使用多通道体系结构优化LPDDR4的性能和功耗

tRC定时会导致很多问题,尤其是在更快的器件中更是如此。在LPDDR4的最高速度下,tRC时间超过100时钟周期。当在LPDDR4的最高速度下工作时,触发Bank中的某一行后,至少在100时钟周期内,tRC会阻止访问该Bank中的其他行,这样,就会在相当长的时间内禁止再次使用该Bank。如果具有更多的可用Bank,会降低访问因tRC时间而锁定的Bank中新行的访问概率。
tRRD和tFAW会限制频繁更换存储体Bank的能力,设计团队可能希望这样做,以避开tRC定时参数。
图12显示了1个器件示例,它具有4个激活窗口tFAW,具有4倍的行行延迟tRRD。在LPDDR4-3200中,tRRD时间可达16个时钟周期。
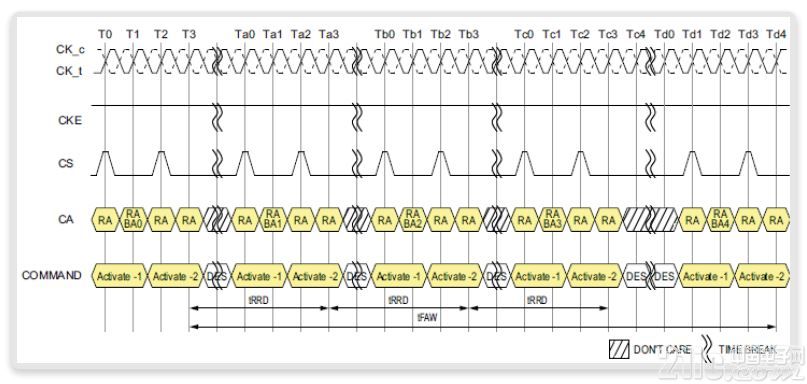
图12:tFAW和tRRD时序
在图13中,显示了在并行实施方案下执行的连续传输序列。符号AC/BA0是Bank0触发命令的代称。与其相邻的命令RD/BA4指的是对Bank4的读取命令(假定Bank4已在较早时间触发)。每一命令标记代表4时钟周期,原因在于LPDDR4器件的4相寻址特性。在实际应用中,该序列会需要延长,这是因为在激活(Active)之后会接着读取、激活、读取、激活、读取、激活、读取。数据返回,完全占用DQ总线,总线处于满状态。并行访问模式会利用100%的内存带宽,但仅在800MHZ(DDR1600)下访问器件时才能实现该点。
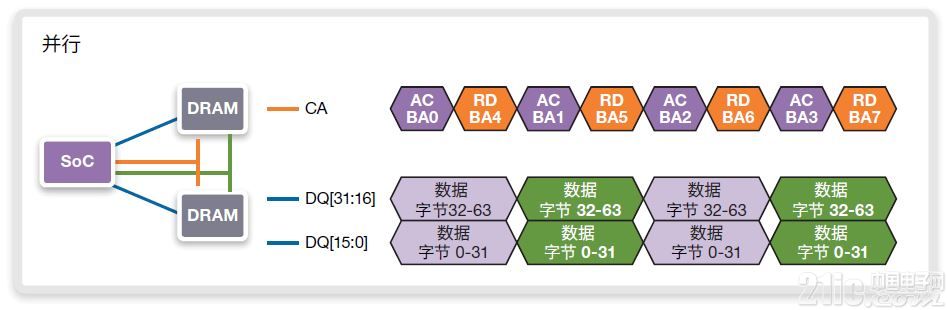
图13:在BL16和800MHz/DDR1600上使用至旋转地址的连续64字节读取的并行实施
图14中显示了一种双通道实施,其中执行了相同的序列,独立使用每一命令地址通道。每一命令地址总线的访问模式略有差异:激活、读取、无操作、读取、激活、读取、无操作、读取。命令通道中的空隙可用于其他方面,如设定的预充或按bank刷新,或简单地留作空闲时钟周期。图中数据总线已被完全占用。
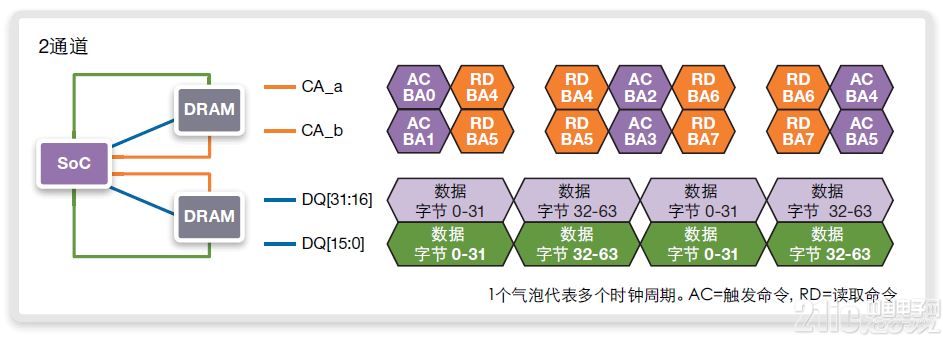
图14:在BL16和800MHz/DDR1600上使用至循环地址的连续64字节读取、独立使用命令地址的双通道实施
将频率加倍至1600 MHz(DDR 3200操作)(图15)时,tRRD时间会限制SOC的能力,允许在并行实施的上方示例中发送激活命令至LPDDR4器件。序列为:激活、读取、无操作、无操作、激活、读取、无操作、无操作。无操作周期可用于预充或刷新,但内存的激活速度不足以就每一传输向新rank发送连续的64-bank传输。
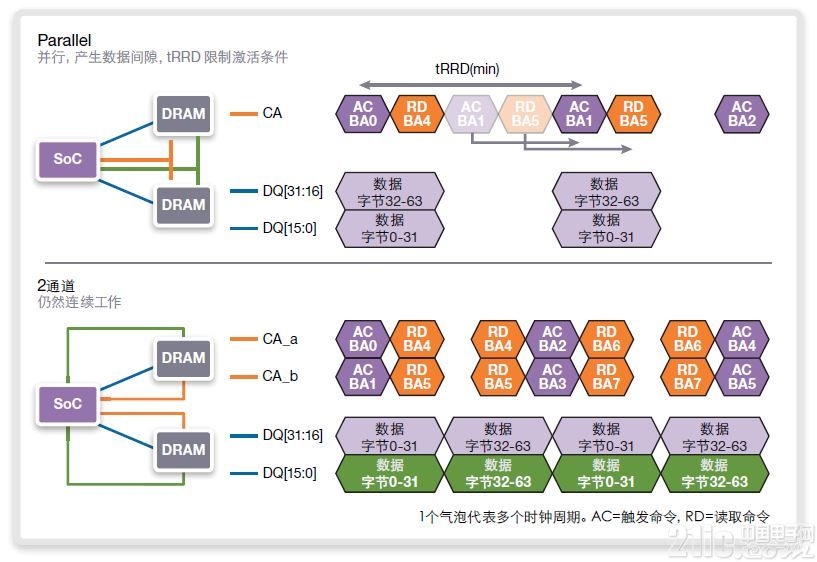
图15:频率加倍至1600MHZ/DDR3200
当没有发向同一内存页的另一64字节传输时,SOC必须等待,直至tRRD期满并能再次在内存中触发新页为止。如果传输的时间不足以在移动至新bank之前对每一bank进行两次读取,该工作模式会将器件的最大性能限制在50%带宽下。
与之相比,对于图15下方的双通道实施,由于“激活、读取、无操作、读取”模式,允许每一通道满足tRRD的要求。即使在DDR 3200数据率下,总线带宽也能工作在满负荷下。
找出最小的块提取大小
块提取大小指的是可在一个DRAM事务(一次突发传输)中传输的最小字节数。由于LPDDR4的最小突发长度为16,采用LPDDR4的并行连接可能使SoC具有不优化的块提取大小。
最佳方式是使提取大小与SOC匹配,不仅体现在通过总线传输的传输大小方面,也体现在器件的总带宽方面。
对于很多SOC和CPU的缓存线,首选块取大小是32字节。在偶尔情况下,一些较大的64位CPU使用64字节缓冲线。视频和网络传输通常需要32字节或更小的短字节传输。在理想情况下,多通道体系结构应与系统的提取大小匹配,以便将系统优化至系统所能使用的提取大小。
在图16显示的并行实施方案中,LPPDDR4最小突发长度为16,有64个的并行DQ引脚,块提取大小为128字节,它实际上仅适合于至连续地址的长数据传输。对于每次以128字节为单位的访问,并行实施方案能够工作,然而,如果数据访问小于128字节且需访问随机地址,那么并行实施方案的效率不高。
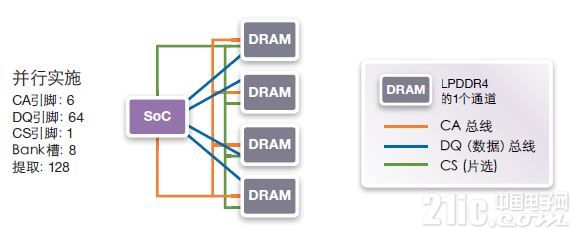
图16:并行实施
对于64位并行实施方案,另一问题是SOC和DRAM裸片之间的物理连接。LPDDR4 PoP封装的管脚分配是每一角一个通道,使得封装包上有4个通道以容纳2或4个裸片。每一通道位于器件的每一角。在理想情况下,SOC内存控制器和PHY布局应与LPDDR4的管脚分配匹配。采用该布局,允许将通道A映射到通道A,通道B映射到通道B,C到C,D到D,使得LPDDR4 PoP封装内的路径尽可能短,无交叉。该封装布局还有助于并行4通道LPDDR4接口的物理实现。
用户还应注意传输是否访问内存中的不同页,tRRD可能会限制较高频率下的有效带宽,如同前述部分中介绍的那样。
正是由于这些原因,与4通道实施相比,设计者更倾向于选择LPDDR4的多通道实施。
命令/地址总线
LPDDR4具有很窄的命令/地址总线(每通道仅6位宽,DDR4为20位或以上),因此,使用多个命令/地址通道的开销低于使用其他DDR类型的开销。在LPDDR4封装包上独立使用所有4个命令/地址总线,能够提供最大的灵活性,可能还会为整个系统提供最高性能。
LPDDR4 PoP的SOC分割
有多种适用于LPDDR4的SOC分割方式。图17显示了最简单的一种方式。这是一种同构CPU体系结构,它具有4个CPU和4个通道。每一CPU具有自己的方式以访问自己的独立通道。该体系结构具有下述优点:CPU不会彼此屏蔽,SOC总线更短。可关闭未使用通道以便节省功耗。
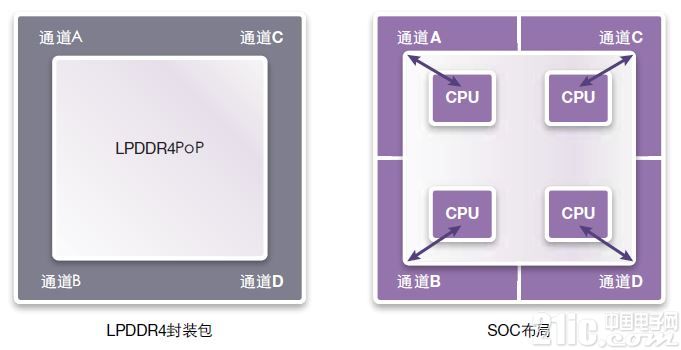
图17:LPDDR4.PoP的最简单SOC分割
然而,该体系结构不够灵活。如果通道A需使用通道C中的一些数据,它无法将内存当作邮箱使用。必须通过SOC以某种方式传输数据。这还会使得CPU更难于执行与负载平衡相关的共享任务。
另一方法是使每一CPU共享每一内存(图18)。这样就能实现更加灵活的分割。对于异构处理,它的工作表现更好,CPU能够对共享数据进行处理,但需要更多和更长的片上布线资源,这可能需要用到复杂的片上互联系统。这样就能更准确地反映实际芯片的工作方式,尤其是对具有不同CPU、GPU和其他处理单元的异构体系结构而言。
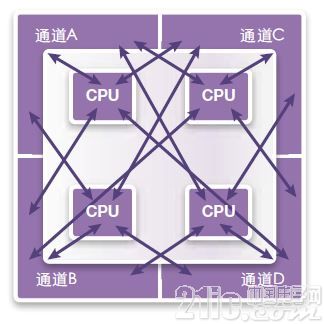
图18:共享通道,所有CPU共享所有内存
逻辑至物理地址映射
多通道体系结构提供了多种控制逻辑至物理地址映射的选择。考虑如图19所示的双通道体系结构。存在多种控制逻辑至物理地址映射的方式。最简单的方式是,双通道存储器映射到不同的SoC地址空间(图19)。
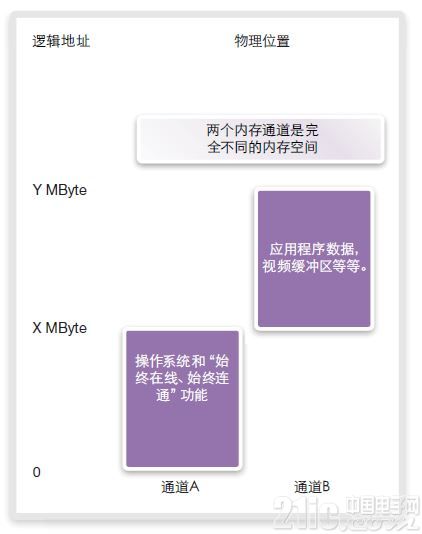
图19:使用分区内存映射的逻辑至物理地址映射
例如,通道A可能会存放操作系统,并保持始终在线、始终连通的功能。通道B可能包含应用数据,视频缓冲和类似数据。这两个不同的地址空间独立且分离。这有助于功耗控制,原因在于,通道B可在不使用时关闭。
另一方式是,采用较小的连续逻辑地址区访问内存的不同通道(图20),对内存映射进行交织处理。例如,通道A为字节0~63,通道B为字节64~127,以此类推,直至遍及整个内存空间。在整个内存上对逻辑空间进行交错处理。该方法有助于在2个不同通道上实现负载平衡,可实现良好性能。然而,由于始终需要两个通道,无法关闭任一通道以降低功耗。

图20:交错式内存映射
更进一步的实施方案是使用混合内存映射(图21),其中,每一通道中的不同区可提供交织式访问或非交织访问。该混合方法可能包含一个始终在线、始终连接的内存区,以便获得最高性能而在2个通道之间交织的内存区,以及用于程序存储的高地址内存区,这类程序与高带宽相关。
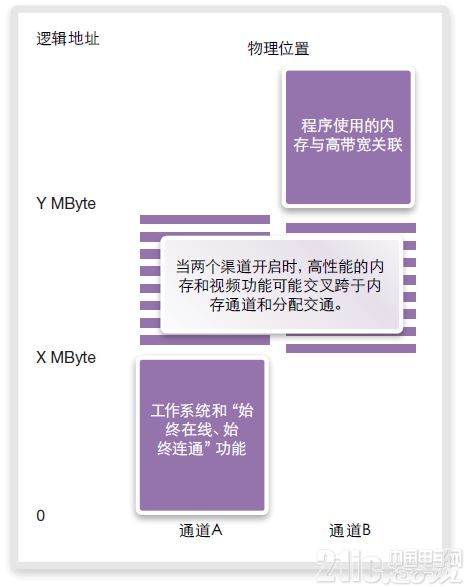
图21:混合内存映射
针对高性能、低功耗移动SOC的Synopsys LPDDR4 IP解决方案
Synopsys完整的LPDDR4 IP解决方案包括1个内嵌I/O的LPDDR4 multiPHY,增强型通用DDR内存控制器(uMCTL2)和协议控制器(uPCTL2),验证IP,建模工具,以及IP硬化和信号完整性分析服务。IP完全支持LPDDR4标准,并可灵活配置,以发挥上文所述的多通道体系结构的优点。
Synopsys DDR内存控制器包含uMCTL2内存控制器,它提供了与SOC的多端口或单端口连接。可用总线包括1~16端口的AXI3、AXI4或AHB。对于需要在内存控制器之外做内存传输调度的系统,我们提供了单端口协议控制器uPCTL2。
uMCTL2具有低延迟、高带宽和强大的QOS特性,包括QOS驱动的仲裁和高性能内存调度算法。内存控制中的低功耗功能具有自动的特点,允许设计团队将重心放在系统设计方面。他能够支持包括DDR2、DDR3、DDR4、LPDDR2、LPDDR3和LPDDR4等多种内存标准。对于车载应用和其他高可靠性系统,IP提供了多种可靠性、可用性、可服务性(RAS)特性。
面向LPDDR4的uMCTL2内存控制器提供了一种基于CAM的调度架构,尤其针对2667-4266的数据率进行了优化,并支持多种地址映射机制,为不同使用模式和多内存类型的系统提供了高度灵活性。它具有自动断电功能,自刷新功能以及快速频率转换功能,支持自动温度监测和刷新率调节。
结论
LPDDR4多通道规范为新颖的系统设计提供了新的机会,尤其是多通道体系结构可以改善系统性能。设计团队需要综合考虑性能、功耗和设计复杂度来部署实施LPDDR4架构。





评论