孤立词语音识别系统的DSP实现

0 引 言
在孤立词语音识别中,最为简单有效的方法是采用动态时间规整(Dynamic Time Warping,DTW)算法,该算法解决了发音长短不一的模板匹配问题,是语音识别中出现最早、较为经典的一种算法。用于孤立词识别,该算法较现在比较流行的HMM算法在相同的环境条件下,识别效果相差不大,但HMM算法要复杂的多,这主要体现在HMM算法在训练阶段需要提供大量的语音数据,通过反复计算才能得到模型参数,而DTW算法的训练中几乎不需要额外的计算。所以在孤立词语音识别中,DTW算法仍得到广泛的应用。本系统就采用了该算法。
1 系统概述
语音识别系统的典型实现方案如图1所示。输入的模拟语音信号首先要进行预处理,包括预滤波、采样和量化、加窗、断点检测、预加重等。语音信号经过预处理后,接下来重要的一环就是特征参数提取,其目的是从语音波形中提取出随时间变化的语音特征序列。然后建立声学模型,在识别的时候将输入的语音特征同声学模型进行比较,得到最佳的识别结果。
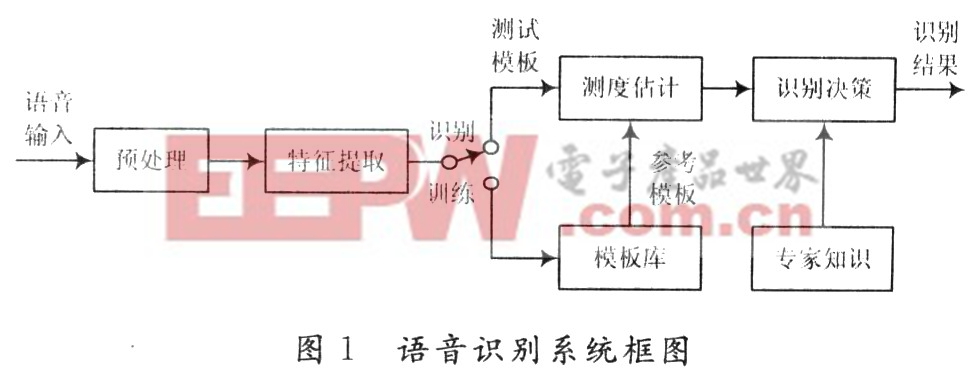
2 硬件构成
2.1 系统构成
这里采用DSP芯片为核心(图2),系统包括直接双访问快速SRAM、一路ADC/一路DAC及相应的模拟信号放大器和抗混叠滤波器。外部只需扩展FLASH存储器、电源模块等少量电路即可构成完整系统应用。








评论