CDNN:一键生成嵌入式神经网络

我在之前的两篇博文中讨论了深度学习的框架、特点及挑战以及嵌入式系统中深度学习所面临的具体挑战。我想在本篇博文中介绍应对这些挑战的工具包。此工具包是提高嵌入式系统深度学习开发效率的极为强大且行之有效的途径。
本文引用地址:https://www.eepw.com.cn/article/201702/343503.htmCEVA 深度神经网络 (CDNN) 工具包由三项关键部件构成:
CDNN2 软件框架
CEVA 网络生成器
CDNN 硬件加速器
这些部件共同提高了成像及视觉处理器 CEVA-XM 产品系列的功能,从而为可拍照的设备提供了能耗极低的深度学习解决方案。本博文将对这些部件进行一一介绍,让大家对其功能及工作原理有所了解。
支持 Caffe 及 TensorFlow
CDNN 工具包中的 CDNN2 是第二代 CEVA 深度神经网络软件 (SW) 框架。它支持将要求最为严苛的机器学习网络拓扑从预训网络迁移到嵌入式系统。它使得相机设备能进行基于深度学习的本地视频分析。与在云服务中运行此类分析相比,CDNN2在缩短等待时间并提高隐私的同时,还能极大地降低数据带宽及存储量。与 CEVA-XM 智能视觉处理器配套使用,CDNN2 极大地缩短了上市时间并在嵌入式系统执行机器学习的能耗方面有极大优势。
CDNN2 SW 框架的设计离不开 CEVA-XM 客户及合作伙伴的丰富经验。他们一直利用我们的软件框架在多个终端市场开发并推广深度学习系统,包括智能手机、高级辅助驾驶系统 (ADAS)、监控设备、无人机及机器人等。
除了为 Caffe 提供支持,第二代框架包括对由 TensorFlow 生成的网络的支持,从而确保客户利用谷歌强大的深度学习系统开发其下一代 AI 设备。CDNN2 软件库是很灵活的模块,既可支持所有 CNN 执行条件又可支持各类网络的不同网络层。这些网络包括 Alexnet、GoogLeNet、ResidualNet (ResNet)、SegNet、VGG (VGG-19、VGG-16 及 VGG_S) 及网中网 (NIN) 等。CDNN2 支持最先进的神经网络层,包括卷积、去卷积、池、全连接、softmax 层、串联和 upsample 层,以及各类初始模型。它支持所有网络拓扑,除了线性网络(如 Alexnet)外,还包括多入多出、每一级网络的多层及全卷积网络。
让开发商在 CEVA 开发板上实时运行网络
CDNN2 流程由两部分组成。首先是网络训练阶段。此阶段可由我们的 OEM/客户或合作伙伴在线下完成。训练时间取决于网络结构、图像数据库大小及构成网络的层数。训练阶段的成果是训练好的的浮点网络。目前我们所面临的挑战是在嵌入式系统中高效地运行此网络。例如,Alexnet 预训网络是 253Mb 的浮点网络,包括权重及数据。
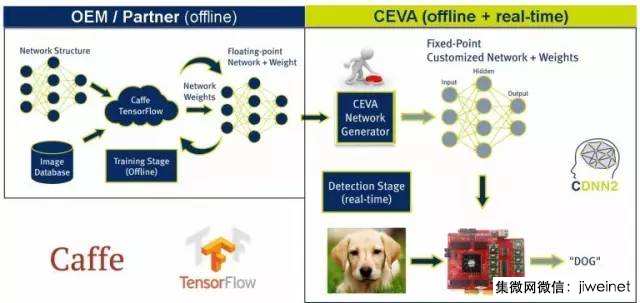
CDNN2 使用流
第二部分是 CEVA 进行必要转换并使网络为嵌入式系统做好准备。CDNN2 框架的核心部件是线下 CEVA 网络生成器。利用此生成器,轻按按钮即可将预训浮点神经网络转换成定点数学计算下对等的嵌入优化网络。CDNN2 的可交付产品包括一个基于硬件的开发包,不仅可让开发商模拟运行其网络,还可在 CEVA 开发板上轻松进行实时运行。
CDNN2 实时应用程序流程
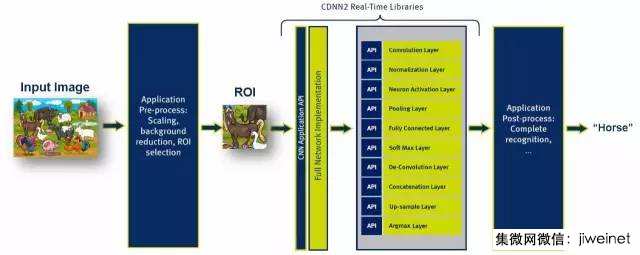
应用程序流程从处理实景开始,在应用程序的预处理阶段进行处理。预处理包括缩放、背景弱化及选择感兴趣区域 (ROI)。主机端及 DSP 端均可执行此阶段的处理任务。预处理阶段将所选择的 ROI 发送至 CDNN 实时图像库进行处理。这使用的是 CNN 应用程序 API。
CDNN2 应用程序流
正如上方图片所示,CEVA 为每一层均提供 API,因此灵活性极强。 CDNN 实时图像库的处理结果是 ROI 分类。接下来,应用程序的后处理模块完成识别阶段并继续追踪未识别出的新物体。
AlexNet – 网络性能
为演示此种解决方案在真实神经网络上的功能,我们来看看 Alexnet。这是一个有着 24 层并能识别 1000 类的网络。它所需的预训网络内存带宽约为 250 Mb 浮点。这同时包括权重及数据。对于嵌入式系统而言,这是个非常重的网络,因此运行此网络是一项严峻挑战。如果采用的是 CEVA 解决方案,那么在使用“CEVA 线下网络生成器”及实时 CDNN 数据库之后,网络带宽减至 16 Mb 浮点。这就完成了CEVA-XM 视觉处理器架构的优化。
CEVA 网络生成器 – 不到 10 分钟即可做好嵌入准备
如前所述, CEVA 网络生成器是 CDNN 解决方案的关键部件。此部件的主要优势在于使用方便,以及它在网络移植、转换及适应嵌入式平台上所节省的时间。在确定开发时间、开发风险及由此导致的开发成本上这是一个很重要的考量因素。
那么它是如何工作的呢?如前所述,先是线下训练网络的 Caffe、TensorFlow 及其它网络所使用的图像数据库。输入 CEVA 网络生成器的文件包括转换所需的重要数据。以下为输入 CEVA 网络生成器的各类文件:
caffemodel,包括预训浮点网络。
prototxt,包括以下网络结构信息:
1. 所使用的 SW 框架,可以是 Caffe 或 TensorFlow
2. 所输入的参考图像的大小
3. 各类神经网络层的类型及其参数
4. 归一化的图像(如需要)
标记,包括网络标记。标记定义后期与后处理块进行通信的各类选项。
一旦设定好网络生成器所需的所有参数,最后一步就是“按按钮”。结果便是得以全面优化的运行 CEVA-XM 视觉处理器的网络。从始至终,整个过程不到 10 分钟。这可不是需要花费数周甚至数月之久的人工移植网络。下列视频可让你感受网络生成器的速度及其便于使用的特点。从互联网上下载年龄分类神经网络,通过 CEVA 网络生成器进行传递并在 CEVA-XM4 FPGA 上运行,这整个过程约需要 7 分钟。
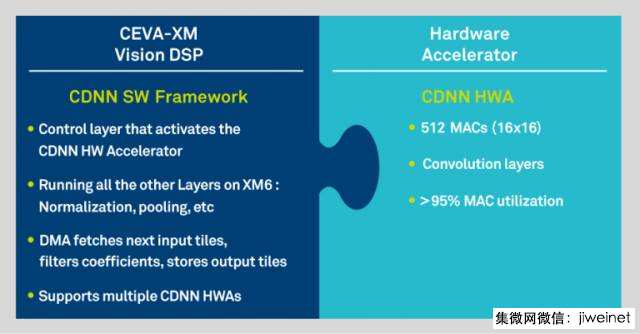
CDNN 硬件加速器
除了这些节省时间的软件工具,功能强大的专用硬件加速器 (HWA) 更是让 CDNN 工具包如虎添翼。CDNN HWA 让深度学习算法的性能极为出色,且能耗极低。在 16b 的精度下达到 512 MACs/cycle,这使其在运行当今最复杂的神经网络时能有一流的性能表现。同时使用 CDNN 软件框架及 CDNN 硬件加速器不仅能让神经网络具备适应不断变化的机器学习领域发展的灵活性,也会带来超凡的性能表现。
人工智能正改变世界,它会进入嵌入式系统
从虚拟助手到自动车辆,人工智能 (AI) 正在重新定义获得信息的方式、便利、安全及人类生活的其它方面。由于人工智能进入更小的便携设备,我们的生活便有了无尽可能。正如我在本文及之前的博文中所深入探讨的,这也带来了诸多挑战。CDNN 工具包的设计可应对所有这些挑战。它提供了最佳的硬件软件 IP 组合,而省时的开发工具让其性能更为出众,从而为数十亿种设备铺平了使用深度学习的道路。随着这些技术的发展与演变,CEVA 将继续位于开发神经网络嵌入式平台的最前沿。





评论