft)设计发布的新型 AI 生态系统。其核心技术近期在《科学》合作期刊 Inte
关键字:
AI LLM
1 前言在本专栏去年的文章《从隐空间认识CLIP 多模态模型》里,已经介绍过了:CLIP 的核心设计概念是,把各文句和图像映射到隐空间里的一个点( 以向量表示)。其针对每一个文句和图像都会提取其特征,并映射到这个隐空间里的某一点。然后经由矩阵计算出向量夹角的余弦(Cosine) 值,来估计它们之间的相似度(Similarity)。此外,在Transformer 里扮演核心角色的点积注意力(Dot-Product attention) 机制,其先透过点积运算,从Q与K矩阵计算出的其相似度(Similarit
关键字:
202403 LLM 相似度 CLIP Transformer
ChatGPT 的发布是语言大模型(LLM)发展史的转折点,它让人们意识到 LLM 的潜力,并引发了 “AI 竞赛”,世界上主要人工智能实验室和初创公司都参与其中。在这之后,基于 LLM 的聊天机器人层出不穷。1语言模型简单来说,语言模型能够以某种方式生成文本。它的应用十分广泛,例如,可以用语言模型进行情感分析、标记有害内容、回答问题、概述文档等等。但理论上,语言模型的潜力远超以上常见任务。想象你有一个完备的语言模型,可生成任意类型的文本,并且人们还无法辨别这些内容是否由计算机生成,那么我们就可以使其完成
关键字:
人工智能 LLM 大语言模型
8月10日消息,当地时间周三IBM表示,计划在旗下的企业级人工智能和数据平台Watsonx上提供Meta开发的大语言模型Llama 2。IBM的Watsonx平台能帮助企业将人工智能整合到工作流程中。这一最新举措为Meta公司的一些客户提供了试用Llama 2的机会。去年年底OpenAI发布的人工智能聊天机器人ChatGPT引起了消费者和企业的广泛兴趣。自那以后,更多企业希望将人工智能引入工作流程,引入先进功能的同时也有助于提高企业的工作效率。IBM表示,Watsonx提供Meta的开源人工智能模型之后,
关键字:
IBM 企业云 Watsonx Meta 大语言模型 Llama 2
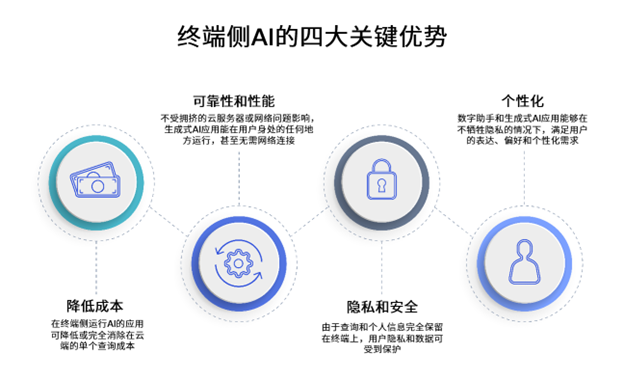
· 高通计划从2024年起,在旗舰智能手机和PC上支持基于Llama 2的AI部署,赋能开发者使用骁龙平台的AI能力,推出激动人心的全新生成式AI应用。· 与仅仅使用云端AI部署和服务相比,终端侧AI部署能够助力开发者以显著降低的成本,提升用户隐私保护、满足用户安全偏好、增强应用可靠性,并实现个性化。 2023年7月18日,圣迭戈——高通技术公司和Met
关键字:
高通 Meta Llama 2 终端侧AI
全球科技巨头纷纷加入人工智能(AI)竞赛,脸书母公司Meta今天推出语言模型LLaMA,表示将能协助研究人员找到修复聊天机器人潜在危险的方法。聊天机器人ChatGPT的核心技术就是来自于语言模型。综合法新与路透社报导,Meta形容LLaMA是一套「更小、性能更好」的模型,「能够协助研究人员推展工作」,隐讳批评微软(Microsoft)广泛发布这项技术,却又将程序代码保密的决定。Meta发言人表示,LLaMA目前尚未应用在Meta的产品,像是脸书(Facebook)和Instagram当中,公司计划将这项技
关键字:
Meta AI竞赛 语言模型 LLaMA
llama 3.2 llm介绍
您好,目前还没有人创建词条llama 3.2 llm!
欢迎您创建该词条,阐述对llama 3.2 llm的理解,并与今后在此搜索llama 3.2 llm的朋友们分享。
创建词条
关于我们 -
广告服务 -
企业会员服务 -
网站地图 -
联系我们 -
征稿 -
友情链接 -
手机EEPW
Copyright ©2000-2015 ELECTRONIC ENGINEERING & PRODUCT WORLD. All rights reserved.
《电子产品世界》杂志社 版权所有 北京东晓国际技术信息咨询有限公司
京ICP备12027778号-2 北京市公安局备案:1101082052 京公网安备11010802012473