基于DSP的语音识别计算器设计

TLV320AIC23是Tl公司的一款低成本、低功耗的音频编解码器(CODEC),在本系统中负责采集语音信号。它与本系统相关的性能参数有:支持8~96 kHz可调采样率;可调1~5dB的完整缓存放大系统等。图4是TLV320AIC23的电路图。本文引用地址:https://www.eepw.com.cn/article/166656.htm

AM29LV800B存储器又称闪存(Flash),它具有在线电擦写、低功耗、大容量等特点,其存储容量为8Mbit。上电后,DSP从外部Flash加载并执行程序代码,使系统能够脱机运行。在本系统中,它主要用来存储程序代码、语音模型、以及压缩后的语音数据。
HY57V641620同步动态存储器(SDRAM),容量为4 M×16 bit。作为RAM的扩展,它大大增强了DSP的存储与运算能力。在系统初始化的时候,用来装载放在Flash中的声学模型。这样在语音识别的过程中可以通过片外的SDRAM来访问声学模型,比直接访问Flash来获取声学模型数据要快。LCD显示器用来实时显示经过语音识别后的数字、运算符号,并在得到需要显示最终结果的提示后显示答案。
2 系统软件设计
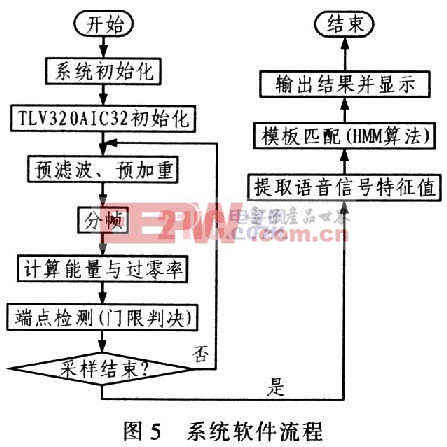
2.1 系统软件流程
图5为系统的软件流程。整个系统开始运行后,初始化DSP及TLV320AIC23,以使各个寄存器的初值符合要求。在系统通过TLV320AIC23采集语音信号后,首先要进行预滤波和预加重;接着将语音信号进行分帧;然后计算每帧信号的短时能量与短时平均过零率,为接下来的门限判决提供依据;利用门限判决进行端点检测后,提取每帧的Mel倒谱参数(MFCC),作为该帧信号的特征值;最后,用处理后的语音信号的特征值与模板进行匹配,这一部分是系统的重点。以相似度最大的模板锁对应的语音信号为识别结果。根据识别的结果在显示器上显示数字和运算符号,由运算规则得出结果并显示。
2.2 前处理
前处理是对语音信号采样、A/D转换、预滤波和预加重、分帧等。以8 kHz和16位的采样频率采集的语音模拟信号。本系统使用带通滤波器来滤波,上截频率为3.4 kHz。下截频率为60 Hz。由于语音信号具有极强的相关性,因此,分帧时要考虑帧重复的问题。本文将语音信号以256个采样点为一帧,两顿之间的重复点数为80,通过一个一阶的滤波器H(z)=1-a/z对采集的信号进行处理。
端点检测就是从说话人的语音命令中,检测出孤立词的语音开始和结束的始点。端点检测是语音识别过程的一个重要环节,只有将孤立词从说话人的背景噪声中分割出来,才能够进一步进行语音识别工作。本文采用短时能量和过零率检测端点。语音信号的短时能量分析给出了反应其幅度变化的一个合适描述方法。
短时过零率,即指每帧内信号通过零值的次数,能够在一定程度上反映信号的频谱特性。一帧语音信号内短时平均过零率定义为:

用短时能量参数检测结束点,信号{x(n)}的短时能量定义为:

式中,{x(n)}为输入信号序列。
在正式端点检测开始后,短时能量与短时过零率作为门限来判决说话人命令字的开始与结束;连续5帧语音信号超过门限值视为说话人命令字的开始,连续8帧语音信号低于门限值视为说话人命令字的结束。
2.3 特征值提取
提取每帧的Mel倒谱参数(MFCC)为该帧信号的特征值。由倒谱特征是用于说话人个性特征和说话人识别的最有效的特征之一,它是基于人耳模型而提出的。其提取过程如下:
1)原始语音信号S(n)经过预加重、加窗等处理,得到每个语音帧的时域信号x(n)。然后经过离散傅里叶变换(DFT)后得到离散频谱X(k)。

式中,N表示傅里叶变换的点数。










评论