嵌入式多媒体应用的多核编程框架

基于单核结构的嵌入式处理器越来越难以满足日益增长的嵌入式多媒体应用的处理需求,多核嵌入式结构已成为解决这一问题的有效途径,同时也为如何充分开发利用多核结构的应用软件带来挑战。目前的编译技术和开发工具需要更精密,才能使多核结构的应用获得成功。大多数并行软件都是通过手工转换方式将顺序程序转换为并行程序来实现的,由于缺乏具有多核意识的开发工具,使得软件难以进行性能评估。因此,如果没有预先有效可靠的工程规划,将不得不面对应用软件效率低下以及延迟产品上市时间等问题。
软件框架为多核应用软件的开发提供了一个更好的起点,可以帮助缩短开发时间。本文将详细说明嵌入式多媒体应用软件的设计框架,同时,本文的数据流模型也可扩展到许多其它应用中。该框架综合了多媒体应用软件固有的数据并行结构,并说明了如何通过使用底层架构来有效管理数据流。
在设计并行软件的过程中有两大挑战:一是开发有效的并行算法,二是有效地利用存储器、DMA(直接存储器访问)通道和互连网络等共享资源。在该过程中,顺序运行的应用程序的性能可根据可用处理器核的数目进行扩展。
实现应用程序的并行处理常常有多种方法。有些应用程序表现出固有的并行特性,而其它的则具有极其复杂且不规则的数据存取模式。但总的来讲,科学计算类的应用程序和多媒体应用程序的并行化通常易于实现,因为它们的数据存取模式比那些控制类应用程序相对容易预测。本文重点讨论针对多媒体算法的并行技术,这类算法需要很高的处理能力,并且更适合嵌入式系统应用。
多媒体应用程序中存在数据的并行级别。一组数据帧与数据帧中的一个宏块之间的并行粒度有很大差别。通常来讲,粒度越小,共享单元(如处理器核和DMA通道等)之间所需的同步级别越高。粒度越小,并行程度就越高,网络通信量越小;粒度越大,同步要求就越低,但网络通信量会增大。因此,基于应用的不同类型和系统需求,软件框架也定义了不同的并行级别。
需要说明的是,可扩展并行软件的开发还依赖于对互连网络、分级存储器体系以及外设/DMA资源的有效利用。系统严格的低功耗和低成本要求对所有这些要素都会构成限制。在多核环境下编程时,有效利用这些资源需要进行创新。本文提出了一些在ADI公司的Blackfin ADSP-BF561双核处理器上有效管理资源的构想。
多媒体数据流分析
为了实现数据并行,需要在数据流中找到这样一个或一组数据块:可以独立处理并将其“喂”给一个处理元件。独立的数据块可以降低同步开销并简化并行算法。要找到这种数据,必须弄清应用的数据流模型,或者说“数据存取模式”。
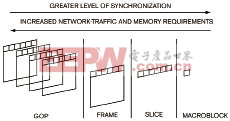
对于大多数多媒体应用,可以将数据存取模式看成是2D(空间域)和3D(时间域)操作模式。在2D模式中,独立的数据块被限制在单个数据帧内,而在3D模式中,独立数据块可以横跨多帧。在空间域中,可以将帧划分为由N个连续行和视频帧宏块组成的片段,而在时间域中,可以对数据流进一步细分到帧级或图片组(GOP)级。
采用片段或宏块数据存取模式的算法对同步性要求较高,但网络传输量较少,这是因为分级存储器体系只需存储图像数据的一部分。对于帧或图片组类型的数据存取模式,分级存储器体系则需要存储大量数据,但对同步性的要求则相对低得多,这是因为系统的并行粒度更大。图1说明了多媒体应用软件中的并行级别,同时显示了四个级别的相对同步要求和网络通信量。
多核结构分析
图2显示了ADSP-BF561的结构,它包括独立的指令和数据存储器,分别属于两个处理器核专有,此外还包括共享的L2存储器和外部存储器。用户可以利用可配置的仲裁方案将所有外围设备和DMA资源连接到任一处理器核。该处理器有两个DMA控制器,每个DMA控制器由两组MDMA(存储器DMA)通道组成。L2存储器与每个处理器核之间通过独立的总线连接,外部存储器与两个处理器核之间则由一条共享总线连接。

图2 ADSP-BF561的结构包括独立的指令和数据存储器,分别属于两个处理器核专有,此外还包括共享的L2存储器和外部存储器。
所有框架都利用DMA方式将数据流送入分级存储器体系。另一种选择是高速缓存,它不管理任何数据。如果清楚目标应用的数据存取模式,就可以利用DMA引擎对数据进行有效的管理。而使用高速缓存需要忍受不确定的访问时间、高速缓存未命中的代价,以及需要较高的外部存储器带宽。利用DMA引擎,可以在处理器核请求数据之前就将数据送入L1存储器,系统在后台执行传输操作,而不会因为数据项请求使处理器核暂停工作。
由于每个DMA控制器上都有两组MDMA通道,因此系统可以将MDMA通道在处理器核上均匀分配,从而可以对称地进行并行处理。
对于数据存取模式粒度较小的应用,可以轻松地利用对L1和L2存储器的快速访问。也可以直接将独立的数据块从外设接口传送到L1或L2存储器,而不需要访问慢速的外部存储器,这样可以节省宝贵的外存储器带宽和MDMA资源,并缩短数据传输时间。
对于数据存取模式粒度较大的应用,存储器可能成为瓶颈,因为较小的L1和L2存储器级不足以容纳大量的数据帧。然而,大量数据帧之间虽然存在数据关联性,但这种关联通常也仅存在于跨数据帧的较小数据块上。如果能将所有关联的数据帧存放在一个较大的存储空间(外部存储器)中,就可以将每一帧中的独立数据块相继送入空闲的处理器核进行处理。如果这些独立的数据块比数据帧小得多,符合L1或L2存储器的容量,就可以减少存储器存取延迟,高效地处理数据。
虽然L2和外部存储器都有独立的总线连接,但两个处理器核仍共享这些存储器接口总线。因此,应当尽量避免两个处理器核同时对同一级别的存储器进行存取操作,以免因总线冲突而停止工作。为了减少总线冲突状况,框架应考虑代码和数据对象的映射,让一个处理器核主要访问L2存储器核,而另一处理器核则主要访问外部存储器。在这种情况下,虽然处理器核完成多数外部存储器访问会出现较大的访问延迟,但总的访问延迟仍然小于总线冲突的代价。
框架把所有输入外设接口分配给一个处理器核,把所有输出外设接口分配给另一处理器核。框架利用视频输入/输出接口,例如PPI(并行外设接口)来输入和输出视频帧。BF561架构有两个PPI接口。
如果中断处理时间比数据流的处理时间要短,则可将所有的外设接口分配给一个处理器核以便于编程,较短的中断处理时间不会影响两个处理器核的负荷平衡。
软件框架的建议模型
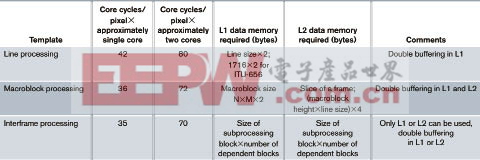
基于数据存取模式的粒度,可以定义四种软件框架:行处理(空间域)、宏块处理(空间域)、帧处理(时间域)以及GOP处理(时间域)。如果某个应用程序的数据存取模式适于这四种模型中的任何一种,就可以采用相应的框架。如果一个数据流有两种或更多的处理算法,还可以将多种框架结合起来,实现非对称的并行处理。
在行处理模式中,关联性只存在于行级,也就是说,只存在于相邻像素之间。每行数据形成一个数据块,各处理器核都可以独立处理。
图3显示了行处理框架的数据流模型。处理器核A处理视频输入,处理器核B处理视频输出。核A和B之间的数据由独立的MDMA通道组进行管理。L1存储器使用多个缓神器,可以避免处理器核与外设DMA访问总线的冲突。两个处理器核之间每行数据的同步通过计数信号量实现。在这种框架中,采用单处理器核方式将数据直接存入L1存储器也具有优势,可以节省外部存储器带宽和DMA资源。这种框架的应用实例包括色彩变换、直方图均衡化、滤波和采样。
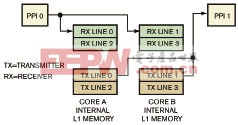
图3 行处理框架的数据流模型。处理器核A处理视频输入,处理器核B处理视频输出。
图4显示了宏块数据访问模式的数据流模型,可以在两个处理器核之间交替传送宏块。L2存储器具有多个片段缓冲器,独立的MDMA通道将宏块从每个处理器核的L2存储器传输到L1存储器。L1存储器也有多个缓神器,用以避免DMA与处理器核访问总线的冲突。与行处理框架类似,该框架中处理器核A控制输入视频接口,处理器核B控制输出接口,计数信号量实现两个处理器核之间的同步。这种框架的应用实例包括边缘检测、JPEG/MPEG编码/解码算法和卷积编码。
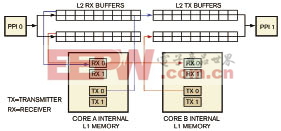
图4 在双核宏块数据访问模式中,L2存储器具有多个片段缓冲器,独立的MDMA通道将宏块从每个处理器核的L2存储器传输到L1存储器。
在帧级处理模式中,外部存储器存储关联帧。根据数据帧(宏块或行)之间的关联性粒度,系统将数据帧的子块传送到L1或L2存储器。图5显示了帧级处理框架的数据流模型。在这种情况下,假定某个宏块在多个帧之间存在关联,则系统将数据帧的宏块传送至L1存储器。与其它框架类似,该框架中处理器核A控制输入视频接口,处理器核B控制输出接口,通过计数信号量实现两个处理器核之间的同步。这种框架的应用实例包括运动检测算法。
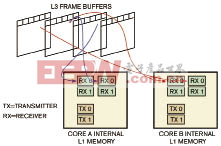
图5 在帧级处理流程中,外部的存储器存储独立帧
在GOP级处理模式中,每个处理器核处理多个相继的数据帧。帧级处理框架与GOP级处理框架之间的区别在于,前者是在帧内完成空间划分,后者则通过时间划分(帧序列)实现并行处理。对于GOP数据访问模式,关联性存在于一组数据帧内部,两组帧之间数据不存在关联性。因此,处理器核可以独立处理每一组帧。图6显示了这种框架的数据流。与帧级处理框架类似,系统可以将帧数据块传送至处理器核的L1存储器。为了有效利用外部存储器的交错存储库结构,系统在处理器核间均衡地分配存储库。ADSP-BF561的每一个外部存储库都支持多达四个内部SDRAM存储库。这种框架的应用实例包括MPEG-2/4等编码/解码算法。
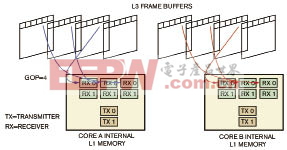
图6 在GOP级数据访问模式中,关联性存在于一组数据帧内部,两组帧之间数据不存在关联性。
在实际应用中,系统可能使用多种算法处理数据流,而每种算法都可能用到不同的数据存取模式。这种情况下,可以针对特殊应用将几种框架结合起来使用。为利用多核结构,可以采用流水线处理来实现并行操作,但这种并行操作是不对称的,因为不同处理器核上可能执行不同的计算。然而,系统可以分配一些其它的任务到处理器核的空闲指令上,在保持灵活性的同时达到处理器核的工作量平衡。图7显示了行级处理和宏块处理相结合的框架的数据流模型。
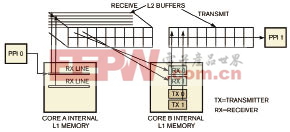
图7 行级处理和宏块处理相结合的框架的数据流模型
软件框架分析
为了对双核处理的软件框架进行评估,ADI公司利用数据流模型率先开发了一款单核应用软件,然后与双核方案进行对比。Blackfin独有的系统优化技术也能有效地利用可用带宽。为了简化分析,ADI公司只比较了基本框架的处理速度,而没有考虑几种架构的组合。
所谓周期,是指为了满足NTSC(美国国家电视系统委员会)视频输入的实时约束条件而用于处理数据流的处理器核计算周期。对于一个以600MHz速度运行的处理器核,为了满足实时约束条件,处理每一像素可用的总周期数为44周期/像素。任何对数据流的处理器核访问都只需要一个单核周期,因为所有数据访问都是对L1存储器的访问。所示的周期数不包括中断延迟。
如表1所示,双核框架将所有框架的处理速度有效提高了两倍。表中还说明了每个处理器核的L1存储器使用量,以及各种框架需要的共享存储器空间。这些框架使用ADI公司的DD/SSL(器件驱动/系统服务库)实现对外设和数据的管理。



评论