32位内核与基于微控制器存储架构的集成

32 位 MCU 性能差异
微控制器(MCU)领域如今仍由 8 位和 16 位器件控制,但随着更高性能的 32 位处理器开始在 MCU 市场创造巨大收益,在系统设计方面,芯片架构师面临着 PC 设计人员早在十年前便遇到的挑战。尽管新内核在速度和性能方面都在不断提高,一些关键支持技术却没有跟上发展的步伐,从而导致了严重的性能瓶颈。
很多 MCU 完全依赖于两种类型的内部存储器件。适量的 SRAM 可提供数据存储所需的空间,而 NOR 闪存可提供指令及固定数据的空间。
在新 32 位内核的尺寸和运行速度方面,嵌入式 SRAM 技术正在保持同步。成熟的 SRAM 技术在 100MHz 的运行范围更易于实现。对 MCU 所需的典型 RAM 容量来说,这个速度级别也更具成本效益。
但是标准的 NOR 闪存却落在了基本 32 位内核时钟速度之后,几乎相差一个数量级。当前的嵌入式 NOR 闪存技术的存取时间基本为 50ns (20 MHz)。这在闪存器件和内核间转移数据的能力方面造成了真正的瓶颈,因为很多时钟周期可能浪费在等待闪存找回特定指令上。
标准MCU 执行模型——XIP (eXecute In Place)更加剧了处理器内核速度和闪存存取时间之间的性能差距。
大容量存储中的应用容错及 SRAM较高的成本是选择直接从闪存执行的两个主要原因。存储在闪存内的程序基本不会被系统内的随机错误破坏,如电源轨故障。利用闪存直接执行还无需为MCU器件提供足够的 SRAM,来将应用从一个 ROM 或闪存器件复制至目标 RAM 执行空间。
消除差距
理想的情况是,改进闪存技术,以匹配32位内核的性能。虽然当前的技术有一定的局限,仍有一些有效的方法,可帮助架构师解决性能瓶颈问题。
简单的指令预取缓冲器和指令高速缓存系统在32位MCU设计中的采用,将大大提高MCU的性能。下面将介绍系统架构师如何利用这些技术将16位的MCU架构升级至32位内核CPU。
在 MCU 设计中引入 32位内核
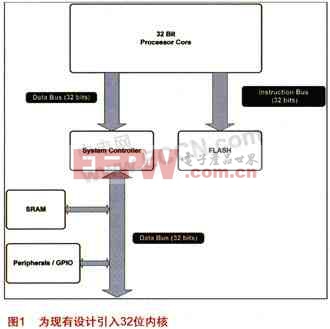
图 1 介绍了将现有16位设计升级至基本32位内核的情况,显示了新32 位内核及其基本外设集合之间的基本联系。由于我们在讨论将新的32位处理器内核集成至新的 MCU 设计,我们假设可采用新32位内核采用以下规范。
32 位内核——改良的哈佛架构
与很多 MCU 一样,新的 32位 内核也采用改良的哈佛架构。因此,程序存储和数据存储空间是在两个独立的总线构架上执行。一个纯哈佛设计可防止数据在程序存储空间被读取,该内核改良的哈佛架构设计仍可实现这样的操作,同时,该32位内核设计还可实现程序指令在数据存储空间的执行。
在标准总线周期内,程序和数据存储器接口允许插入等待状态,有助于响应速度缓慢的存储或存储映射器件。
32位内核——工作频率
新内核的最高工作时钟频率为120MHz,是被替代的16位内核速度的六倍。
32位内核——指令存储器接口
指令存储系统接口有一个32位宽的数据总线,以及一个总共地址空间为1MB的20位宽的地址总线。尽管 32位内核具备更大的地址空间,而这足够满足这个MCU的目标应用空间。标准的控制信号同样具备为缓慢的存储器件插入等待状态的能力。
该设计的闪存器件与16位设计采用的技术一样,最高运行速度达20 MHz。
32 位内核——数据存储器接口
系统 SRAM 和存储器映射外设都通过系统控制器与处理器数据总线相连。系统控制器可提供额外的地址解码及其他控制功能,帮助处理器内核正确访问数据存储器或存储器映射外设,而无需处理特定的等待状态、不同的数据宽度或每个映射到数据存储空间的器件的其他特殊需求。
系统控制器和处理器内核之间的数据总线为 32 位宽,与系统控制器和SRAM 间的数据总线宽度相同。系统控制器和外设以及 GPIO 端口间的数据总线宽度可为 8 位、16 位或 32 位,视需求而定。
目标设计采用的 SRAM 与 16 位设计采用的类型相同,在 120 MHz时可实现 0 等待状态操作。
初步分析
目前系统的性能由几个因素控制。处理器内核与闪存器件速度的差异可极大地影响性能,因为至少有五个等待状态必须添加到每个指令提取中。根据粗粒经验法则,至少每十个指令有一个读取或存储。每条指令加权平均周期(CPI)的典型顺序为:
CPI = (9 inst * 6 闪存周期 + 1 inst *1 SRAM周期) / 10 指令
CPI = 5.5
内核的吞吐量由闪存接口的速度决定,因此以前所有的32位内核都是数据通道宽度的两倍。
在这种情况下,SRAM接口无关紧要。虽然某些问题很有可能源于存储接口方面,如中断延迟和原子位处理,SRAM存储器的零等待状态操作可以忽略。关注的重点是通过采用目前可用的、具有成本效益的技术,来提高指令存储接口的性能。
提高CPU内核性能——闪存接口
来自高性能计算环境的一个通用概念是高速缓存,在主要存储器件和处理器内核之间采用更小及更快的内存存储,可以实现突发数据或程序指令的更快访问。
设计和实现高速缓存可能非常复杂——需要考虑高速缓存标记、N-Way级联和普通高速缓存控制等问题——仅关注程序指令存储器可让这项工作变得非常简单。这是因为对此特定的 32 位内核来说,对程序存储器的访问是一个严格的只读操作。在这种情况下,我们只需考虑一个方向的数据流可以减少缓冲器和高速缓存系统的复杂性。
预取缓冲器
增加闪存接口总体带宽的一个简单方法是扩展处理器和闪存器件间的通道宽度。假定闪存的速度一定,增加带宽的另外一个方法是扩展接口宽度,以实现一次提取更多指令,创造一个更为快速的闪存接口外观。
这是预取缓冲器的一个基本前提。它利用了连接闪存的更宽接口的优势,可在同样的时钟周期数内读取更大的数据量,这通常只要花闪存读一个字的时间。
因此,预取缓冲器还定义了新数据通道的最小尺寸,原因显而易见。

图2.1显示了我们的120 MHz内核连接到20 MHz闪存阵列的情况。采用两个系统间的速度比作为起始值,我们可以确定预取缓冲器、闪存接口读取的宽度,假设我们需要在无需等待状态的情况下读取指令。
在这种情况下,预取/闪存数据通道将是:
(120/20)X32位=192位宽
预取缓冲器控制逻辑不断对存取缓冲器的读取数进行标记。最后一次存取后,它将使下一个周期从闪存重新加载整个缓冲器。
预取缓冲器控制逻辑还可识别缓冲器每次进入的有效地址。它还将提供适当的解码,根据正确的顺序指令显示处理器数据总线,当一个执行分支需要完整的新的顺序指令时,将重新加载缓冲器。
当然,在提取新的指令时,分支将造成一些额外的延迟。但是由于相比处理器内核,预取缓冲器实现六合一方法在数据通道宽度方面具有绝对的优势,为该分支问题的最终平衡的结果付出的代价是值得的。
更多经验法则分析都显示,一个典型的嵌入式应用有20%发生分支的机会,每五个周期相当于一个分支。采用之前的方法,CPI值现在为:
CPI = (4指令*1周期+1指令*6周期)/5指令
CPI = 2.0
我们已经看到利用基本实现方法,整个系统周期效率有了大幅提高。
图2.1还显示了一个更为现实解决方案方法,即将六个独立的闪存系统的32位总线加在一起,而不是重新设计一个新的、极宽的数据总线闪存系统。预取缓冲器控制逻辑将自动创建六个连续的程序地址,然后允许一个正常的读取周期同时访问所有六个组。在读取周期的末尾,预取缓冲器现在可保持六个新的指令,而非一个,模拟的零等待状态系统。
指令高速缓存
形式指令高速缓存赋予预








评论