基于H.323 高性能MCU的设计与实现

0 引 言
本文引用地址:https://www.eepw.com.cn/article/201706/348298.htm随着计 算机的 硬件, 特别 是 CPU 主 频的不 断提 升, 基于软件的音、视频编码效率也越来越高, 因此考虑 到成本与各方面的因素, 软件 MCU 必然成为以后的主 流方向。但现今大多的 MCU 都是软硬件相结合, 纯软件的MCU 很少且效率不高。当前 H.323 视频会议系统大都是以 Open h323 协议库为 基 础 开 发 的 视 频 和 语 音传输系统 软 件。 Openh323 是由澳大利亚 Equivalence PtyLtd。公司组 织开 发 的, 能 实 现 基 本 的 H.32 3 协议框 架, 在Openh323V4 中, 基于视频缓存池的 MCU 最多只能处 理合成 4 路终端, 不能适应现今市场发展的需要, 因此重新设 计 MCU 的 架 构, 便成为 研 发 软 件 MCU 的关键 。
1 源MCU 的缺陷和不足
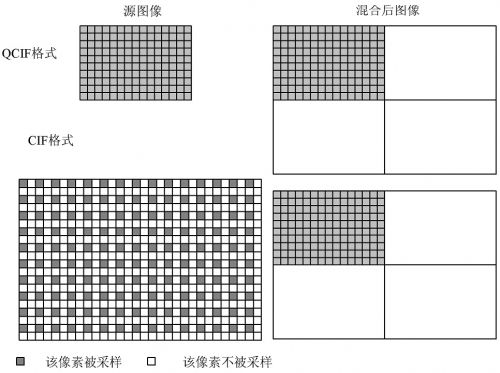
( 1) OpenH 3 23 中源 MCU 只能形成不超过 4 个终 端画面的图像。其中, 4 *1 为 CIF 格式 ( 35 2 * 28 8) ;1 * 1 为QCIF 格式( 176* 144) , 因此视频混合存在两种不同方式, 包括 QCIF 格式源图像混合成CIF格式图像以及 CIF格式源图 像 混 合成 CIF 格 式 图像, 如 图 1所示。
 |
| 图 1 传统MCU 图像合成 |
当源图像为QCIF格式时, 源图像大小正好是混合 后图像大小的1/4, 这时可以将源图像整幅地拷贝到混 合图像的相应位置; 当源图像为 CIF 格式时, 源图像与 混合后图像的大小一样, 因此源图像 3/ 4 的像素必须被 丢掉, 采用的方法是: 对源图像在水平方向进行隔点采 样, 在垂直方向进行隔行采样。这样处理之后, 源图像 大小也正好是混合后图像大小的 1/ 4 , 虽然图像的分辨 率已经下降, 但是保持了源图像画面的完整性; 如果将MCU 变成可容纳 16 个终端的显示画面, 在将 QCIF 源图像转换为 CIF 的合成图像 过程中, 只能将源图像 的采 样点按倍数减少。也 就是将 CIF 格 式 等 分 为16 份, 相 当 于 用 88 * 7 2 的 像 素 点 去 存 储 176 *144 QCIF 图像, 合成图像显示的像素点只有源图像的1/ 4; 如果将 MCU 可容纳的终端数目扩大为 32, 甚至更多时, 图像的清晰度将大打折扣。
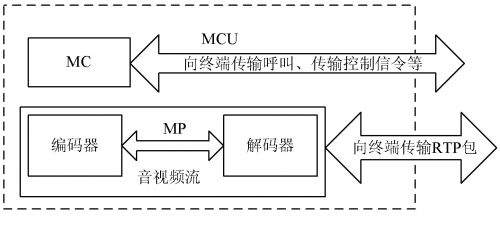
( 2) 传统软件 MCU 的架构是从硬件 MCU 继承过 来的, MCU 包括 MC 和 MP 部分。MC 部分对终端进 行连接控制以及逻辑通道的管理; MP 部分对音频进行混合, 视频进行合成。传统 MCU 的设计如图 2 所示, 这种架构适用于硬件 MCU ; 但对用软件实现的 MCU 并不太适合。用软件实现的 MCU 的编解码都是通过 CPU 来运算 的, 这样 必然增加 CPU 的运算 负荷。例 如: 要编码一路 30 f/ s 的 CIF ( 352 * 288 ) 图像, 大概编 码后的字节数为 30 * 3 52 * 28 8 * 2 = 6 MB, CPU 要处 理如此大的视频数据量, 经测试, P4- 2.6 G 的 CPU 在 这种架构下, 最多支持 5 路终端, 如超过 5 路, CPU 运 算负 荷过大, 其资源 基本耗尽, 图像 合成的效 果严重 下降。因此, 要实现高性能的 MCU , 必须把 MCU 对多路音、视频编码的大数据量处理的工作环节转移到各个终 端上, 让终端对相应的音、视频编码进行处理, 而 MCU 只对各路 的音 视频 流 进行 存 储转 发, 这 样才 能 减轻MCU 的负荷, 从而提高系统的整体效率。
 |
| 图 2 传统 M C U 设计图 |
综上所述, 在此提出采用基于帧缓冲映射软交换的 MCU 系统设计模式, 所谓的软交换模式就是仿照交换 机的模式, 不对音、视频流进行编解码的处理, 只对数据 进行转发与控制。该MCU 也包括 MC 与 MP。基于软交换的 MP ,通过帧缓冲映射算法, 查找终端对应的缓冲区, 然后到把接收到的音、视频流存放到该缓冲区里面, 通过 MC控制, 把音、视频数据流转发到终端。
2. 1 M C 部分总体设计思想
MC 部分的设计 主要包括会议组 管理、会 议 RTP流转发管理。
( 1) 会议管理。该系统只默认一组会议, 且默认的 会议房间为/ r oom1010 。对一组会议来说, 主要管理会 议的成员信息, 处理与会者的加入与退出等。为了实现 这些功能, 建立一个会议 组类、成员信息 类、成员状 态 类、成员身份类和成员视频缓冲类。会议组类主要记录 终端所选的会议 ID; 成员信息类主要记录终端的 To- ken , IP 地址等信息; 成员类状态主要记录成员是否在 线; 成员身份类可以确定是主席, 还是听众; 成员视频缓 冲类主要是存放在线各个终端的 RTP 包, 一个缓冲类 里面可以存在多个缓冲区。MC 首先通过设定 TCP 特 定的端口, 并在端口上建立一个 TCP 监听线程, 终端通 过这个端 口与 MCU 进 行 TCP 连 接, 并由 MC 建 立 一个H.225 呼叫线程, 用于监听 H.22 5 呼叫信令, 通过 这个 H.225 通道, 终端把自己的会议组 ID, IP, Token 等身份认证注册到 MC。图 3 为 MC 的会议管理系统框图。
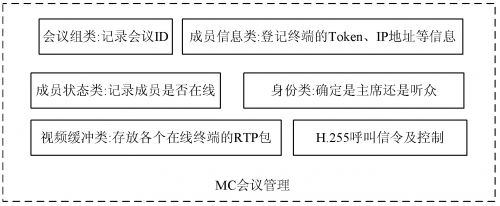 |
图 3 MC 会议管理系统框图 |
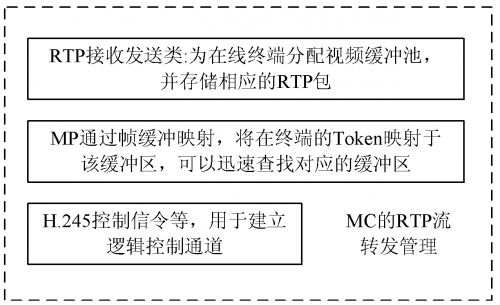
( 2) 会议 RTP 流转发管理。MCU 对登陆终端进 行注册后, MC 建立一个 H. 245 控制信令线程, 并与该终 端进行连接控制, 通过 H.245 控制信令与 MC 进行呼叫、 信令处理与能力协商、主从决定; 然后建立音、视频的接 收逻辑通道, 通过 RTP 接收类开始接收终端发送的 RTP 帧, 把 RT P 帧保存到分配给该终端缓存区里。MC 为已 经进行了呼叫连接的终端分配了一一对应的视频缓冲接 收区, 该缓冲区是一个分配在堆里面的数据结构, 例如: 在终端 A 的在线人员列表上, 可以看到登陆注册到 MCU 的人员名单; 通过对终端的人员名单的选择, 例如选择 B, 那么终端 A 可以要求 MC 转发终端 B 的音、视频, 当MC 收到终端 A 提交的要求转发终端 B 的信 息后, 在MC 的 A 终端缓冲池里面, 为终端 B 新建一个缓冲区, 通 过 MP 对终端 B 的 Token 的帧缓冲映射查找到终端 B 的 音视频缓冲池, 并在终端 A 与终端 B 之间建立一条逻辑 通道, 用于向终端 A 传输终端 B 的 RTP 包, 当 MC 的终 端 A 缓冲类接收到终端 B 的 RTP 包后, 把 RTP 包拷贝 到原来的接收缓冲区里; 然后同样把终端 B 的惟一 Token 通过哈希函数映射到这个缓冲区上。
图 4 为 MC 的 RTP 管理系统框图。MC 的软交换模式如图 5 所示。
 |
| 图 4 MC 的RTP 管理系统框图 |
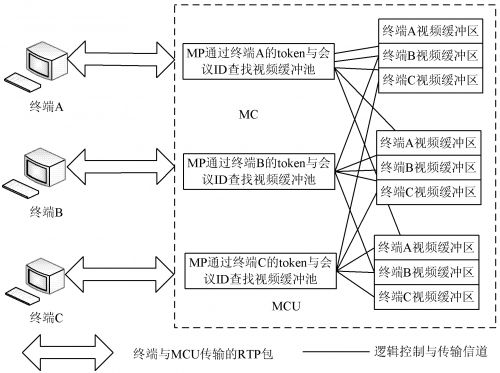 |
| 图 5 基于软交换的 MCU |
2. 2 MP 部分总体设计思想
基于软交换的 MP, 通过帧缓冲映射算法查找终端 对应的缓冲区, 然后把接收到的音、视频流存放到该缓冲 区里面, 通过 M C 的控制, 把音、视频数据流转发到终端。 由于 MCU 需要处理大量的实时 RTP 包, 效率成为了最 主要的问题。因此如何从缓冲区里面快速搜索相应的数 据包是 M P 能否快速处理数据的关键。考虑到 M P 要处 理不同的终端, 不同的终端对应不同的缓冲区, 所以采用 哈希函数映射法, 它将任意长度的二进制值映射为固定 长度的较小二进制值, 并把这个哈希表存放到相应的内 存区, 以便多次的查找, 这样通过这个较小的二进制值就 可以以非常快的速度找到比较大的数值。因此把视频缓 冲区的首地址存放到一个哈希表里面, 并通过这个哈希 表把终端的Token 映射于这个缓冲区, 这样通过终端的 惟一Token 便可以迅速找到其对应的缓冲区。
实现 MP 部分帧缓冲映射算法的具体设计步骤是: 首先 MCU 把登陆的在线终端 Token ( 终端的惟一标识) 与会议 ID 默认为 room101, 通过哈希函数, 映射到一个 缓冲区, 通过终端的 Tok en 和会议 ID, 就可以直接找到 本终端 的缓冲区, 当 MP 收到 终端的 RTP 包后, 通 过 RTP 包的边界分析, 把多个 RTP 合成一个数据帧, 然后 把数据帧放到相应的终端缓冲区里面。帧缓冲映射的查 找如图 6 所示。假设当终端 A 要求转发终端 B 的音、视 频数据流时, M P 通过哈希函数找到相应终端 B 的缓冲区域, 然后把该缓冲区的数据读出到数据帧里面, 最后通 过 RTP 包进行发送到终端 A , 而终端 A 在接收到 MCU 发送的终端 B 的音视频数据压缩包后, 再对其进行音视 频进行解码。
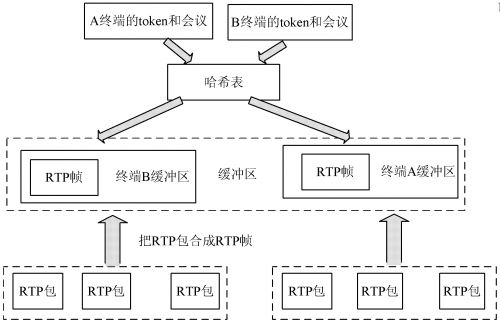 |
| 图 6 帧缓冲映射查找图 |
2. 3 MCU 系统实现
根据以上的设计思想, 得出如图 7 所示的 MCU 系统流程图。
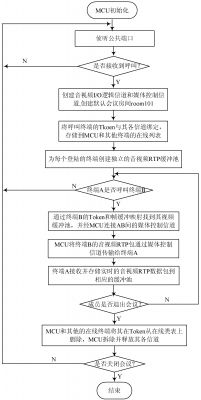 |
| 图 7 MCU 系统流程图 |
2. 4 测试结果与结论
通过重新设计 MCU 的 MC 和 MP 后, MCU 的性 能有了较大的提高。从性能方面进行测试, 由于传统的 MCU 在 MC 上进 行编解码, 只能容 纳4 路音、视频终 端, 而通过修改的 MCU , MC 没有进行编解码, 只对音、 视频进行存储转发, 因此在 9 路音、视频的情况下, 系统 的 CPU 只占有 5% 。从效率、质量方面进行比较, 由于 传统的 MCU 进行了 4 路编解码, 返回到终端的数据包 延迟比较大, 而修改过的 M CU 没有进行到编解码, 因 此数据包的延时很小。传统的 MCU 在 MC 里面进行 图像的混合, 图像的分辨率变为原来的 1/ 4, 因此图像 质量有较大的下降, 而基于软交换的 MCU 保持了原来 图像的分辨率, 因此图像质量较好。从视频的帧数来比 较, 传统的 M CU 架构不能达到15 f/ s, 而基于软交换的 MCU 能达到 30 f / s 。由于基于软交换的 MCU 的视频 传输的是 原来 图像 的 分辨 率, 因 此 传输 率比 传 统的 MCU 要高, 但可以通过在终端采用传输率较低的编码 器来降低 传输 率。 表 1 为 M CU 改进 前与 改进 后的 对比。
| 表1 MCU 改进前与改进后的对比数据 |
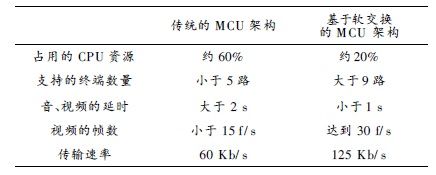 |
传统的 架构 基于软交换 的 MCU 架构占用的 CPU 资源 约 60% 约 20% 支持的终端数量 小于 5 路 大于 9 路 音、视频的延时 大于 2 s 小于 1 s视频的帧数 小于 15 f / s 达到 30 f/ s传输速率 60 K b/ s 125 K b/ s终端的 6 分界面如图 8 所示。
 |
| 图8 终端6 分屏界面 |
3 结 语
从以上的测试证明, 基于软交换的 MCU 架构, 使 MCU 的性能有了很大的提 高。本文同时也说明了只 要系统程序设计 合理, 基于 软件的 MCU 是 切实可行 的。随着硬件水平的不断提高, 纯软件的 MCU 将以其低成本、简易操作而普及到低端用户。






评论