这7 个深度学习实用技巧,你掌握了吗?

前几天,深度学习工程师George Seif发表了一篇博文,总结了7个深度学习的技巧,主要从提高深度学习模型的准确性和速度两个角度来分析这些小技巧。在使用深度学习的时候,我们不能仅仅把它看成一个黑盒子,因为网络设计、训练过程、数据处理等很多步骤都需要精心的设计。作者分别介绍了7个非常实用小技巧:数据量、优化器选择、处理不平衡数据、迁移学习、数据增强、多个模型集成、加快剪枝。相信掌握了这7个技巧,能让你在实际工作中事半功倍!
本文引用地址:https://www.eepw.com.cn/article/201802/375972.htm

7 Practical Deep Learni ng Tips
7个实用的深度学习技巧
深度学习已经成为解决许多具有挑战性问题的方法。 在目标检测,语音识别和语言翻译方面,深度学习是迄今为止表现最好的方法。 许多人将深度神经网络(DNNs)视为神奇的黑盒子,我们输入一些数据,出来的就是我们的解决方案! 事实上,事情要复杂得多。
在设计和应用中,把DNN用到一个特定的问题上可能会遇到很多挑战。 为了达到实际应用所需的性能标准,数据处理、网络设计、训练和推断等各个阶段的正确设计和执行至关重要。 在这里,我将与大家分享7个实用技巧,让你的深度神经网络发挥最大作用。

▌ 1-数据,数据,数据
这不是什么大秘密,深度学习机需要大量的“燃料”, 那“燃料”就是数据。拥有的标签数据越多,模型的表现就越好。 更多数据产生能更好性能的想法,已经由谷歌的大规模数据集(有3亿图像)证明!为了感受数据带给深度学习模型的性能提升,在部署Deep Learning模型时,你应该不断地为其提供更多的数据和微调以继续提高其性能。 Feed the beast:如果你想提高你的模型的性能,就要提供更多的数据!
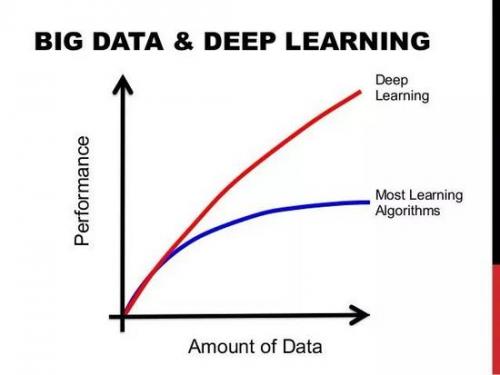
图显示数据量的增加会得到更好的性能
▌ 2-你应该选择哪一个优化器
多年来,已经开发了许多梯度下降优化算法,他们各有其优缺点。 一些最流行的方法如下:
Stochastic Gradient Descent (SGD) with momentum
Adam
RMSprop
Adadelta
RMSprop,Adadelta和Adam被认为是自适应优化算法,因为它们会自动更新学习率。 使用SGD时,您必须手动选择学习率和动量参数,通常会随着时间的推移而降低学习率。
在实践中,自适应优化器倾向于比SGD更快地收敛, 然而,他们的最终表现通常稍差。 SGD通常会达到更好的minimum,从而获得更好的最终准确性。但这可能需要比某些优化程序长得多的时间。 它的性能也更依赖于强大的初始化和学习率衰减时间表,这在实践中可能非常困难。
因此,如果你需要一个优化器来快速得到结果,或者测试一个新的技术。 我发现Adam
很实用,因为它对学习率并不是很敏感。 如果您想要获得绝对最佳的表现,请使用SGD + Momentum,并调整学习率,衰减和动量值来使性能最优化。





评论