基于时态差分法的强化学习:Sarsa和Q-learning

时态差分法(Temporal Difference, TD)是一类在强化学习中广泛应用的算法,用于学习价值函数或策略。Sarsa和Q-learning都是基于时态差分法的重要算法,用于解决马尔可夫决策过程(Markov Decision Process, MDP)中的强化学习问题。
下面是最简单的TD方法更新:
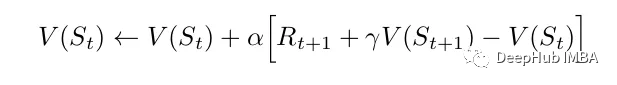
它只使用当前行动之后的奖励值和下一个状态的值作为目标。Sarsa(State-Action-Reward-State-Action)和Q-learning是都是基于时态差分法的强化学习方法。
Sarsa和Q-learning的区别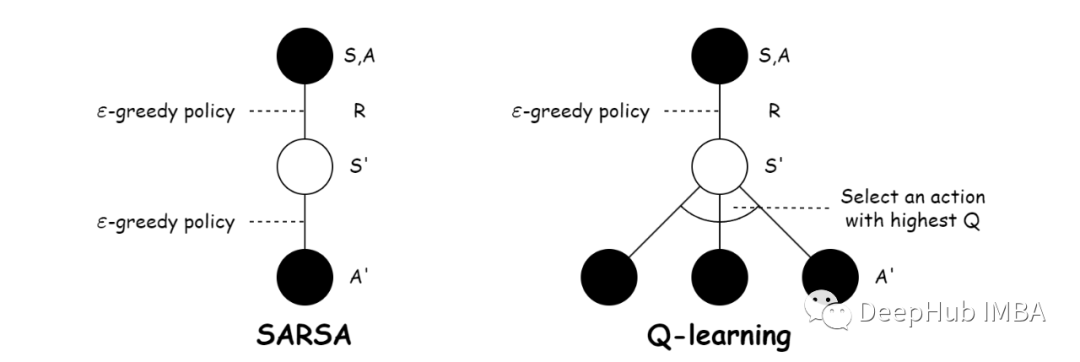
Sarsa代表State-Action-Reward-State-Action。是一种基于策略的方法,即使用正在学习的策略来生成训练数据。Q-learning是一种非策略方法它使用不同的策略为正在学习的值函数的策略生成训练数据。
Sarsa的更新规则如下:
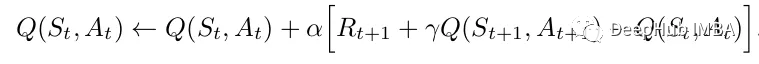
其中:
- Q(s, a) 是在状态s下采取动作a的值函数估计。
- α 是学习率,控制每次更新的步长大小。
- r 是在状态s下采取动作a后获得的即时奖励。
- γ 是折扣因子,表示未来奖励的折现率。
- s' 是在执行动作a后得到的新状态。
a' 是在新状态s'下选择的下一个动作。
Q-learning是另一种基于时态差分法的增强学习算法,用于学习一个值函数,表示在状态s下采取最优动作得到的期望累积奖励。Q-learning的更新规则如下:
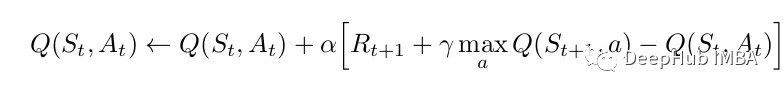
其中:max(Q(s', a')) 表示在新状态s'下选择下一个动作a'时的最大值函数估计。
从上面的更新可以看出这两个方法非常相似,主要区别在于它们的更新策略。在Sarsa中,更新策略考虑了在新状态下采取的下一个动作,而在Q-learning中,更新策略总是选择了新状态下使值函数最大化的动作。因此,Sarsa更倾向于跟随当前策略进行学习,而Q-learning更倾向于学习最优策略。
cliff walking环境下的表现这是RL书中描述的一个简单环境,如下面的截图所示。
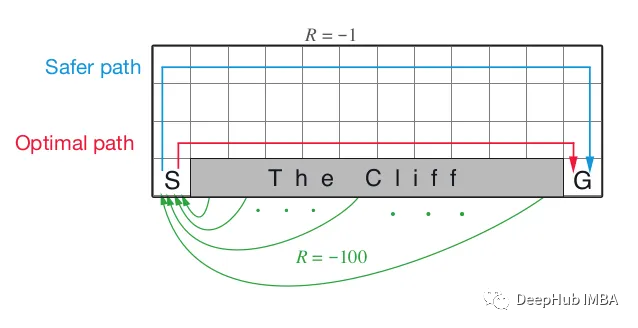
- 事件开始于状态S,我们的代理开始于这种状态。
- 一个事件在状态G结束,也就是这是终态。
- 在S和G之间的最下面一行的状态是悬崖状态。
- 从悬崖状态以外的任何状态转换的奖励为-1,并且代理会移动到邻近的状态。
- 悬崖状的奖励为-100,并且代理移动到开始状态S,也就是说结束了。
- 当代理到达终端状态G,走了100步或者最终处于悬崖状态时,就代表结束了。
- 图中蓝色路径是安全的,但不是最优的,因为它需要很多步才能到达目标状态。
红色路径是最优的,但它是非常危险的,因为代理可能会发现自己在悬崖边缘。
从环境的描述来看,代理的目标是最大化累积奖励,即采取尽可能少的步数,因为每一步的值为-1。最优路径是悬崖上方的那条,因为它只需要13步,值为-13。我使用上面的2td(0)方法来确定它们是否在上面以获得最优路径。
实验环境如下:
在训练中使用以下超参数:
- episodes:2000;
- discounting factor:1;
- Alpha: 0.1,这是学习率;
Epsilon: 0.1, 选择具有相同概率的所有动作的概率,用于ε贪婪算法。
结果:
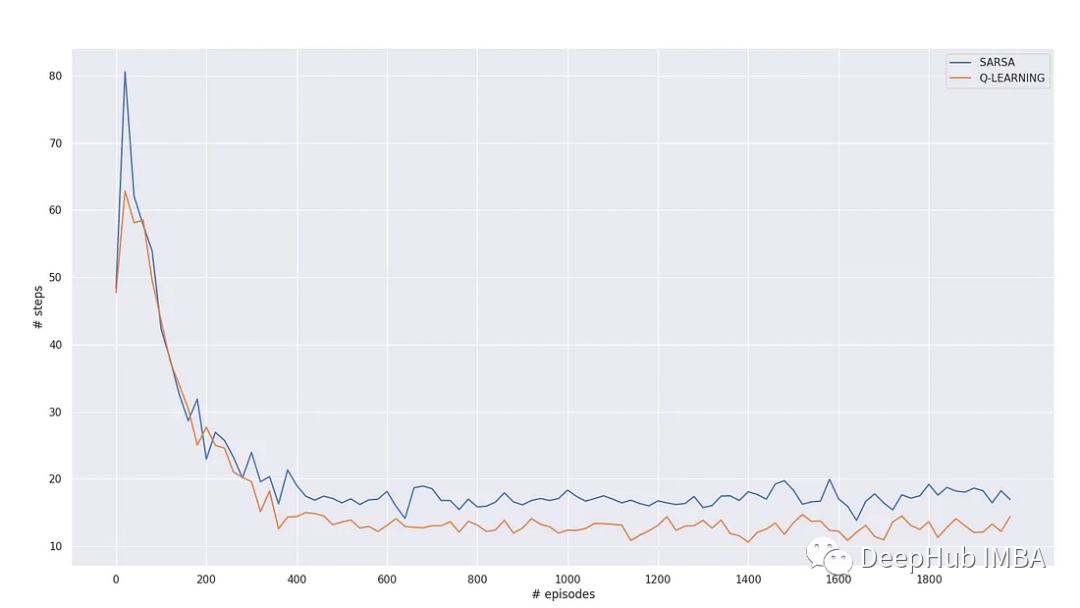
Sarsa和Q-learning在收敛的时间上大致相同,但Q-learning能够学习13个步骤的最优路径。Sarsa无法学习最优路径,它会选择避开悬崖。这是因为它的更新函数是使用贪婪的方式来获取下一个状态-动作值,因此悬崖上方的状态值较低。
Q-learning在更新中使用了下一个状态动作值的最大值,因此它能够小心地沿着边缘移动到目标状态G。下图显示了每个训练论测的学习步骤数量。为了使图表更加平滑,这里将步骤数按20个一组取平均值。我们可以清楚地看到,Q-learning能够找到最优路径。
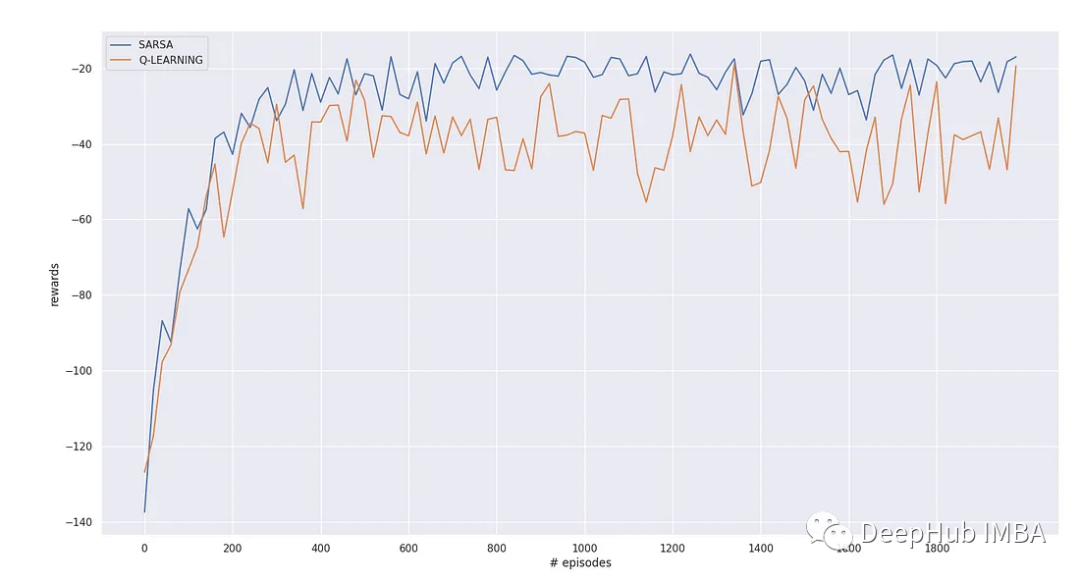
下图显示了2种算法的在线性能*这些值再次以20组为单位进行平均)。我们可以看到,Sarsa的性能比Q-learning更好。这是因为随着Q-learning学习获得最优路径,偶尔会发现自己陷入绝境,因为要更新的状态动作对的生成遵循了贪婪算法。而Sarsa学会了避开靠近悬崖的状态,从而减少了靠近悬崖的机会。
这个简单的例子说明了Sarsa和Q-learning之间的比较,我们总结两个算法的区别:
Sarsa和Q-learning都是基于时态差分法的强化学习算法,它们在解决马尔可夫决策过程(MDP)中的强化学习问题时有一些重要的区别。
更新策略:
- Sarsa:在Sarsa中,更新策略是"状态-动作-奖励-下一个状态-下一个动作",即更新后的动作与下一个状态相关。这意味着Sarsa在更新值函数时会考虑在新状态下采取的下一个动作,因此其学习过程更加稳定,可以学习到策略的各种特征。
Q-learning:Q-learning的更新策略是"状态-动作-奖励-最大值动作",即更新后的动作是在新状态下具有最大值函数估计的动作。这使得Q-learning更加倾向于学习最优策略,但也可能导致其学习过程不稳定,容易受到噪声干扰。
学习方式:
- Sarsa:由于Sarsa在更新时会考虑在新状态下执行的下一个动作,它更适合于在线学习和与环境进行交互时的应用。Sarsa在实际应用中可能更加稳定,但也可能会收敛较慢。
Q-learning:Q-learning更倾向于学习最优策略,但由于其更新策略不考虑实际执行的下一个动作,可能在一些情况下收敛更快,但也更容易受到噪声的影响。
探索策略:
- Sarsa:由于Sarsa考虑了在新状态下执行的下一个动作,它在学习过程中倾向于跟随当前策略进行探索,可能更适合于需要较多探索的任务。
Q-learning:Q-learning在更新时不受当前策略的影响,更容易在学习过程中进行探索。然而,这种无关探索策略可能导致Q-learning在某些情况下过度探索,陷入不收敛的状态。
应用场景:
- Sarsa:适用于需要稳定学习过程、重视探索的任务,或者在与环境进行交互时进行在线学习的情况。
Q-learning:适用于倾向于学习最优策略的任务,或者在需要快速收敛时的情况。
这两种算法只是强化学习领域众多算法中的两种,还有其他更高级的算法如Deep Q Network (DQN)、Actor-Critic等,可以根据问题的复杂度和要求选择适当的算法。
最后如果你想自行进行试验,这里是本文两个试验的源代码:
https://github.com/mirqwa/reinforcement-leaning
作者:Kim Rodgers
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
相关推荐
尼吉康的事业介绍
电子元件培训教材
AI正在成为美国军事系统核心
WTC-AI型太阳能热水器电路图
边缘 AI 加速的 Arm® Cortex®‑M0+ MCU 如何为电子产品注入更强智能
赋能AI与新能源时代的高动态MW级负载平台
继上次海联达Ai-ap100拆机之电源改造
海联达(Aigale)Ai-HD1 无线全高清套件拆解
基于Microchip MCU的AI/ML培训教程3
Gartner发布三大AI价值实现路径
CSR8670CSR8675智能语音Alexa蓝牙方案开发
基于Microchip MCU的AI/ML培训教程2
英伟达 Groq 3:AI 推理时代已至
瑞萨电子AI单元解决方案成功提高GE医疗(日本)日野工厂的生产力
芯片互连初创企业Kandou AI完成2.25亿美元融资
基于Ai-WB2-12F与Rd-04的雷达检测系统
释说芯语16:硬科技:构建企业未来之路(附PPT)
WTC-AI太阳能热水器电路图
基于Microchip MCU的AI/ML培训教程1
EEPW2018年3月刊(工业物联网)
尽管与亚马逊达成芯片合作,英伟达股价仍下跌 3%,油价与加息担忧冲击 AI 交易
EEPW2018年6月刊(5G)
iCAN-4017 AI功能模块
AI狂潮 半导体通膨压力重重
PowiGaN for AI Data Centers: Unmatched Power Density and Reliability
万家乐JSYZ5-AI燃气热水器电路图
TI 携手 NVIDIA 推出面向下一代 AI 数据中心的完整 800 VDC 电源架构
人工智能是如何帮助阻止造假者的?
在工业自动化和智能家用电器设计中实现支持边缘 AI 的电机控制
基于VisitionX制造智能眼镜