这些关于STM32 DMA的使用,你都知道吗?

1.使用范围:
本文引用地址:https://www.eepw.com.cn/article/201802/375713.htmDMA(直接存储器存取)提供在外设与存储器之间或者存储器和存储器之间的高速数据传输使用。注意这里的外设指的是32的外设,比如spi、usart、iic、adc等基于APB1 、APB2或AHB时钟的外设,而这里的存储器包括32自身的闪存(flash)或者内存(SRAM)以及外设的存储设备都可以作为访问的源或者目的。注意外部存储设备其自身在这就是外设了,配置时属于外设,不要与配置寄存器的存储设备混淆
2.以目前嵌入式为例,DMA和CPU两者怎么实现分时使用内存:
通常采用以下三种方法:
(1)停止CPU访内存;
(2)周期挪用;
(3)DMA与CPU交替访问内存。
停止CPU访问内存
当外围设备要求传送一批数据时,由DMA控制器发一个停止信号给CPU,要求CPU放弃对地址总线、数据总线和有关控制总线的使用权.DMA控制器获得总线控制权以后,开始进行数据传送.在一批数据传送完毕后,DMA控制器通知CPU可以使用内存,并把总线控制权交还给CPU.图(a)是这种传送方式的时间图.很显然,在这种DMA传送过程中,CPU基本处于不工作状态或者说保持状态。
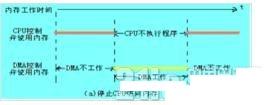
优点: 控制简单,它适用于数据传输率很高的设备进行成组传送。
缺点: 在DMA控制器访内阶段,内存的效能没有充分发挥,相当一部分内存工作周期是空闲的。这是因为,外围设备传送两个数据之间的间隔一般总是大于内存存储周期,即使高速I/O设备也是如此。例如,软盘读出一个8位二进制数大约需要32us,而半导体内存的存储周期小于0.5us,因此许多空闲的存储周期不能被CPU利用。
周期挪用
当I/O设备没有DMA请求时,CPU按程序要求访问内存;一旦I/O设备有DMA请求,则由I/O设备挪用一个或几个内存周期。
这种传送方式的时间图如下图(b):

I/O设备要求DMA传送时可能遇到两种情况:
(1)此时CPU不需要访内,如CPU正在执行乘法指令。由于乘法指令执行时间较长,此时I/O访内与CPU访内没有冲突,即I/O设备挪用一二个内存周期对CPU执行程序没有任何影响。
(2)I/O设备要求访内时CPU也要求访内,这就产生了访内冲突,在这种情况下I/O设备访内优先,因为I/O访内有时间要求,前一个I/O数据必须在下一个访问请求到来之前存取完毕。显然,在这种情况下I/O 设备挪用一二个内存周期,意味着CPU延缓了对指令的执行,或者更明确地说,在CPU执行访内指令的过程中插入DMA请求,挪用了一二个内存周期。与停止CPU访内的DMA方法比较,周期挪用的方法既实现了I/O传送,又较好地发挥了内存和CPU的效率,是一种广泛采用的方法。但是I/O设备每一次周期挪用都有申请总线控制权、建立线控制权和归还总线控制权的过程,所以传送一个字对内存来说要占用一个周期,但对DMA控制器来说一般要2—5个内存周期(视逻辑线路的延迟而定)。因此,周期挪用的方法适用于I/O设备读写周期大于内存存储周期的情况。
DMA与CPU交替访问内存
如果CPU的工作周期比内存存取周期长很多,此时采用交替访内的方法可以使DMA传送和CPU同时发挥最高的效率。
这种传送方式的时间图如下
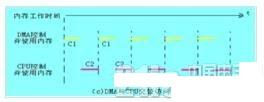
此图是DMA与CPU交替访内的详细时间图.假设CPU工作周期为1.2us,内存存取周期小于0.6us,那么一个CPU周期可分为C1和C2两个分周期,其中C1专供DMA控制器访内,C2专供CPU访内。
这种方式不需要总线使用权的申请、建立和归还过程,总线使用权是通过C1和C2分时制的。CPU和DMA控制器各自有自己的访内地址寄存器、数据寄存器和读/写信号等控制寄存器。在C1周期中,如果DMA控制器有访内请求,可将地址、数据等信号送到总线上。在C2周期中,如CPU有访内请求,同样传送地址、数据等信号。事实上,对于总线,这是用C1,C2控制的一个多路转换器,这种总线控制权的转移几乎不需要什么时间,所以对DMA传送来讲效率是很高的。这种传送方式又称为“透明的DMA”方式,其来由是这种DMA传送对CPU来说,如同透明的玻璃一般,没有任何感觉或影响。在透明的DMA方式下工作,CPU既不停止主程序的运行,也不进入等待状态,是一种高效率的工作方式。当然,相应的硬件逻辑也就更加复杂.
的DMA控制器和Cortex?-M3核心共享系统数据总线,执行直接存储器数据传输。当CPU和DMA同时访问相同的目标(RAM或外设)时, DMA请求会暂停CPU访问系统总线达若干个周期,总线仲裁器执行循环调度,以保证CPU至少可以得到一半的系统总线(存储器或外设)带宽。
也就是说对32而言,DMA即使和CPU使用同样的内存空间,32也会保证cpu至少会占用一半以上运行时间。也就是宏观上两者仍是同步的。而当DMA和CPU使用不同空间时,两者宏观上也是同步的
3.STM32使用DMA非循环方式传输完成后重新开启传输:
当通道配置为非循环模式时,传输结束后(即传输计数变为0)将不再产生DMA操作。要开始新的DMA传输,需要在关闭DMA通道的情况下,在DMA_CNDTRx寄存器中重新写入传输数目。
即关DMA->写传输数目->开DMA
4.借用系统提供的库函数或者说DMA_CNDTRx寄存器可以查询我们传输的剩余数据,可用在记录当前接收数据百分比的显示。
5.存储器到存储器模式
DMA通道的操作可以在没有外设请求的情况下进行,这种操作就是存储器到存储器模式。(我们以串口为例,这种外设查看串口使能DMA时序可知其会自动向CPU提DMA请求,而对于比如外设也是存储设备那么他自身不具有自动提DMA申请功能,这种就属于存储器到存储器模式,这是m2m位需置1)
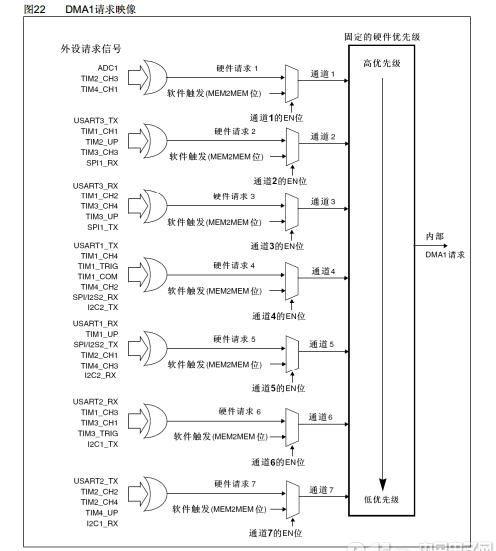
以上图DMA1请求映像为例,可知外设(这里指的是比如串口 spi TIM等32自带的外设)都是以硬件自动触发的DMA请求,而非自身外设比如加的外部存储设备无硬件自动触发机制就需要通过设置M2M位实现软件触发DMA请求给CPU了当设置了DMA_CCRx寄存器中的MEM2MEM位之后,在软件设置了DMA_CCRx寄存器中的EN位启动DMA通道时, DMA传输将马上开始。当DMA_CNDTRx寄存器变为0时, DMA传输结束。存储器到存储器模式不能与循环模式同时使用。



评论