Cortex - M3与Cortex - M4对比

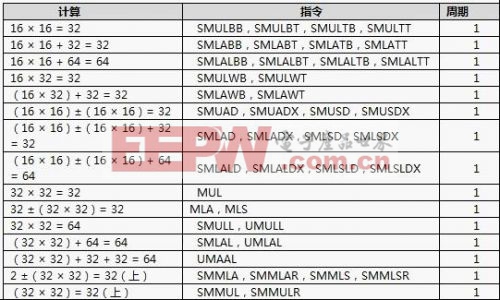
1).32位乘法累加(MAC)
32位乘法累加(MAC)包括新的指令集和针对Cortex-M4硬件执行单元的优化它是能够在单周期内完成一个32×32+64->64的操作或两个16×16的操作。如下表列出了这个单元的计算能力。
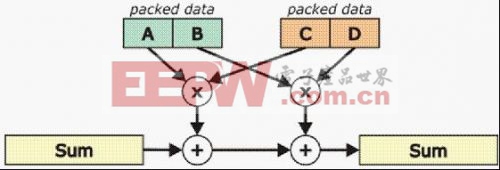
2).SIMD
Cortex-M4支持SIMD指令集,这在上一代的Cortex-M系列是不可用的。上述表中的指令,有的属于SIMD指令。与硬件乘法器一起工作(MAC),使所有这些指令都能在单个周期内执行。受益于SIMD指令的支持,Cortex-M4处理器是能在单周期完成高达32×32+64->64的运算,为其他任务释放处理器的带宽,而不是被乘法和加法消耗运算资源。考虑以下复杂的算术运算,其中两个16×16乘法加上一个32位加法,被编译成由一个单一指令执行:SUM=SUM+(A*C)+(B*D)
3).FPU
FPU是Cortex-M4浮点运算的可选单元。因此它是一个专用于浮点任务的单元。这个单元通过硬件提升性能,能处理单精度浮点运算,并与IEEE754标准兼容。这完成了ARMv7-M架构单精度变量的浮点扩展。FPU扩展了寄存器的程序模型与包含32个单精度寄存器的寄存器文件。这些可以被看作是:
- 16个64位双字寄存器,D0-D15
- 32个32位单字寄存器,S0-S31该FPU提供了三种模式运作,以适应各种应用
- 全兼容模式(在全兼容模式,FPU处理所有的操作都遵循IEEE754的硬件标准)
- Flush-to-zero冲洗到零模式(设置FZ位浮点状态和控制寄存器FPSCR[24]到flush-to-zero模式。在此模式下,FPU在运算中将所有不正常的输入操作数的算术CDP操作当做0.除了当从零操作数的结果是合适的情况。VABS,VNEG,VMOV不会被当做算术CDP的运算,而且不受flush-to-zero模式影响。结果是微小的,就像在IEEE754标准的描述的那样,在目标精度增加的幅度小于四舍五入后最低正常值,被零取代。IDC的标志位,FPSCR[7],表示当输入Flush时变化。UFC标志位,FPSCR[3],表示当Flush结束时变化)
- 默认的NaN模式(DN位的设置,FPSCR[25],会进入NaN的默认模式。在这种模式下,如对任何算术数据处理操作的结果,涉及一个输入NaN,或产生一个NaN结果,会返回默认的NaN。仅当VABS,VNEG,VMOV运算时,分数位增加保持。所有其他的CDP运算会忽略所有输入NaN的小数位的信息)
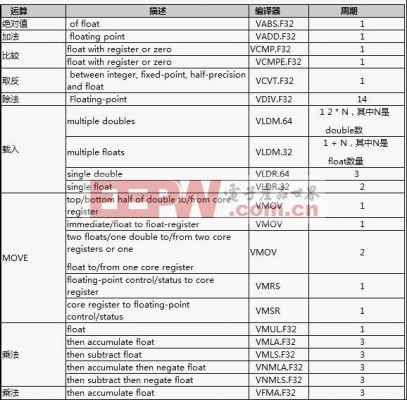
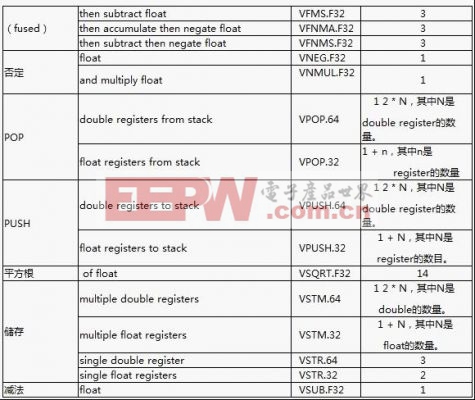
下表显示的是FPU指令集
3.debug调试
与Cortex-M3的相同,Cortex-M4的设备是通过标准JTAG或串行线调试连接器调试。要连接到主机的接口,一个简单,标准化外部连接器是必要的。

pid控制相关文章:pid控制原理





评论