32位内核与基于微控制器存储架构的集成

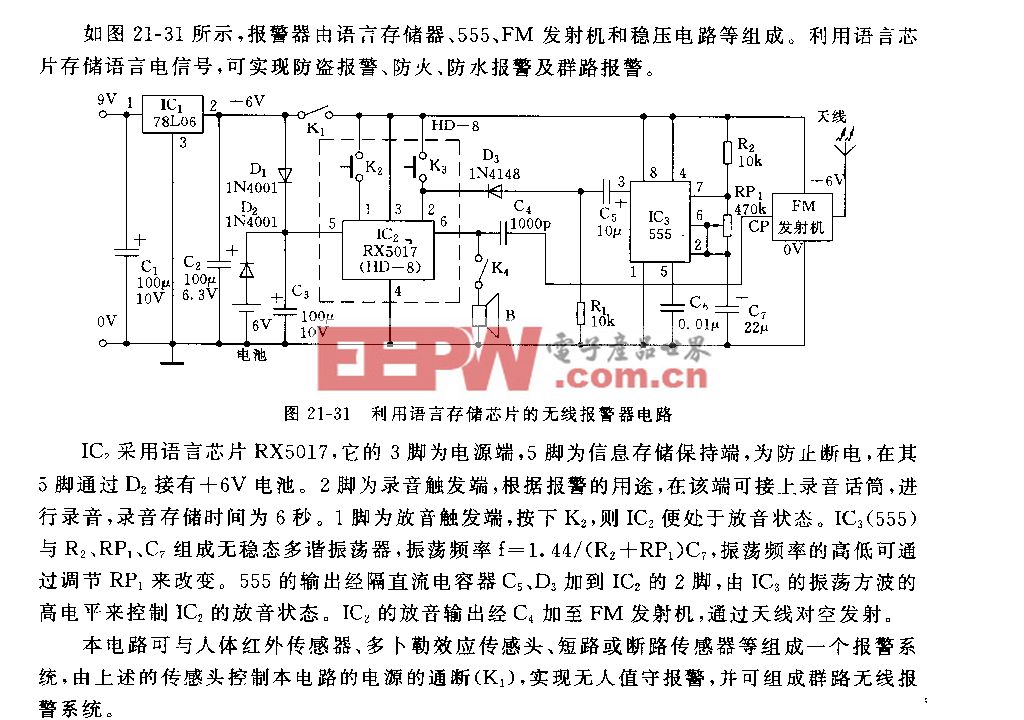
图 2.2 显示了一个简单的有 8 块、单路的高速缓存设计,1 块有 16 个字节。虽然这么小的高速缓存很难实现,但它对指令执行很有用。在这种情况下,地址标记将是整个地址的高 12 位,而索引将是寻址高速缓存块内的特定条目的余下的两位。
与指令预取缓冲器相比,指令高速缓存系统具有更复杂的地址比较系统,因为该高速缓存阵列不仅包括每个高速缓存块的连续寻址指令,而且可以将指令地址空间的任何区域包含在高速缓存块内。
为了让高速缓存更有效地工作,在闪存器件和指令高速缓存之间应当实现尽量宽的数据通道,保证内核能够以最快的速度执行程序指令。指令高速缓存在与闪存器件的接口上实现了一个指令预取机制来解决这个问题。否则,闪存存取时间的问题就会影响内核执行速度。
在正常执行过程中,所需的指令地址高位和高速缓存阵列的指令标记间开始一连串的比较。如果找到匹配的地址,高速缓存命中即被寄存,指令地址的低位将被用于高速缓存块内的索引,以找回所需的指令。如果没有发现匹配的地址,就是我们所说的高速缓存不命中。高速缓存不命中将导致高速缓存控制器从存储区的特定区域读入包含所需指令的缓存块。被替代的高速缓存块通常是阵列中最旧的高速缓存块。
当使用高速缓存时,基本性能分析变得更加复杂,因为这时高速缓存不命中数在方程里引入了一个新的变量。分析典型应用代码可帮助芯片设计人员确定高速缓存大小和实际性能增益的最佳平衡。
对于我们的设计,假定 CPI 将在以下范围内是比较合理的:
= CPI (cache) = 2.0
在高速缓存大得足够存储大多数应用主程序的情况下,性能增益可能非常显著,因为系统正在接近 0 等待状态执行环境。
采用改良的哈佛架构(Modified Harvard Architecture)设计的指令高速缓存的一个重要优势是高速缓存无需执行回写操作。与数据高速缓存相比,这种实现要简单的多,数据缓存还要保证改动过的高速缓存数据正确地存储进主数据存储器。
改进的设计
我们现在可以把学到的知识应用于我们系统的第一个框图,并从预取/指令高速缓存缓冲器系统提供的增益中获益。详见以下的图 3。

与之前的16位设计相比,新设计能够以三倍的速度(120 MHz / 2.0 CPI(预取)/ 20 MHz(16 位时钟)执行指令,通过适当选择最终指令高速缓存的大小,很容易就能实现非常接近单等待状态闪存系统运行的性能。
虽然指令预取缓冲器是一种简单的实现,但它通过屏蔽闪存和 32 位内核执行速度之间的存取时间差异,显著地改善了系统吞吐量。预取缓冲器是一个非常简单的设计,只需要很少的额外逻辑。大部分额外逻辑与扩展闪存系统和预取缓冲存储器之间的通道有关。设计的简单有利于它完全透明地展示给软件程序员,他们只需允许或禁用该功能就可以了。
形式指令高速缓存是一种更复杂的解决方案,需要至少与预取缓冲器相同数量的额外逻辑电路,以及管理指令高速缓存正常运行的额外逻辑电路。设计人员需要分析 MCU 运行的典型应用,以确定能够最好地平衡性能和成本的高速缓存大小。当然,指令高速缓存部署更为昂贵,但是在许多情况下,系统实现的性能可达到 0 等待状态系统,对性能产生显著的积极作用。软件程序员还必须了解与指令高速缓存有关的一些基本控制和维护问题,但是在大多数情况下,它们可以一劳永逸地运行,只是在系统初始化时才需要执行。
只用新的 32 位器件直接替代现有的 8 位或 16 位内核是不够的。芯片设计人员还必须调整和改进整个 MCU 设计,以适应高性能、高速度 32 位内核的新要求。我们需要这样的调整来确保新的 32 位内核能够释放最高性能。采用预取缓冲器和指令高速缓存是改进微控制器设计的两个直接途径,微控制器与 32 位内核和现有存储器技术直接相关。








评论