基于多特征SVMs分类器的手语识别*
——

(4)生成SIFT特征向量。 首先将坐标轴旋转为关键点的方向,以确保旋转不变性。接下来以关键点为中心取8×8的窗口。然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点。手语字母图像的SIFT特征提取如图2所示。
本文引用地址:https://www.eepw.com.cn/article/93422.htm
图2 (a)手语字母J原图 (b)对(a)提取SIFT特征向量
实验
本文从视频中采集了中国手语字母表中的30个手语字母的图像,30组,每组图像195幅,共5850幅图像作为实验图像。每组的前50幅作为正例训练样本,从其他29组中各选取5幅共145幅作为反例训练样本。每类图像除选作正例的50图像外,剩余的145幅作为测试图像。实验中首先提取图像的7维不变矩特征量,48维Gabor纹理特征,128维SIFT特征作为图像全局和局部特征描述。然后分别采用两种不同核函数(Linear kernel, Radical Basis Function)的SVMs分类器进行训练,对中国手语字母表中的30个手语字母图像的识别结果如表2所示。
表2 30个中国手语字母的识别结果
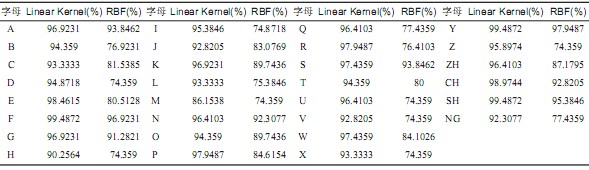
基于线性核函数的SVM平均识别率为95.556%,基于径向基核函数的SVM平均识别率为83.1282%。实验表明,采用径向基核函数的SVM识别率普遍低于采用线性核函数的SVM。


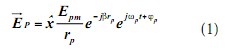

评论