微软OpenAI联手围剿英伟达,首款自研AI芯片下月发布!

编辑:好困 润【导读】一家独大的英伟达,把微软和OpenAI都逼得亲自下场造芯片了。也许AI芯片大战才刚刚拉开帷幕。
微软自研AI芯片,11月上线!知名外媒The Information独家爆料称,微软计划在下个月举行的年度开发者大会上,推出首款人工智能芯片。 同时,OpenAI也在招聘能够帮助其评估和设计AI硬件的人员。
同时,OpenAI也在招聘能够帮助其评估和设计AI硬件的人员。
 业内有一种说法,「卖H100比向沙漠里快要渴死的人卖水还要容易」。不论是为了走出算力枯竭,更高效,低成本地开发自己的模型,还是为了摆脱被「利润率高达1000%」的H100盘剥。
业内有一种说法,「卖H100比向沙漠里快要渴死的人卖水还要容易」。不论是为了走出算力枯竭,更高效,低成本地开发自己的模型,还是为了摆脱被「利润率高达1000%」的H100盘剥。 微软和OpenAI都在尝试「变硬」,努力戒掉对于英伟达的GPU依赖。但是,根据业内人士爆料,英伟达对于已经推出自己芯片的公司,比如谷歌和亚马逊,会控制GPU的供给。所以「芯片自研」的道路,是一个风险和收益都很高的选择,毕竟谁也不想未来被黄老板在GPU供给上进一步「卡脖子」。
微软和OpenAI都在尝试「变硬」,努力戒掉对于英伟达的GPU依赖。但是,根据业内人士爆料,英伟达对于已经推出自己芯片的公司,比如谷歌和亚马逊,会控制GPU的供给。所以「芯片自研」的道路,是一个风险和收益都很高的选择,毕竟谁也不想未来被黄老板在GPU供给上进一步「卡脖子」。
 相比起早早入局的竞争对手,微软直到2019年才开始AI芯片的研发。也是同年,微软宣布将向OpenAI投资10亿美元,并要求他们必须使用微软的Azure云服务器。然而,当微软开始与OpenAI进行更紧密地合作时发现,依靠购买GPU来支持这家初创公司、Azure客户以及自家产品的成本,实在是太高了。据知情人士透露,在开发Athena期间,微软为了满足OpenAI的需求,已经向英伟达订购了至少数十万块GPU。早在,今年4月,就有消息透露了这款代号为Athena的芯片的存在。
相比起早早入局的竞争对手,微软直到2019年才开始AI芯片的研发。也是同年,微软宣布将向OpenAI投资10亿美元,并要求他们必须使用微软的Azure云服务器。然而,当微软开始与OpenAI进行更紧密地合作时发现,依靠购买GPU来支持这家初创公司、Azure客户以及自家产品的成本,实在是太高了。据知情人士透露,在开发Athena期间,微软为了满足OpenAI的需求,已经向英伟达订购了至少数十万块GPU。早在,今年4月,就有消息透露了这款代号为Athena的芯片的存在。 据称,微软希望这款代号为Athena(雅典娜)芯片,能与一直供不应求的英伟达H100 GPU相媲美。目前,亚马逊和谷歌已将人工智能芯片作为其云业务营销战略的重要组成部分。
据称,微软希望这款代号为Athena(雅典娜)芯片,能与一直供不应求的英伟达H100 GPU相媲美。目前,亚马逊和谷歌已将人工智能芯片作为其云业务营销战略的重要组成部分。 其中,亚马逊在对Anthropic的投资中规定,对方需要使用亚马逊的AI芯片,即Trainium和Inferentia。同时,谷歌云也表示,Midjourney和 Character AI等客户使用了自研的TPU。
其中,亚马逊在对Anthropic的投资中规定,对方需要使用亚马逊的AI芯片,即Trainium和Inferentia。同时,谷歌云也表示,Midjourney和 Character AI等客户使用了自研的TPU。 微软虽然还在讨论是否要向Azure云客户提供自研芯片,但该芯片在开发者大会上的首次亮相,可能预示着微软正在寻求吸引未来云客户的兴趣。可以肯定的是,微软将借着Athena的推出,极大缩短与另外两家巨头的距离——谷歌和亚马逊早已在自家的云服务器上大规模采用了自研的芯片。此外,为了摆脱英伟达的「卡脖子」,微软还在与AMD密切合作,开发即将推出的人工智能芯片MI300X。不过,微软和其他云服务提供商普遍表示,自己并没有停止从英伟达购买GPU的打算。但如果他们能说服云客户更多地使用自研芯片,那么从长远来看,这可以极大地节省开支。同时,也能帮助他们在与英伟达的谈判中获得更多筹码。
微软虽然还在讨论是否要向Azure云客户提供自研芯片,但该芯片在开发者大会上的首次亮相,可能预示着微软正在寻求吸引未来云客户的兴趣。可以肯定的是,微软将借着Athena的推出,极大缩短与另外两家巨头的距离——谷歌和亚马逊早已在自家的云服务器上大规模采用了自研的芯片。此外,为了摆脱英伟达的「卡脖子」,微软还在与AMD密切合作,开发即将推出的人工智能芯片MI300X。不过,微软和其他云服务提供商普遍表示,自己并没有停止从英伟达购买GPU的打算。但如果他们能说服云客户更多地使用自研芯片,那么从长远来看,这可以极大地节省开支。同时,也能帮助他们在与英伟达的谈判中获得更多筹码。 此前,CEO Sam Altman曾将获得更多AI芯片作为公司的首要任务。一方面,OpenAI所需的GPU十分短缺,另外,运行这些硬件时产生的成本「令人瞠目结舌」。如果算力成本一直居高不下,长远来看于整个AI行业来说可能并不是一个好消息。毕竟如果掘金的「铲子」卖的比金子本身都贵,那么还会有人去做挖金子的人吗?根据Stacy Rasgon的分析,ChatGPT每次查询大约需要4美分。如果ChatGPT的查询量增长到谷歌搜索规模的十分之一,那么就将需要价值约481亿美元的GPU,并且每年需要价值约160亿美元的芯片来维持运行。目前还不清楚OpenAI是否会推进定制芯片的计划。据业内资深人士分析,这将是一项投资巨大的战略举措,其中每年的成本可能高达数亿美元。而且,即使OpenAI将资源投入到这项任务中,也不能保证成功。除了完全的自研之外,还有一种选择是像亚马逊在2015年收购Annapurna Labs那样,收购一家芯片公司。
此前,CEO Sam Altman曾将获得更多AI芯片作为公司的首要任务。一方面,OpenAI所需的GPU十分短缺,另外,运行这些硬件时产生的成本「令人瞠目结舌」。如果算力成本一直居高不下,长远来看于整个AI行业来说可能并不是一个好消息。毕竟如果掘金的「铲子」卖的比金子本身都贵,那么还会有人去做挖金子的人吗?根据Stacy Rasgon的分析,ChatGPT每次查询大约需要4美分。如果ChatGPT的查询量增长到谷歌搜索规模的十分之一,那么就将需要价值约481亿美元的GPU,并且每年需要价值约160亿美元的芯片来维持运行。目前还不清楚OpenAI是否会推进定制芯片的计划。据业内资深人士分析,这将是一项投资巨大的战略举措,其中每年的成本可能高达数亿美元。而且,即使OpenAI将资源投入到这项任务中,也不能保证成功。除了完全的自研之外,还有一种选择是像亚马逊在2015年收购Annapurna Labs那样,收购一家芯片公司。 据一位知情人士透露,OpenAI已经考虑过这条路,并对潜在的收购目标进行了尽职调查。但即使OpenAI继续推进定制芯片计划(包括收购),这项工作也可能需要数年时间。在此期间,OpenAI还是将依赖于英伟达和AMD等GPU供应商。因为就算强如苹果,在2007年收购了P.A. Semi和Intristy,到2010年推出第一款芯片A4,也经历了3年的时间。而OpenAI,自己本身都还是一家初创公司,这个过程也许走得会更加艰难。而且英伟达GPU最重要的护城河,就是它基于CUDA的软硬件生态的积累。OpenAI不但要能设计出性能上不落后的硬件,还要在软硬件协同方面赶超CUDA,绝对不是一件容易的事情。
据一位知情人士透露,OpenAI已经考虑过这条路,并对潜在的收购目标进行了尽职调查。但即使OpenAI继续推进定制芯片计划(包括收购),这项工作也可能需要数年时间。在此期间,OpenAI还是将依赖于英伟达和AMD等GPU供应商。因为就算强如苹果,在2007年收购了P.A. Semi和Intristy,到2010年推出第一款芯片A4,也经历了3年的时间。而OpenAI,自己本身都还是一家初创公司,这个过程也许走得会更加艰难。而且英伟达GPU最重要的护城河,就是它基于CUDA的软硬件生态的积累。OpenAI不但要能设计出性能上不落后的硬件,还要在软硬件协同方面赶超CUDA,绝对不是一件容易的事情。 但是,另一方面,OpenAI做芯片也有自己独特的优势。OpenAI要做的芯片,不需要向其他巨头推出的芯片一样,服务于整个AI行业。他只需满足自己对模型训练的理解和需求,为自己定制化的设计一款AI芯片。这和谷歌、亚马逊这种将自己的AI芯片放在云端提供给第三方使用的芯片会有很大的不同,因为几乎不用考虑兼容性的问题。这样就能在设计层面让芯片能更高效地执行Transformer模型和相关的软件栈。
但是,另一方面,OpenAI做芯片也有自己独特的优势。OpenAI要做的芯片,不需要向其他巨头推出的芯片一样,服务于整个AI行业。他只需满足自己对模型训练的理解和需求,为自己定制化的设计一款AI芯片。这和谷歌、亚马逊这种将自己的AI芯片放在云端提供给第三方使用的芯片会有很大的不同,因为几乎不用考虑兼容性的问题。这样就能在设计层面让芯片能更高效地执行Transformer模型和相关的软件栈。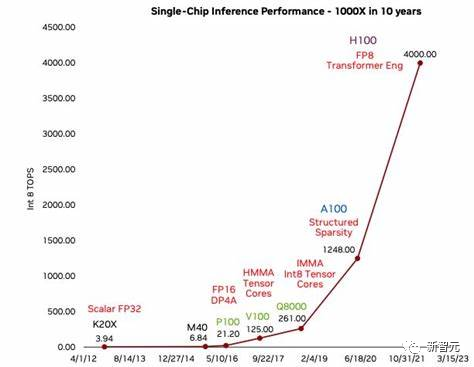 而且,OpenAI在模型训练方面的领先优势和规划,能让它真正做到在未来把模型训练相关的硬件问题,用自己独家设计的芯片来解决。不用担心自己的芯片在「满足自己需要」的性能上,相比与英伟达这样的行业巨头会有后发劣势。
而且,OpenAI在模型训练方面的领先优势和规划,能让它真正做到在未来把模型训练相关的硬件问题,用自己独家设计的芯片来解决。不用担心自己的芯片在「满足自己需要」的性能上,相比与英伟达这样的行业巨头会有后发劣势。 有国外媒体算过这样一笔账:现在,购买一个使用英伟达H100 GPU的人工智能训练集群,成本约为10亿美元,其FP16运算能力约为20 exaflops(还不包括对矩阵乘法的稀疏性支持)。而在云上租用三年,则会使成本增加2.5倍。这些成本包括了集群节点的网络、计算和本地存储,但不包括任何外部高容量和高性能文件系统存储。购买一个基于Hopper H100的八GPU节点可能需要花费近30万美元,其中还包括InfiniBand网络(网卡、电缆和交换机)的分摊费用。同样的八GPU节点,在AWS上按需租用的价格为260万美元,预留三年的价格为110万美元,在微软Azure和谷歌云上的价格可能也差不多。因此,如果OpenAI能够以低于50万美元的单价(包括所有成本)构建系统,那么它的成本将减少一半以上,同时还能掌握自己的「算力自由」。将这些费用削减一半,在投入资源不变的情况下,OpenAI的模型规模就会扩大一倍;如果成本能够减少四分之三,则翻四倍。在模型规模每两到三个月翻倍的市场中,这一点非常重要。所以长远来看,也许任何一个有野心的AI大模型公司,都不得不面对的一个最基本问题就是——如何尽可能的降低算力成本。而摆脱「金铲子卖家」英伟达,使用自己的GPU,永远都是最有效的方法。
有国外媒体算过这样一笔账:现在,购买一个使用英伟达H100 GPU的人工智能训练集群,成本约为10亿美元,其FP16运算能力约为20 exaflops(还不包括对矩阵乘法的稀疏性支持)。而在云上租用三年,则会使成本增加2.5倍。这些成本包括了集群节点的网络、计算和本地存储,但不包括任何外部高容量和高性能文件系统存储。购买一个基于Hopper H100的八GPU节点可能需要花费近30万美元,其中还包括InfiniBand网络(网卡、电缆和交换机)的分摊费用。同样的八GPU节点,在AWS上按需租用的价格为260万美元,预留三年的价格为110万美元,在微软Azure和谷歌云上的价格可能也差不多。因此,如果OpenAI能够以低于50万美元的单价(包括所有成本)构建系统,那么它的成本将减少一半以上,同时还能掌握自己的「算力自由」。将这些费用削减一半,在投入资源不变的情况下,OpenAI的模型规模就会扩大一倍;如果成本能够减少四分之三,则翻四倍。在模型规模每两到三个月翻倍的市场中,这一点非常重要。所以长远来看,也许任何一个有野心的AI大模型公司,都不得不面对的一个最基本问题就是——如何尽可能的降低算力成本。而摆脱「金铲子卖家」英伟达,使用自己的GPU,永远都是最有效的方法。 逼得OpenAI等模型公司造硬件,一个最大的原因是其他芯片公司完全不给力,英伟达几乎没有竞争。如果AI芯片是一个竞争充分的市场,OpenAI这类的公司就不会自己下场做AI芯片。
逼得OpenAI等模型公司造硬件,一个最大的原因是其他芯片公司完全不给力,英伟达几乎没有竞争。如果AI芯片是一个竞争充分的市场,OpenAI这类的公司就不会自己下场做AI芯片。 而有些想法更加激进的网友认为,大语言模型未来将集成到芯片当中,人类可以用自然语言和计算机直接对话。所以设计芯片是走到那一步的自然选择。 来源:新智元
而有些想法更加激进的网友认为,大语言模型未来将集成到芯片当中,人类可以用自然语言和计算机直接对话。所以设计芯片是走到那一步的自然选择。 来源:新智元
微软自研AI芯片,11月上线!知名外媒The Information独家爆料称,微软计划在下个月举行的年度开发者大会上,推出首款人工智能芯片。
同时,OpenAI也在招聘能够帮助其评估和设计AI硬件的人员。业内有一种说法,「卖H100比向沙漠里快要渴死的人卖水还要容易」。不论是为了走出算力枯竭,更高效,低成本地开发自己的模型,还是为了摆脱被「利润率高达1000%」的H100盘剥。微软和OpenAI都在尝试「变硬」,努力戒掉对于英伟达的GPU依赖。但是,根据业内人士爆料,英伟达对于已经推出自己芯片的公司,比如谷歌和亚马逊,会控制GPU的供给。所以「芯片自研」的道路,是一个风险和收益都很高的选择,毕竟谁也不想未来被黄老板在GPU供给上进一步「卡脖子」。微软自研AI芯片,追赶谷歌亚马逊
与英伟达的GPU类似,微软的芯片也是专为数据中心服务器设计,可用于训练和运行诸如ChatGPT这类的大语言模型。
目前,不管是为云客户提供先进的LLM支持,还是为自家的生产力应用提供AI功能,微软都需要依靠英伟达的GPU提供算力的加持。而这款从2019年便开始研发的全新芯片,显然可以极大地减轻微软对英伟达GPU的依赖。据知情人士称,微软和OpenAI组成的联合团队,现在已经在对其进行测试了。相比起早早入局的竞争对手,微软直到2019年才开始AI芯片的研发。也是同年,微软宣布将向OpenAI投资10亿美元,并要求他们必须使用微软的Azure云服务器。然而,当微软开始与OpenAI进行更紧密地合作时发现,依靠购买GPU来支持这家初创公司、Azure客户以及自家产品的成本,实在是太高了。据知情人士透露,在开发Athena期间,微软为了满足OpenAI的需求,已经向英伟达订购了至少数十万块GPU。早在,今年4月,就有消息透露了这款代号为Athena的芯片的存在。据称,微软希望这款代号为Athena(雅典娜)芯片,能与一直供不应求的英伟达H100 GPU相媲美。目前,亚马逊和谷歌已将人工智能芯片作为其云业务营销战略的重要组成部分。其中,亚马逊在对Anthropic的投资中规定,对方需要使用亚马逊的AI芯片,即Trainium和Inferentia。同时,谷歌云也表示,Midjourney和 Character AI等客户使用了自研的TPU。微软虽然还在讨论是否要向Azure云客户提供自研芯片,但该芯片在开发者大会上的首次亮相,可能预示着微软正在寻求吸引未来云客户的兴趣。可以肯定的是,微软将借着Athena的推出,极大缩短与另外两家巨头的距离——谷歌和亚马逊早已在自家的云服务器上大规模采用了自研的芯片。此外,为了摆脱英伟达的「卡脖子」,微软还在与AMD密切合作,开发即将推出的人工智能芯片MI300X。不过,微软和其他云服务提供商普遍表示,自己并没有停止从英伟达购买GPU的打算。但如果他们能说服云客户更多地使用自研芯片,那么从长远来看,这可以极大地节省开支。同时,也能帮助他们在与英伟达的谈判中获得更多筹码。OpenAI:这两家,我都不想要
对于OpenAI来说,能同时减少对微软和英伟达芯片的依赖,显然是最好的。
据OpenAI网站上的几则招聘信息显示,公司正在招聘能够帮助其评估和共同设计AI硬件的人员。路透社也报道,OpenAI正在计划下场生产自己的AI芯片。此前,CEO Sam Altman曾将获得更多AI芯片作为公司的首要任务。一方面,OpenAI所需的GPU十分短缺,另外,运行这些硬件时产生的成本「令人瞠目结舌」。如果算力成本一直居高不下,长远来看于整个AI行业来说可能并不是一个好消息。毕竟如果掘金的「铲子」卖的比金子本身都贵,那么还会有人去做挖金子的人吗?根据Stacy Rasgon的分析,ChatGPT每次查询大约需要4美分。如果ChatGPT的查询量增长到谷歌搜索规模的十分之一,那么就将需要价值约481亿美元的GPU,并且每年需要价值约160亿美元的芯片来维持运行。目前还不清楚OpenAI是否会推进定制芯片的计划。据业内资深人士分析,这将是一项投资巨大的战略举措,其中每年的成本可能高达数亿美元。而且,即使OpenAI将资源投入到这项任务中,也不能保证成功。除了完全的自研之外,还有一种选择是像亚马逊在2015年收购Annapurna Labs那样,收购一家芯片公司。据一位知情人士透露,OpenAI已经考虑过这条路,并对潜在的收购目标进行了尽职调查。但即使OpenAI继续推进定制芯片计划(包括收购),这项工作也可能需要数年时间。在此期间,OpenAI还是将依赖于英伟达和AMD等GPU供应商。因为就算强如苹果,在2007年收购了P.A. Semi和Intristy,到2010年推出第一款芯片A4,也经历了3年的时间。而OpenAI,自己本身都还是一家初创公司,这个过程也许走得会更加艰难。而且英伟达GPU最重要的护城河,就是它基于CUDA的软硬件生态的积累。OpenAI不但要能设计出性能上不落后的硬件,还要在软硬件协同方面赶超CUDA,绝对不是一件容易的事情。但是,另一方面,OpenAI做芯片也有自己独特的优势。OpenAI要做的芯片,不需要向其他巨头推出的芯片一样,服务于整个AI行业。他只需满足自己对模型训练的理解和需求,为自己定制化的设计一款AI芯片。这和谷歌、亚马逊这种将自己的AI芯片放在云端提供给第三方使用的芯片会有很大的不同,因为几乎不用考虑兼容性的问题。这样就能在设计层面让芯片能更高效地执行Transformer模型和相关的软件栈。而且,OpenAI在模型训练方面的领先优势和规划,能让它真正做到在未来把模型训练相关的硬件问题,用自己独家设计的芯片来解决。不用担心自己的芯片在「满足自己需要」的性能上,相比与英伟达这样的行业巨头会有后发劣势。都是成本的问题
设计自己的AI芯片,与英伟达直接「刚正面」如此之难,为什么巨头们还要纷纷下场?
最直接的原因就是,英伟达的GPU太贵了!加上云提供商在中间还要再赚一笔。这样,包括OpenAI在内,使用英伟达GPU+云提供商的基础模型企业成本肯定居高不下。有国外媒体算过这样一笔账:现在,购买一个使用英伟达H100 GPU的人工智能训练集群,成本约为10亿美元,其FP16运算能力约为20 exaflops(还不包括对矩阵乘法的稀疏性支持)。而在云上租用三年,则会使成本增加2.5倍。这些成本包括了集群节点的网络、计算和本地存储,但不包括任何外部高容量和高性能文件系统存储。购买一个基于Hopper H100的八GPU节点可能需要花费近30万美元,其中还包括InfiniBand网络(网卡、电缆和交换机)的分摊费用。同样的八GPU节点,在AWS上按需租用的价格为260万美元,预留三年的价格为110万美元,在微软Azure和谷歌云上的价格可能也差不多。因此,如果OpenAI能够以低于50万美元的单价(包括所有成本)构建系统,那么它的成本将减少一半以上,同时还能掌握自己的「算力自由」。将这些费用削减一半,在投入资源不变的情况下,OpenAI的模型规模就会扩大一倍;如果成本能够减少四分之三,则翻四倍。在模型规模每两到三个月翻倍的市场中,这一点非常重要。所以长远来看,也许任何一个有野心的AI大模型公司,都不得不面对的一个最基本问题就是——如何尽可能的降低算力成本。而摆脱「金铲子卖家」英伟达,使用自己的GPU,永远都是最有效的方法。网友热议
对于OpenAI和微软下场造AI芯片的做法,一些网友似乎持不同的意见,认为AI芯片是一个「陷阱」。
逼得OpenAI等模型公司造硬件,一个最大的原因是其他芯片公司完全不给力,英伟达几乎没有竞争。如果AI芯片是一个竞争充分的市场,OpenAI这类的公司就不会自己下场做AI芯片。而有些想法更加激进的网友认为,大语言模型未来将集成到芯片当中,人类可以用自然语言和计算机直接对话。所以设计芯片是走到那一步的自然选择。 来源:新智元*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
关键词:
OpenAI
相关推荐
全网卸载ChatGPT风暴下,奥特曼终于认错!之前被曝“投机”拿下美军订单
黄仁勋定调:300亿美元注资落地,英伟达拟终结对OpenAI后续投资
Micro Swarm使用一系列Barduino的输入,模仿蝉的和谐叫声
甲骨文与OpenAI终止数据中心项目
OpenAI正在开发类似GitHub的代码平台
微软或将起诉OpenAI、亚马逊
反向带货?牵手美政府后OpenAI遭大面积卸载
OpenAI 巨型 “星门” 数据中心扩建计划告吹
OpenAI与美国战争部达成合作,「投名状」背后的暗流
OpenAI宣布关停Sora生成式AI视频创作工具
OpenAI与甲骨文放弃数据中心扩建计划
在DFRobot ESP32 S3相机上构建DIY语音控制GPT系统