学贯中西(14):人机协同决策(续)

1 三种类型的AI
过去20 年,AI 在辨识( 分类) 和预测,两方面表现令人类惊奇。就像算命仙,辨识出您的本命、预测出您的“时和运”了。若时来运转,就努力扩大行动,趋吉迎福。若时运不济,就凡事小心慎行,冬藏春迎,蓄锐待发。这阶段的AI,通称为:识别型AI。
在大数据时代里,人眼可看、手中能掌握的资料很有限,且视野小,人为优化只能获得局部最优解(Local optimum)。于是,就需要AI 生成来帮忙,以人为找出的局部最佳解为条件( 基础),输入给AI ( 如Conditional GAN 模型), 让它协助生成全局最佳解(Global optimum)。这阶段的AI,通称为:生成型AI。
上一期里,曾经谈到了AI 能够帮助检验人类决策者的假设,降低决策风险,促进企业的成长茁壮。于是,AI 有3 种:识别型AI、生成型AI、决策型AI。
● 识别型AI:对事物或现象,洞察其特征(Feature),而进行归类( 识别)。
● 生成型AI:学习目标事物或现象的数据分布(Distribution),生成新数据,呈现逼真的事物。
● 决策型AI:由< 生成型AI> 提供方案,由< 识别型AI> 评估风险,然后挑选风险最低、胜率最高的方案,并采取行动。所以决策型AI 的关键因子是:风险。
2 决策型AI的3项特点
从商业决策而观之,商业环境是善变的,而且存在竞争者刻意唱反调,使得看似最佳获利方案,却可能是最赔钱的。于是,决策型AI 的第1 项特点是:需要把环境或敌方的可能方案(的特征)输入到AI模型里。
《孙子兵法》说:胜兵先胜而后求战;败兵先战而后求胜。于是,决策型AI 的第2 项特点是:帮忙做“先胜”的评估,也就是“不败”的评估,也就是评估风险。
例如,当今股市领域,最著名的投资决策者是巴菲特。他说,他的投资决策都基于两条原则,第1 条原则是不赔钱( 先不败、先胜);而第2 条原则是永远不忘记。
从成吉思汗与神鹰的故事,可协助我们领会到,如果决策型AI 扮演神鹰的角色,既符合AI 的特性,又非常具有价值。当AI( 神鹰) 发现决策者思绪不够完美时,可以给予画龙点睛的效果。更具价值在于:当AI( 神鹰)发现决策者的决定是错的,而且行动是灾难性的,AI立即提出严重警告。于是,决策型AI 的第3 项特点是:把“决策型AI”做在决策点与行动点之间。例如,成吉思汗拿着杯子去盛装那滴下来的山泉水。
装满了水,快拿到口边,准备一饮而尽时,在天空中飞翔的神鹰突然飞扑下来,“嗖”的一声,就把成吉思汗手中的杯子踢翻了,水都洒到地上了。
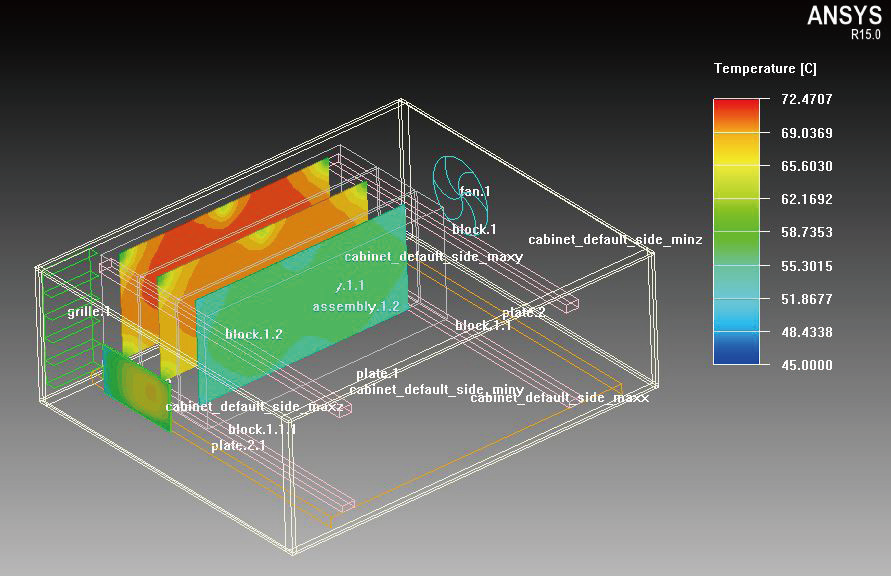
神鹰在决策者的“决策时间点”与“行动时间点”之间的数秒钟内,实时纳入当下的决策,做出智慧的推论,采取保护主人的行动,而且刻不容缓( 图1)。

图1
过去,许多人把AI 做到“决策时间点”之前,提供给决策者参考,是OK 的,只是这样的作法,只是把AI 做成为BI ( 商业智能) 或大数据分析的延伸,其价值并非最高的。把AI 做在策者的“决策时间点”与“行动时间点”之间,我称为:AI 神鹰。把AI 做在策者的“决策时间点”之前,我称为:AI 猎狗。
AI 猎狗作用于人类的“决策前”;而AI 神鹰作用于“决策后”。这两项AI 成为人类决策者的最佳伙伴。对于基层经理人( 决策) 而言,AI 猎狗可以发挥很大的辅助效果。对于高层总裁( 决策) 而言,AI 神鹰可以发挥关键性的效益。所以成吉思汗出行时,随身携带神鹰,而不是猎狗。猎狗看利益,神鹰看风险。两者协同合作,带给人类趋吉避凶效果,让企业势如破竹。如成吉思汗一般,建立地球史上最大版图的帝国。AI 天生具有“考古”和当下“探索”的强大能力。也就是AI 出生就具有猎狗的天份,能极灵敏地嗅出利益机会( 如那里有兔子)。也就是一般统称的“预测(Predict)”能力,这种极灵敏能力既可以用来嗅出“利益”,也可以用来嗅出“危险”。于是,将一群擅于嗅出风险的AI 猎狗们,巧妙组合成为一个团队,就成为一只“AI 神鹰”了。
3 以划拳比赛为例
这是一个做给小学生玩的AI 游戏,让小朋友与Zenbo 机器人玩剪刀、石头、布的划拳比赛( 图2 和图3)。

图2

图3
比赛一开始,请先开启Zenbo 的“AI 划拳游戏”,如图4。Zenbo 会说出:“我们一起来玩剪刀、石头、布。当我喊‘剪刀、石头、布’,我们就同时出拳喔,准备好了吗?”。请您回答:“好了”。Zenbo 就出现下述画面( 图5),同时Zenbo 也说出:“开始出拳喔,剪刀、石头、布”。

图4

图5
这时请您出拳,要用口说出来。例如说出:“布”。此刻Zenbo 先已决定它的出拳,瞬间已听到您说出的话(布),就显示出来。

图6
同时,Zenbo 就很高兴地说出:“哈哈哈,我赢了”。然后继续下一回合的比赛。
4 AI模型的架构设计
我们共有3 个模型:RnnPredict、DecisionRiskModel、VoiceClassifier。第1 个模型(RnnPredict) 是基于RNN的模型,它从比赛的历史数据中,探索对方出拳的规律(图7)。

图7
第2个模型(DecisionRiskModel) 是基于对方出拳的规律,加上己方的决策,进行风险(Risk) 评估,如图8。

图8
第3个模型(VoiceClassifier) 是监视、辨别对方当下出拳的行为,而计算出胜负( 图9)。

图9
在这划拳游戏里,AI 必须在看到对方出拳之前,预先作最好的决策。所以第2 个模型的运行时间,是比第3 个模型还要早。这第2 个模型是依赖第1 个模型所探索的到的对方出拳规律。
5 AI模型的学习(训练)流程
5.1 训练RnnPredict模型
这RnnPredict 模型会从比赛的经验中找出对手的出拳规律。例如,当A 与您比赛100 回合,它会记录比赛的过程。
RnnPredict 模型会观察您出拳的各种习惯性。例如,它会从这100 次的出拳纪录( 数据) 中萃取您连续出拳相同时,接着您会习惯性选择出什么拳呢? 于是,它萃取出来了( 图10)。

图10
接着,按下“AI 寻找规律”,RnnPredict 模型就展开机器学习,并且以神经网络的权重来记录它找出来的规律,然后他也输出所找到的规律( 图11)。

图11
从上图里AI 输出的结果看来,AI 的确发现了您的出拳习惯:几乎没有连续3 次出一样的拳。例如,从上图的第1 列,您前两次都出“石头”,AI 就估算出您这次将出拳的可能性是:出“布”、“剪刀”、“石头”的可能性,分别为(0.75,0.25,0)。
5.2 训练DecisionRiskModel模型
这是一个分类模型( 属于识别型AI)。刚才AI 基于过往的大数据,发现1 个规律:您连续两回合出招一样时,其后( 第3 招) 出招,几乎不会与前两回相同。例如,前两回合,您都出“剪刀”,这一回合,您几乎不会继续出“剪刀”。所以,您只会出“石头”或“布”了。此时,如果AI 出石头,就它就稳输了( 风险高);反之如果AI 出“布”,它就稳不输了( 风险低);同理如果AI 出剪刀,就输赢各一半( 风险中等)。前两回,如果您出其他招( 不连续出同一招) 时,都全部看成“中等风险”。
于是,AI 只要善用它所发现的规则,在出拳瞬间自我评估它出招的风险,确保它不会掉入高风险的赛局里,它(AI) 的赢面就大增了。现在就来把上述的赢家规律输入到Excel 表格里( 图12)。

图12
按下“训练”,就开始训练DecisionRiskModel 分类模型。它是用来评估各种出拳方案的风险评估。例如,输入值[1,1,0],表示对方连续两次出“剪刀”,而AI决定出“石头”,此时评估出来:风险高。于是AI 决定改变出拳的选择。例如,改为出“布”,就输入[1,1,2],此时评估风险低,就是好策略了。
6 结束语
本期说明了决策型AI 的特色。并以划拳比赛为例,说明其架构,包括3 个AI 模型:第1 个是RnnPredict模型,负责探索对方的出拳规律( 知彼)。第2 个是DecisionRiskModel 模型,负责评估决策风险( 知己)。
第3 个是VoiceClassifier 模型是典型的语音识别模型。虽然本范例里,由3 个模型组合起来,与人们竞赛。但是它们也可以在商业环境里,协助人类决策者,进行优越的商业决策。
(本文来源于《电子产品世界》杂志2022年12月期)

评论