ASIC市场,越来越大了

这一点早已达成业内共识。但令人意外的是,ASIC 增长的速度实在是太快了。摩根士丹利预计,AI ASIC 市场规模将从 2024 年的 120 亿美元增长至 2027 年的 300 亿美元,年复合增长率达到 34%。
本文引用地址:https://www.eepw.com.cn/article/202506/471150.htm要知道 2023 年—2029 年,高性能计算 GPU 市场的年复合增长率是 25%,而 CPU 和 APU 的增长率仅为 5% 和 8%。
ASIC 市场,蛋糕膨胀
TrendForce 的最新研究报告指出,随着人工智能服务器需求的迅猛增长,美国主要的云计算服务提供商(CSP)正加快内部开发专用集成电路(ASIC)芯片的步伐,平均每 1 至 2 年便推出新一代产品。在中国,人工智能服务器市场正逐步适应美国自 2025 年 4 月起实施的新出口管制政策。据预测,这些措施将导致 2025 年进口芯片(如 NVIDIA 和 AMD 产品)的市场份额从 2024 年的 63% 下降至约 42%。
与此同时,在政府积极推动国产人工智能处理器的政策扶持下,预计中国本土芯片制造商的市场份额将提升至 40%,与进口芯片的市场份额几乎持平。
定制芯片是一种经济选择,而不是技术选择。ASIC 蛋糕增长最重要的驱动力只有一个:钱。
从当前来看,GPU 服务器依然是最终用户的首要选择,但由于部分 GPU 产品受供应的限制,导致出现了算力缺口。很多头部的互联网企业,为了降低成本以及更好地适配自身业务场景,也增大了自研 ASIC 芯片服务器的部署数量。
比如在同等预算下,AWS 的 Trainium 2(ASIC 芯片)可以比英伟达的 H100 GPU 更快速完成推理任务,且性价比提高了 30%~40%。明年计划推出的 Trainium3,计算性能更是提高了 2 倍,能效提高 40%。
云解决方案提供商正在优先考虑 ASIC 开发,以减少对 NVIDIA 和 AMD 的依赖,更好地控制成本和性能,并增强供应链灵活性。这种转变对于管理不断增长的 AI 工作负载和优化长期运营支出至关重要。
此外,如果芯片可以带来战略优势,那么 ASIC 就是有意义的。苹果就是一个很典型的例子,当然也有谷歌。
ASIC 的典型代表:TPU
厂商对能效比和成本的追求是永无止境的,国外大厂中谷歌、亚马逊、Meta、OpenAI 等大型云计算和大模型厂商均加速布局定制化 ASIC。国内企业中寒武纪、达摩院、百度、腾讯等都在推出自己的 ASIC 芯片。
市场主流的 ASIC 芯片有 TPU、NPU、VPU 芯片。
谷歌的 TPU 作为 ASIC 已经非常典型的代表了。这是谷歌在 2016 年推出的首款产品,目标是为了高效地处理张量运算。
最新的 TPU 在今年 4 月发布,谷歌已经推出了第七代张量处理单元(TPU)Ironwood。谷歌称,在大规模部署的情况下,这款 AI 加速器的计算能力能达到全球最快超级计算机的 24 倍以上。
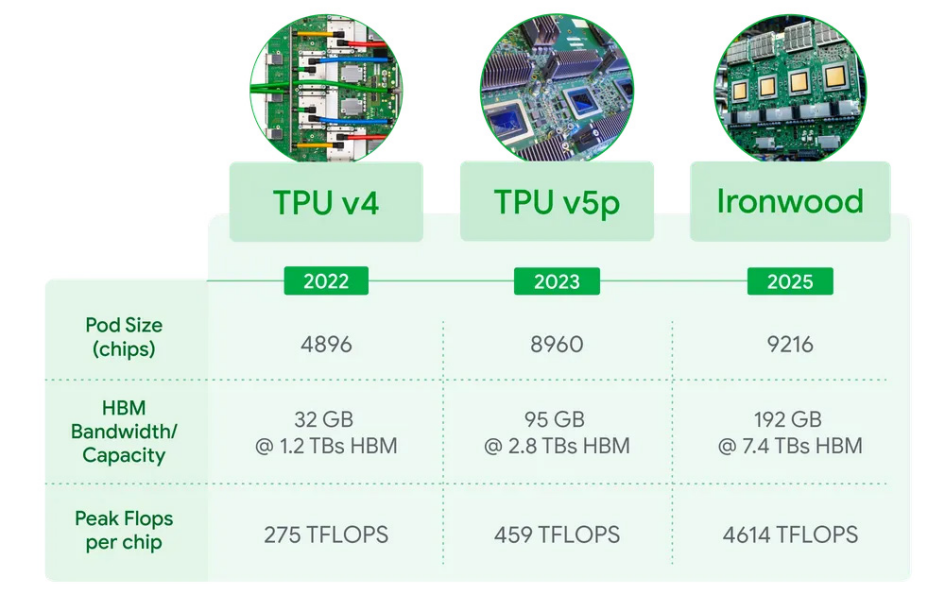
Ironwood 拥有超模的技术规格,当每个 pod 扩展至 9216 块芯片时,它可提供 42.5 exaflops 的 AI 算力,远超目前全球最快的超级计算机 El Capitan 的 1.7 exaflops。每块 Ironwood 芯片的峰值计算能力可达 4614 TFLOPs。
在单芯片规格上,Ironwood 显著提升了内存和带宽,每块芯片配备 192GB 高带宽内存(HBM),是去年发布的上一代 TPU Trillium 的六倍。每块芯片的内存带宽达到 7.2 terabits/s,是 Trillium 的 4.5 倍。
目前,TPU 芯片已经成为全球第三大数据中心芯片设计厂商,据产业链相关人士透露,谷歌 TPU 芯片去年的生产量已经达到 280 万~300 万片之间。
国内这边布局 TPU 芯片的企业是中昊芯英。创始人杨龚轶凡曾在谷歌 TPU 核心研发团队参与过 TPU v2/3/4 的设计与研发工作。
2024 年,中昊芯英创始人及 CEO 就曾对外透露,2023 年中昊芯英成功实现了全自研的专为 AI 训练而生的中国首枚高性能 TPU 训练芯片「刹那」的量产交付。
据悉,「刹那」作为一款全自研的 GPTPU 架构 AI 训练芯片,拥有完全自主可控的 IP 核、全自研指令集与计算平台。在处理大规模 AI 模型训练和推理任务时,「刹那」的计算性能超越英伟达 A100,系统集群性能更是十倍于传统 GPU,在完成相同训练任务量时的能耗仅是传统 GPU 的一半。相比国外产品,「刹那」芯片的单位算力成本仅为其 42%。
ASIC,竞争不断
在 ASIC 市场,目前博通以 55%~60% 的份额位居第一,Marvell 以 13%~15% 的份额位列第二。
博通在 AI 芯片领域的核心优势在于定制化 ASIC 芯片和高速数据交换芯片,其解决方案广泛应用于数据中心、云计算、HPC(高性能计算)和 5G 基础设施等领域。
最新的财报来看,博通 2025 财年第一季度财报显示,其营收达 149.16 亿美元,同比增长 25%;非 GAAP 净利润 78.23 亿美元,同比激增 49%。其中,AI 相关收入 41 亿美元,同比增长 77%,占总营收的 28%,在半导体业务中占比更高达 50%。
博通的 ASIC 芯片业务已成为其核心增长点。财报披露,定制 AI 芯片(ASIC)销售额预计占第二季度总 AI 半导体收入的 70%,达 308 亿美元(约合 450 亿美元)。
博通有两个大合作备受关注:第一是 Meta 与博通已合作开发了前两代 AI 训练加速处理器,目前双方正加速推进第三代 MTIA 芯片的研发,预计 2024 年下半年至 2025 年将取得重要进展。
第二是 OpenAI 已委托博通开发两代 ASIC 芯片项目,计划于 2026 年投产,将采用业界领先的 3nm/2nm 制程工艺并搭配 3D SOIC 先进封装技术。与此同时,虽然苹果目前仍在使用谷歌 TPU,但其自研 AI 芯片项目已在积极推进中。
Marvell 的定制芯片(ASIC)业务正成为其强劲增长的核心动力之一。Marvell 的具体业务中,数据中心业务占据 75% 左右,属于高成长业务。这部分业务包括 SSD 控制器、高端以太网交换机(Innovium)及定制 ASIC 业务(亚马逊 AWS 等定制化芯片),主要应用于云服务器、边缘计算等场景。
Marvell 从 2018 年起陆续收购了 Cavium、Innovium 等公司,从而增强了公司 AISC 及数据中心的相关能力。
最新的财报显示,Marvell 在 2026 财年第一季度的数据中心业务实现营收 14.4 亿美元,环比增长 5.5%,符合市场预期(14.4 亿美元)。
根据公司交流及产业链信息推测,Marvell 当前的 ASIC 收入主要来自亚马逊的 Trainium 2 和谷歌的 Axion Arm CPU 处理器,而公司与亚马逊合作的 Inferential ASIC 项目也将在 2025 年(即 2026 财年)开始量产。公司与微软合作的 Microsoft Maia 项目,有望在 2026 年(即 2027 财年)。
但主要指出的是,不同于 NVIDIA 拥有诸如「主权 AI」、「创业公司爆发」等更具吸引力的故事,Marvell 的定制 AI 芯片依然局限于核心 CSP(云服务提供商)的投资节奏中。
鉴于本季度四大云厂商资本开支整体下滑的趋势,即使 Marvell 通过竞争赢得了更多市场份额,但市场总量的缩减仍是不可忽视的事实。
国内企业也在积极研发 ASIC。
寒武纪科技还在扩展其思元(MLU)芯片系列(比如 7nm 工艺的思元 370、训练芯片思元 290),以支持云端的 AI 训练和推理。主要客户包括:手机端(华为曾是其大客户)、智算中心(政府订单)、服务器厂商(浪潮、联想)等。
同时,国内提供云服务的企业,实际上也推出了自研的 ASIC 芯片。
阿里巴巴推出了含光 800,作为一款云端 AI 推理芯片,峰值性能为 7.8 万 IPS(每秒能处理 7.8 万张照片),峰值能效达到 500IPS/W。在当时,阿里宣称是全球最高性能的 AI 推理芯片,一块含光 800 相当于 10 块 GPU。
百度在量产昆仑芯二代后,又在今年宣布百度智能云成功点亮了首个自研万卡集群。并且宣布是使用的昆仑芯三代 P800。P800 显存规格优于同类主流 GPU20%~50%,对 MoE 架构更加友好,且率先支持 8bit 推理,单机 8 卡即可运行 671B 模型。正因如此,昆仑芯相较同类产品更加易于部署,同时可显著降低运行成本,轻松完成 DeepSeek-V3/R1 全版本推理任务。自研的低成本,使得百度智能云平台上,DeepSeek R1 和 V3 的官方价格直接低至五折和三折,基本实现全网最低。
腾讯除了自主研发的紫霄推理芯片外,还通过战略投资,利用 Enflame 的 ASIC 解决方案。据了解,腾讯自研 AI 推理芯片「紫霄」,已经量产并在多个头部业务落地,目前在腾讯会议实时字幕上已实现全量上线,单卡紫霄机器负载可达到 T4 的 4 倍,并将超时率从 0.005% 降低至 0。
结语
ASIC 市场的增长,也带来了新的挑战。
一个公司想要节省几美元的供应商利润,进行芯片自主设计。但现在芯片设计也并不是一个廉价的商品,尤其是先进芯片设计,已经变得非常昂贵。
台积电 2nm 每片晶圆约 30,000 美元,到了 2nm 之后的 1.4nm 成本甚至达到 45,000 美元。
我们需要思考的是,我们真的每个公司都需要自己的 CPU 吗?






评论