基于TMS320DM6446的H.264编码器的设计与优化

1 编码器C语言结构调整
PC平台上用C语言实现的编码器在DSP平台上的编码帧率(fps)非常低,平均2s才能编完一帧,其主要原因是无法利用DSP的并行处理机制。因此针对C64x+的特点,将程序中对流水线操作影响较大的循环拆分成若干小循环实现。对编码器运行速度影响较大的模块,如sad的计算,DCT变换等采用CCS自带的图像库以提高编码效率。本文引用地址:https://www.eepw.com.cn/article/150985.htm
2 DSP端的内存配置
由于视频编码的数据存取量较大,而 DAVINCI_EVM提供了256M的外部存储器DDR2,因此通过对DSP/BIOS的设置将外部存储器设置为DDR2,并将可执行的C代码及C代码的堆存入外部存储器中。
3 对DSP端BOOT的设置
由于TM320DM6446采用双核的设计,ARM端只负责整个工程的控制而不参与编码算法的具体实现。为了保证编码算法能在DSP端无中断的全速运行,需要对ARM端进行屏蔽,并通过对DAVINCI_EVM跳线的设置使DSP端自BOOT。
通过以上步骤,编码器效率虽然有所提高,但仍无法满足实时性的要求,因此必须结合DM6446本身的特点对编码器算法进行进一步的优化。
编码器的优化
本文对H.264算法的优化主要有两个方面:1)对算法中耗时较多的运动估计模块进行优化;2)对DSP的数据搬移进行优化。
1 对编码器算法运动估计模块的优化
由于DSP硬件资源有限,因此有必要对H.264编码器中所耗时间较多的模块进行优化,表1为H.264各模块复杂度比较。
由表1可见,运动估计占了一半左右的时间。运动估计复杂度高的主要原因是采用了全搜索算法,虽然精度非常高,但带来了大量的计算量。针对这一问题,本设计在已有的菱形搜索算法基础上进行进一步的优化。
为了减少静止宏块被编码以及大模板搜索所带来的运算量,在用菱形算法进行运动搜索之前,以待编码宏块周围已编码宏块的运动矢量信息及SKIP状况为依据预测当前宏块是否使用SKIP模式编码。当待编码宏块为非静止宏块时,再根据周围已编码宏块的SAD值预测当前宏块的运动剧烈程度,若是运动平缓的宏块则直接使用小模板进行搜索。只有当待编码宏块被判定为剧烈运动的宏块时才进行大模板搜索。由于多次的大模板搜索循环带来较大的计算量,因此在进行大模板搜索之前首先根据周围宏块的信息对最大搜索次数MaxNum进行预估值。当大模板的搜索次数大于MaxNum时直接跳转至小模板搜索。此流程设计可使静止宏块和运动平缓的宏块不进入运算量大的大模板搜索环节。优化后的菱形算法流程如图3所示。
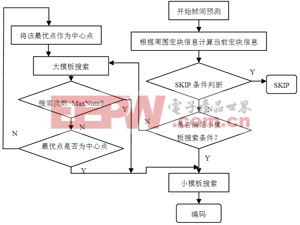
图3 优化算法流程图

霍尔传感器相关文章:霍尔传感器工作原理
电度表相关文章:电度表原理
霍尔传感器相关文章:霍尔传感器原理![[Android开发视频教学]Service初步(一)(25)](http://editerupload.eepw.com.cn/201010/05b93eb1aa2ceec6e832bde35b0fb602.jpg)
![[Android开发视频教学]广播机制(二)(22)](http://editerupload.eepw.com.cn/201010/3d5d8c2910a15f174a8a3d7d21969de5.jpg)

![[Android开发视频教学]Socket编程(24)](http://editerupload.eepw.com.cn/201010/0c10ea6d4e0e8ee4f3593b458d89cb55.jpg)

![[Android开发视频教学]项目功能分析(27)](http://editerupload.eepw.com.cn/201010/38f308c51f3a4f0222dfa9d4764cd2dd.jpg)
![[Android开发视频教学]WIFI网络操作(23)](http://editerupload.eepw.com.cn/201010/a57e500f8313fec2b17f4827fc6a3d84.jpg)
评论