如何选择满足FPGA设计需求的工艺?

FPGA 逻辑架构实际上是大量经过复制的定制设计逻辑单元(LE)阵列——微小SRAM,复用器和寄存器,以及交换结构,覆盖了非常复杂的多层金属。因此,可编程架构的设计是要在LE实现多少功能以及单元需要多少互联之间达到很好的平衡。对于某一体系结构,架构的总密度对底层和中间金属层的层距非常敏感。但是,由于规划人员尝试使用互联堆叠下面所有的可用区域,因此,对于LE中晶体管的封装密度也非常敏感。用户在逻辑架构中实现的电路的速度和功效取决于晶体管特性,也与架构密度,互联RC产品和晶体管驱动电流有关。
因此,一般而言,能够提供较小金属层距以及封装更紧密的晶体管的工艺可以实现密度较高的逻辑架构,对于用户电路,性能更好,功耗更低。泄漏电流是逻辑架构的一个特殊问题,这是因为,芯片设计人员并不知道用户怎样使用可编程逻辑,他们使用电路级功耗管理技术来降低基于单元的设计的静态功耗,这种方法能力有限。
相反,基于单元的数字IP有关键通路,这些通路主要是通过本地短互联或者底层金属直接互相连接的快速晶体管。现代FPGA中的这一类结构包括数字信号处理(DSP)模块、I/O和存储器控制器、增强CPU内核,等等。这些IP模块的大小主要受仔细封装的标准单元库的密度的影响,以及库中各种单元的影响。在可编程架构中,用户可以开发需要的任何电路,而基于单元的硬核IP是预先定义好的,因此,芯片设计人员可以采用所有的功耗管理技术。这样,硬核数字IP将极大的受益于更小的工艺尺寸以及更高的晶体管速度,在系统层,可以使用功耗管理技术,调整平面FET较大的泄漏电流。
模块RAM是一类特殊的基于单元的IP。一般使用代工线提供的,经过手动优化的SRAM单元进行开发,但是,FPGA设计人员通常会调整阵列,在模块应用的范围内,优化速度、密度和功耗。由于模块非常灵活,因此,很难在FPGA RAM上实现功耗管理策略。FPGA中的其他结构可能不会对晶体管的所有特性变化敏感。
这些考虑意味着,某一系统应用FPGA的最佳工艺选择取决于系统设计对可编程架构和基于单元的逻辑的相对压力。对系统总体性能还有一定影响的是在架构中实现的模块的行为,28nm或者20nm工艺中端FPGA能够以较低的成本在较短的时间内实现所需要的系统性能。
最后,还有高性能模拟IP的问题,这些IP是目前锁相环(PLL)和串化器解串器(SerDes)电路的主要构成。这些设计并没有采用最小层距,相反,使用了各种尺寸的晶体管、电路布局和金属层间距,这些通常涉及到了手动布局。它们对于晶体管的电气行为非常敏感,包括,数字工程师不太关心的一些参数。数字设计人员仿真逻辑功能,模拟设计人员仿真晶体管。对于模拟设计人员,另一个绝对关键的问题是一致性:很多标准电路依靠密切匹配的成对的晶体管来实现。
在 finFET上还有一些争论。某些模拟设计人员指出,您不能为FinFET选择任意宽度。由于晶体管是竖立在侧面,意味着是在纵向测量宽度,因此,它们必须有相同的宽度。您可以使用一个最小宽度的FinFET,或者,您希望电流更大,可以将几个并联起来使用。这些设计人员担心,模拟设计人员很难甚至无法在其熟悉的电路拓扑中使用这些新晶体管。
但是,其他有经验的模拟设计人员指出,更高的速度、更强的沟道控制,以及,特别是 FinFET更好的一致性,对于模拟设计都非常有利,远远抵消了晶体管宽度的量化问题。争论还在继续,而Intel在CPU中模拟结构上的工作表明,它们使用其22nm三栅极工艺开发了这一结构,三栅极晶体管极大的提高了高精度模拟设计的性能。
采用合适的工艺开始定制
工艺特性以不同的方式影响FPGA的不同结构。相似地,不同的应用对这些 FPGA结构有不同的要求。结果,在一定时期内,没有一种工艺技术能够为多种应用提供最合适的平台。计划、成本和性能要求促使FPGA中的某些结构采用混合定制方法来实现,以满足FPGA设计对多种工艺选择的要求。
三个例子可以说明这一点。首先,考虑一个单芯片电机控制 SoC(图3)。芯片接收来自四个电机的连杆传感器位置数据,都是较高的kHz速率,以较低的MHz速率驱动四个驱动电路板。它连接至中速DDR2 DRAM,进行编码和数据存储,连接至工业以太网,将SoC连接至工厂车间控制网络。
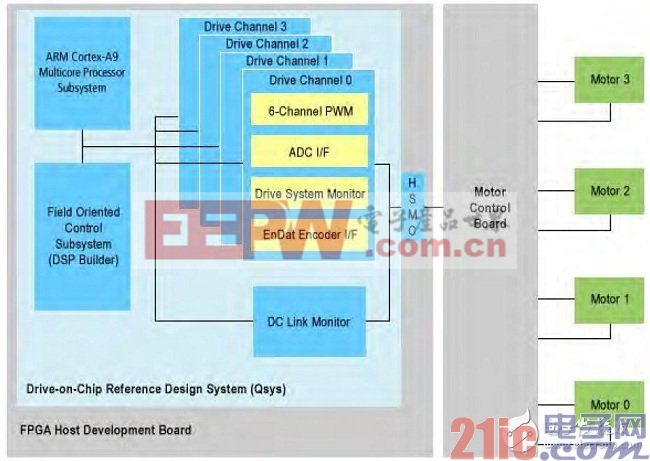
图3.单芯片多轴电机控制器结合了基于单元的DSP电路来计算FOC算法,可编程逻辑对I/O信号进行编码和解码,CPU用于管理和功能安全算法。
芯片实际上支持两项主要任务。第一项是在FPGA DSP模块中进行计算的现场定位控制(FOC)算法,实际上是每一电机大量的矩阵算术。可编程架构中的I/O电路以相对较低的速率和功耗,对位置数据进行解码,对信号进行编码,以便驱动电路板。第二项任务是功能安全封装,一组设计用于保护机器运行以及设备完整性的功能,运行在SoC FPGA的嵌入式ARM Cortex-A9 CPU上。
这一设计有两个很大的难点。第一,客户希望不断提高能效和精度,降低噪声,这些都要求更大的带宽,更复杂的算法,进行FOC计算。因此,应用程序要求使用硬核DSP模块和RAM。第二,成本问题,这个问题更严重。
对形势进行分析,这一应用最关键的FPGA结构是硬核IP模块、模块RAM,以及随着功能安全要求的提高,还有CPU内核。这些模块相应地要求半导体工艺良好的标准单元库,合适的SRAM以及尽可能低的价格。现在,Altera的Cyclone V SoC产品采用了TSMC的28低功耗(28LP)工艺,很好的结合了高性能硬核IP和存储器,降低了成本,可以及时供货。
帮助驾驶员开车
第二个例子是下一代汽车辅助驾驶系统(ADAS)设计。这一SoC接收来自汽车雷达和几个HD视频摄像机的数据,使用图像处理例程和人工智能(AI)算法算出车辆的位置,驱动两个实时显示屏,向车辆控制模块发送命令,进行换挡、刹车和传动系统控制。大部分I/O数据流会通过一对冗余的10G以太网端口。由于严格的推出计划,必须在2013年年中开始系统体系结构设计。
这一系统中的难点是进行大量的视频和雷达信号处理,识别目标,满足分类和AI例程的计算需求,以及大量的本地和外部宽带存储器的需求。这些需求主要依靠可编程架构来满足,使用了DSP硬核IP、模块RAM和外部 DRAM。由于计算负载是偶发的,车辆没有移动或者慢速行驶时,计算很少,而计算强度基于环境的复杂度,因此,需要很好地进行功耗管理。这类FPGA需要金属层距和晶体管性能优于目前中端FPGA的工艺,以便满足可编程架构和硬核IP的性能目标。但是,设计最初并不需要FinFET那样的速度和功耗。 Altera的20nm产品系列基于TSMC的20nm芯片系统(20SoC)平面工艺,很好的同时实现了带宽、计算性能和可用性。
最后,让我们进一步了解一下近期会怎样。新一代数据中心将不仅仅包括高密度服务器类CPU芯片簇,而且还有大容量的高速FPGA。这些FPGA以及CPU和共享高速缓存将位于超高速本地网中,用作虚拟的动态重新配置网络数据包引擎和计算加速器。
这类芯片要求很高的晶体管密度和金属层距,提高芯片的容量和带宽,特别是,考虑到服务器机架严格的散热和功耗限制以及较高的占空比,这些都限制了动态功耗管理的效率,因此,功耗性能点超出了任何建议的平面晶体管的能力范围。此外,为能够连接超高速数据网络,以支持外部存储器极大的带宽,这些FPGA需要的集成模拟电路性能水平超出了目前针对FPGA所讨论的电路性能。这些应用促使Altera选择了Intel的14nm三栅极工艺。
结论
本文介绍了三种场景,每一种都结合了硬核IP应用、可编程架构应用、存储器带宽,以及I/O带宽,很好地满足了不同半导体工艺的要求。这一工艺实际上就是 Altera的定制方法:每一类应用的FPGA性能、余量、计划和成本都能够满足系统要求。最好的选择给系统开发人员带来了明显的优势。








评论