AI将高端移动设备从 SoC 推向多晶粒

先进封装正在成为高端手机市场的关键差异化因素,与片上系统相比,它实现了更高的性能、更大的灵活性和更快的上市时间。
单片 SoC 可能仍将是低端和中端移动设备的首选技术,因为它们的外形尺寸、经过验证的记录和较低的成本。但多晶片组件提供了更大的灵活性,这对于 AI 推理和跟上 AI 模型和通信标准的快速变化至关重要。最终,OEM 和芯片制造商必须决定适应设计周期变化的最佳方式,以及瞄准哪些细分市场。
Synopsys 移动、汽车和消费类 IP 产品管理执行董事兼 MIPI 联盟主席 Hezi Saar 表示:“不依赖于手机制造商的 SoC 供应商必须通过 AI 来追求物联网 SoC 的低端功能,而这无疑是单体的。“如果他们需要追求移动的中端市场,那是比 IoT 更高的功能。它也可能是一个单片 [SoC],并有可能选择通过多晶粒添加它。当你走向高端时,很明显你不能只做整体式的。你需要能够进行多晶粒测试,以适应将要发生的变化并加快上市时间,因为这确实是他们赚到最多钱的地方。
换句话说,目标市场决定了架构。Ansys产品营销总监Marc Swinnen表示:“我们看到了多晶粒3D的大趋势,移动设备正在采用这一趋势,但其速度比NVIDIA或AMD的HPC芯片要慢得多,而这些芯片在3D和2.5D系统上已经完全发展了12颗巨大的芯片。“低端移动设备无法做到这一点。这在很大程度上是一个成本问题。他们必须真正专注于将尽可能多的内容集成到单个芯片中,具有低功耗和高速度。
单片 SoC 包含在单片硅片上运行系统所需的所有组件,并且可能包括具有一个或多个处理器内核的嵌入式微控制器;内存系统,例如 RAM 或 ROM;外部接口,如电缆端口(USB、HDMI);无线通信(WiFi、蓝牙);图形处理单元 (GPU);以及其他组件,例如模拟/数字转换器、稳压器和内部接口总线。
尽管单片 SoC 尺寸紧凑,而且通常正因为如此,它们的效率非常高,而且在每个处理器上的性能通常优于更复杂的系统。信号需要传播的距离很短,驱动这些信号所需的功率较低,并且可以通过简单的散热器去除热量。许多 IoT SoC 供应商都采用整体式策略,因为它可以为客户节省打包和集成成本。
“将东西放在单个芯片上总是更好,尽管我们很难做到,”Synaptics 低功耗边缘 AI 高级产品经理 Ananda Roy 说。“它使我们处于竞争优势,因为我们的一些物联网竞争对手将两个晶片放在一个封装中,将它们堆叠起来,或者并排放置,并称之为单芯片解决方案。但实际上,这些只是一个封装中的两个不同的芯片。我们有意识地尝试向单晶片解决方案迈进,因为从客户的角度来看,它更容易集成,也更容易设计到他们的硬件系统中。我们基本上在单个芯片上构建了多种技术。
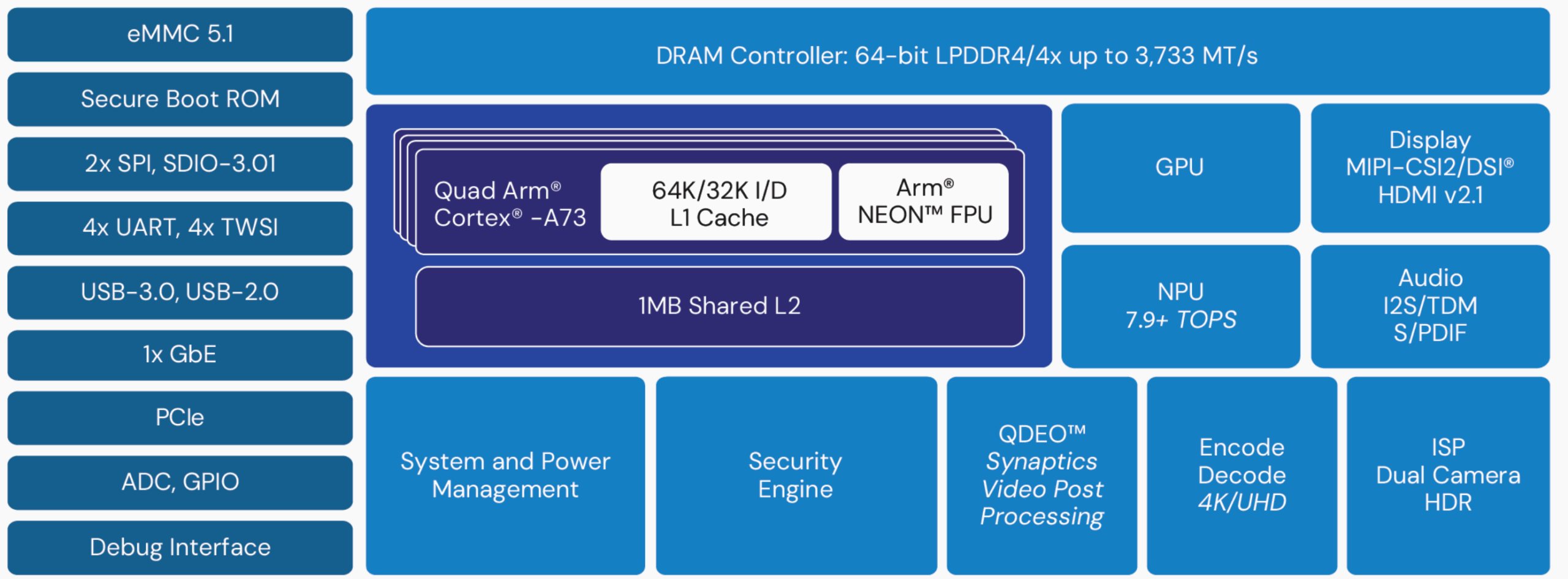
图 1:嵌入式 IoT SoC。 资料来源:Synaptics
在高端移动市场,情况就不同了。在那里,多个小芯片被用来提高性能,更多的互连被用来降低电阻和电容。“在这种情况下,计算引擎通过高性能水平 die-to-die 接口和先进的封装技术进行'镜像'和连接,以扩展计算处理能力,”Cadence 计算解决方案集团高级产品组总监 Mick Posner 说。“从技术上讲,这可以扩展到 3D-IC 堆栈中垂直扩展晶粒的处理,从而实现更高的互连带宽。”
多晶片组件还允许计算元件的更大多样性,其中可以包括 CPU 和 GPU 的组合,以及高度专业化的加速器。“3D 堆叠不仅限于相同的处理单元,”Posner 说。“AI 或内存加速器单元可以成为堆栈的一部分,创建高效的、特定于领域的应用程序引擎。利用先进的 3.5D 封装将使另一个晶粒能够水平连接,也可以使用更传统的晶粒间互连,例如 UCIe。其他晶粒不需要与处理节点位于同一技术节点中。集成各种节点可以在性能和成本之间进行权衡,同时选择最适合应用程序功能或供应链弹性的节点。
在千禧年的头几十年里,移动市场推动了许多前沿技术的发展。但是,随着 finFET 时代平面扩展优势的减少,无法扩展 SRAM,以及云中对大规模计算能力的需求不断增长,系统公司从单片 SoC 转向 2.5D 系统,通过中介层连接多个芯片。虽然移动市场仍处于工艺扩展的前沿,但移动市场的高端已经扩展到多芯片组件——尽管目前尚不清楚移动设备是否会采用 3D-IC,因为它们需要某种类型的先进冷却系统,这在当今的移动设备中是不切实际的。
“2.5D 非常快速、非常有效、超短距离,因此非常高效的功率,”Synopsys 的 Saar 说。“[模具可以] 采用不同的工艺制造。这个可以是 2nm(基础芯片),而 AI 加速器可以是其他东西。他们有灵活性。
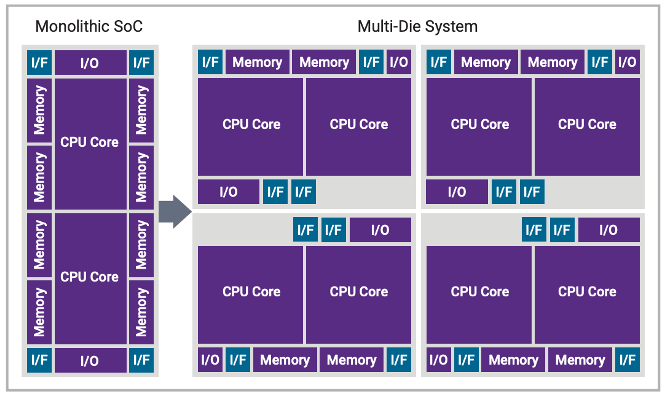
图 2:单片 SoC 与多晶片 来源:Synopsys
高端移动设备正在推动全能栅极 (GAA) 2nm 制造工艺以实现高性能,但价格昂贵且生产时间长。“GAA 需要 X 个月才能从晶圆厂恢复过来,”Saar 说。“你需要压缩所有这些,这是最大的挑战。你正在录制一些过去值得制作的东西。这一次,您知道您至少需要再旋转一次,也许在您旋转它时,规格会再次演变。我以为我需要 70 亿个参数。现在我需要 140 亿个参数,因为手机中的用例已经发生了变化。在未来,我不知道会是什么,但他们在推出这些功能时需要考虑到这一点。这就是为什么多晶粒似乎是市场方面必须采取的灵活性、不确定性和规格的持续演变以及风险缓解的正确答案。
Saar 指出,每个手机供应商都可以根据它想要占领的市场数量来决定如何实施 AI。“你可以在片上有一个 AI 加速器。它可以在单独的芯片中。它可以是专用的。它可以是几个专用的 AI 加速器。这取决于你想要的马力。假设我想要一个用于功能手机的基础芯片。我正在添加一个 AI 加速器芯片,这是两者之间的 3D 连接。现在,我又增加了一个 I/O 扩展,因为我想进入多媒体市场。现在我需要更多的显示功能。我需要 EDP(电子数据处理)。SoC 供应商可以将基础芯片(独立、单片)销售给该功能手机市场。他们可以添加加速器。现在它是一个智能手机配置,他们可以在侧面添加另一个。然后它变成了消费类设备、超级机器人或 PC,他们可以玩转所有这些配置,这样他们就可以攻击不同的市场。

图 3:用于数据中心(或未来高端移动设备)的 3D-IC,顶部有 AI 加速器。来源:Synopsys
通过将 AI 加速器放在第二个芯片上,供应商可以获得更好的性能,因为它在使用相同的基础的同时进行了优化。“现在,它不是一次又一次地花费数亿美元旋转硅,而是更加稳定,”Saar 说。
采用多晶粒的另一个原因是考虑模拟和数字信号。例如,Synaptics 用于可折叠移动 OLED 显示器的触摸控制器可以区分仅握持设备、袖珍拨号、水滴或汗水。“我们的芯片有一个模拟芯片和一个数字芯片,模拟芯片直接连接到传感器,数字芯片处理所有这些信息,”Synaptics 产品营销总监 Sam Toba 说。“在这个数字芯片中,我们有一个 MCU 内核,以前我们有一个内部定制的 MCU 内核,它确实有很多优势。但是一旦你接触到这些可折叠设备,需要处理的信息量就会变得非常非常高,为此我们决定使用 RISC-V。Si-Five 的 E7 是一个非常强大的 MCU 内核,非常适合高水平的处理,而我们的矢量协处理器就在它之外。
然后,AI/ML 算法可以确定环境并检测真实的手指触摸。“我们的芯片连接到触摸传感器,查看所有信号,将模拟信号放入模拟芯片,然后在数字芯片上进行处理,”Toba 说。“该数字芯片包括 E7、Hydra、所有算法和内存。一旦芯片确定触摸是有意义的、有意的,那么它就会向主机 SoC 报告。
内存和通信复杂性
与 AI 一样,内存也在发生变化,并且可能因不同的市场而异。Saar 说,如果 SoC 供应商瞄准所有市场,他们有几种方法可以做到这一点。“他们可以做整体式的。但是,它们将如何适应硅的多次旋转?他们现在有 LPDDR 6,这已经被定义过了,但它会继续发展。UFS 5.0 现在已经定义,但它将继续发展。那么他们会再旋转一个 2nm 硅吗?或者他们会将其限制在其他方面?
此外,还需要考虑多种网络。手机芯片需要足够灵活,以支持新的 5G/6G 协议,同时继续支持旧技术。“在单个系统中支持额外的带宽会增加数据处理的复杂性,并意味着大量的功耗,因此您必须非常有效地实施它,”Fraunhofer IIS/EAS 高效电子部门负责人 Andy Heinig 说。“否则,一方面,移动设备的电池将在很短的时间内耗尽。而且你还必须去除另一侧的热量。您有这些多物理场要求,并且需要非常高效的加速器、非常高效的 DSP 实现、数据处理等。这就是为什么每个人都越来越多地谈论特定应用的处理器的原因。
在前沿设计中,这在很大程度上涉及小芯片和异构集成。在智能手机的模拟/混合信号领域,这有助于抵消多晶片组件的一些额外成本。根据 Cadence 的一份白皮书,这种方法允许“灵活地为 IP 选择最佳工艺节点,尤其是对于不需要位于'核心'工艺节点上的 SerDes I/O、RF 和模拟 IP”。

图 4:分解的 SoC。来源:Cadence
电源、电池和散热考虑因素
在高端移动市场,供应商正争先恐后地启用 AI。“iPhone 15 和 16 的 AI 硬件已添加到板载处理中,许多智能和硬件都在硅级别被放入这些芯片中,”Siemens Digital Industries Software 解决方案网络专家 Ron Squiers 说。“NVIDIA 等其他公司正在构建 GPU。Arm 正在构建 Zen 5 [CPU],它充当平台上 AI 硬件的编排器。Amazon 正在开发他们的 Trainium 训练和推理芯片,因此超大规模公司和移动开发人员都在做这件事。
虽然移动设备始终需要 GPU 进行图形处理,但最新版本同样可以很好地处理 AI 工作负载。例如,在其 E 系列 GPU 中,Imagination Technologies 极大地改变了它在 ALU 管道中调度和执行工作负载的方式(见下面的图 5)。
“它曾经有一个非常复杂和非常深的管道,有许多管道阶段,并且管道延迟很长,”Imagination 技术洞察副总裁 Kristof Beets 说。“我们始终从非常大的寄存器存储中提供数据,在这些 GPU 中,这是一个非常大的 SRAM,大小为 0.5 MB,因此需要非常大量的非常紧密耦合的大内存。问题是,如果你在每个周期不断地从中获取大量数据,然后将其推入这个管道,并在每个周期中写出结果,那会消耗很多电量。
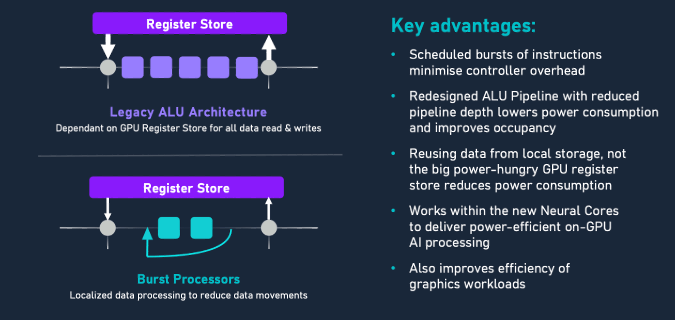
图 5:Burst 处理器减少了 GPU 内的数据移动。来源:Imagination
新设计使用了一个更轻量级的管道,只有两个管道阶段,并且它在本地重用了更多的数据。“与其不断访问真正的大型 SRAM,不如尝试重用我们附近已有的数据。这可以是以前的结果,也可以是我们旁边的管道中的数据,因为如果你看很多 AI 案例,你经常会通过一系列处理作对数据进行洗牌和涟漪,从邻近的管道中获取数据。
由此产生的每瓦每秒帧数效率提升可以转化为手机电池寿命的延长。Beets 说:“这可能会影响运营成本,但我们在移动领域可以做的其他有趣的事情之一是将节省的额外功耗转化为更高的时钟频率和更高的性能,因为我们可以保持在相同的功耗和散热预算内。
无论设计人员如何实现更好的性能,功耗仍然是一个关键问题。Ansys的Swinnen表示:“如今,每个人都对电源感兴趣,甚至包括数据中心人员,但移动设备的传统业务要长得多,而且它们由电池供电,因此它们更倾向于低功耗。
除了每天的电池寿命外,手机制造商还必须考虑电池寿命。手机的方方面面都会产生影响,包括 SIM 卡。为此,英飞凌开发了一款微型 28nm eSIM,其能耗比传统 SIM 卡低得多。eSIMS 允许用户在不同服务提供商之间轻松切换,而制造商可以在设计中更加灵活,因为不需要物理访问。
结论
手机供应商根据他们所针对的价格层以及他们现在或将来想要实现的 AI 功能和通信标准,采用不同的芯片设计方法。
Synopsys 的 Saar 指出,设计决策通常归结为业务原因。“这就像你问为什么一个特定的标准会流行起来,而不是一个可能在技术上更优越的标准。原因有很多,现在是这个还是那个并不重要。如果一家供应商控制着整个垂直链,他们就不必使用标准的现成虚拟制作 (VP) 摄像机接口或任何存储接口。他们可以创建自己的,即使它是劣质的。在他们看来,他们正在获得任何级别的好处,也许是在更高级别的集成和卓越运营中。
与此同时,许多市场新进入者正在这个竞争激烈的细分市场中开辟自己的道路。“他们以前只做手机。现在他们也在做 SoC,“Saar 说。“对他们来说,这是一个不同的故事。他们可以以不同的方式对其进行优化。他们不必走得更远,因为他们只关心他们的手机。他们只关心他们的用例。他们中的一些人在整个市场中拥有 AI 地位,而不仅仅是移动市场。我们正在进入绝对超越硬件的公司战略或世界战略。也许混合动力对他们来说确实有意义,因为我希望手机连接到我在云端的 AI 引擎,因为现在我有了差异化。您购买了我的手机,您连接到我的云,您连接到我的电子邮件。一般的 SoC 没有这个。他们在卖硬件。










评论