视频监控落地四要素:预测、检测、报警及定位

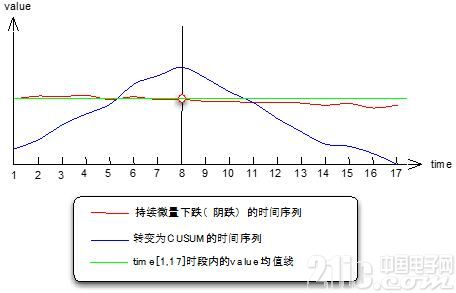
图4 均值漂移原理
从上图可以看到,均值漂移模型的算法原理,实际上是把程序不容易识别的阴跌趋势,转换成CUSUM时间序列,它的趋势很明显,在变点左侧单调增、右侧单调减,CUSUM时间序列描述了被监测时间序列每个点偏离均值的累积变化量,它的规律是从S0=0开始,到Sn=0结束,变点两侧单调变化。
CUSUM=Cumulative Sum。累积和用以在某个相对稳定的数据序列中,检测出开始发生异常的数据点。累积和最典型的应用是在“改变检测”(Change Detection)中对参量变化的检测问题转化了以后,用程序求CUSUM序列上每个点的一阶导数,从持续增变为持续减即可判定为变点,至于持续增、减多少个点,由自己来设定。
关于变点检测使用的mean-shift模型,大家可以去网上找找paper,我这台电脑上找不到了,上面主要说明了发现变点的原理,通俗地讲,就是把问题转化成程序容易解决的状态阴跌线程序不容易量化衡量、判断,那么就用CUSUM控制图里的“富士山”形状去寻找,这是我个人的通俗解释。
上面说到我们使用CUSUM序列上每个点的一阶导数来判断拐点(变点)是否到来,其实图上这个例子是比较理想的情况,在我应用mean-shift模型时,遇到了一些复杂情况,比如这个图上就一个“山头尖”,但是也时候会有多个,这种情况下就要再次转化问题,比如可以把CUSUM再差分,或者以我们的做法,记录一阶导数的状态值,从连续N个正值变为持续N个负值时可以判定。
另外,变点检测的算法实现我这里不方便详细说明,其中变点在反复迭代时自己可以根据实际情况设定迭代次数和置信度,有助于提高变点发现的准确性。
4、智能全景
变点检测弥补了动态阈值对细微波动的检测不足,这两种方式结合起来,基本可以达到不漏报和不误报的平衡,同时也不需要人工长期维护,这是智能全景监控的基础。当监控的人力成本节省了以后,理论上我们可以依赖智能监控无限制的开拓监控视野,并将这些监控报警连结起来分析。
监控项的自动发现规则,比如对维度D的指标M做实时监控,维度D下可能由1000种维度值,而且是不断变化的1000种,如何让程序自动维护监控项?你可以制定一个规则,比如指标M>X则认为需要监控(毕竟不是所有的都需要监控报警,至少在目前故障定位处理没有完全自动化的状况下,报警处理也是需要一定人力的)。在满足M>X的条件下,为了提高报警准确性,我们还需要根据重要性区分报警灵敏度,也就是对于宏观、核心的维度值我们希望能够非常灵敏的监控波动,而对于非重要的维度值我们预测阈值可以宽松一些,这些可以通过上面说的阈值参数来设定。
(说明:这个规则我这里只是举一个例子,各位同仁可以根据自己的实际场景去实现一些规则,比如系统运维层面的监控,有些是按照距离故障发生的速度或风险系数来判断,那么就可以围绕这种指标来制定,假如是对磁盘利用率的监控,就是容量增长速度与剩余资源比例作为参考等等)
以上条件都满足了之后,智能全景监控基本可以运行,不过我们也曾遇到一些其他的问题,比如业务方需要接入监控,但是不一定是必须要我们解析日志,他们有自己的数据,可能是数据库、接口返回、消息中间件里的消息等等。所以,我们在数据接入上采用分层接入,可以从日志标准输出格式、存储的时间序列schema约定、阈值预测的接口三个层次接入使用,这个内容将在下一次分享时由我的同事单独介绍。这里之所以提到,是因为全景监控接入的数据比较多,所以接入途径要有层次、灵活性。
5、辅助定位
报警的最终目的是减少损失,所以定位问题原因尤为重要。Goldeneye尝试着用程序去执行人工定位原因时的套路,当然这些套路目前是通过配置生成的,还没有达到机器学习得出来的地步,不过当业务监控指标接入的越来越多,指标体系逐渐完善以后,通过统计学的相关性分析,这些套路的生成也有可能让程序去完成。这里我介绍一下,程序可以执行的人工总结处的几个套路。
(1)全链路分析
从技术架构、业务流程的角度,我们的监测指标是否正常,从外部因素分析,一般会受到它的上游影响。按照这个思路,逐一分析上游是否正常,就形成了一条链路。这种例子很多,比如系统架构的模块A,B,C,D,E的QPS。
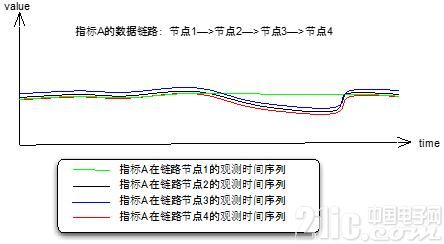
图5 全链路tracing
(插一句,全链路分析有两种数据记录方式,要么链路每个节点内部透传,拼接成完整链路处理信息记录到最终的节点日志;要么异步地每个节点各自将信息push到中间件)
(2)报警时间点上发生了什么?
这是收到监控报警后大多数人的反应,我们把运维事件、运营调整事件尽可能地收集起来,将这些事件地散点图和监测报警的控制图结合起来,就能看出问题。如果程序自动完成,就是将事件发生的时间点也按相同的方式归一化到固定周期的时间点,检查与报警时间点是否吻合。
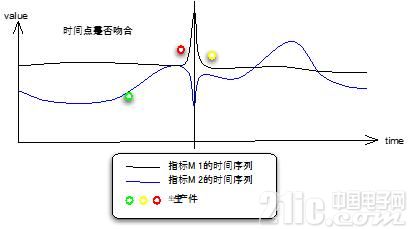
图6 生产事件与时间序列
(3)A/B test或TopN
有些人定位问题,使用排除法缩小出问题的范围。比如在维度D上指标M有异常波动,可以将D拆分成D1,D2,D3来对比,常见的具体情况比如机房对照、分组对照、版本对照、终端类型对照等等,如果在监测数据层级清晰的基础上,我们可以一层一层的钻取数据做A/B test,直到定位到具体原因。还有一种方式,不是通过枚举切分做A/B test,而是直接以指标M为目标,列出维度D的子维度D1,D2,D3,……中指标M的TopN,找出最突出的几项重点排查。
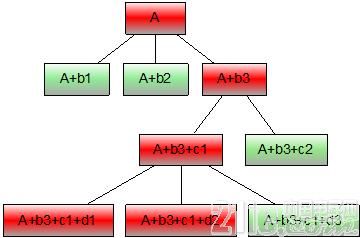
图7 A/B test or TopN
topn也是类似的。大家可以也能看出来,智能监控和辅助定位是需要一个清晰的数据层级和元数据管理系统来支撑的,这一点很基础。
(4)关联指标
不同的指标在监控中都是持续的时间序列,有些指标之间是函数关系,比如ctr=click/pv,click和pv的变化必然带来ctr的变化,这种联系是函数直接描述的。还有一些指标的关联,无法用函数公式描述,它们之间的相关性用统计学指标来衡量,比如皮尔逊系数。Goldeneye的指标关联依据,目前还没有自动分析,暂时是人工根据经验设置的,只是视图让程序去完成追踪定位的过程,比如指标M1出现异常报警后能够触发相关指标RMG1/RMG2/RMG3的检测(因为这些指标可能平时不需要7*24小时监控报警,仅在需要的时候check),以此类推逐级检测定位。
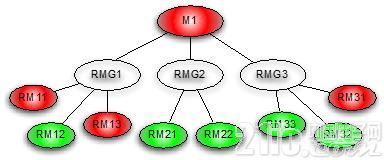
图8 关联指标
这些方式或许大家平时也尝试着去做过一些程序化的处理,我个人认为关联指标的方式,基础在于构建指标体系,这个构建过程可以是人工经验和程序统计分析的结合,指标体系至少能够描述指标的分类、数据出处、具体含义、影响相关指标的权重等等,有了这些基础才能应用统计学的分析方法完成。
四、难点
1、时间序列平稳化
平稳化的时间序列,对预测准确性有非常重要的意义,可是我们的业务监测时间序列恰好大多数都不是平稳化的,以5分钟的监测周期为力,除了大盘及核心监测序列,其他的时间序列都是在一定范围内正常波动但总体趋势却是稳定的。我们目前采用的方法是:
(1)滑动平均,比如波动锯齿明显,容易造成误报干扰的化,则加大监控监测周期,将5分钟提高到30分钟,相当于拟合6个时间窗口的数据来平滑时间序列。
(2)持续报警判断,如果觉得30分钟发现问题会比较晚,可以按5分钟检测,锯齿波动容易发生报警,但可以连续3次报警再发通知,这样就避免了锯齿波动的误报。
(3)对于需要均值漂移来检测细微波动的情况,24小时的时间序列本身有流量高峰和低谷,这种情况一般采用差分法做平滑处理,使用几阶差分自己掌握。Goldeneye没有直接使用差分法,因为我们已经预测了基准值,所以我们使用实际监测值与基准值的gap序列作为变点监测的输入样本。
2、埋点代价
业务监控的监测数据来源主要是日志、业务系统模块吐出到中间件、采集接口被push,从系统各模块吐出数据到中间件似乎比直接写入磁盘的IO开销小很多,不过对于请求压力比较大的系统,开旁路写出数据即使是内存级也是有一定开销的。
解决这个问题的办法是数据采样,对于在时间上分布均匀的监测数据,直接按百分比采样。
3、数据标准化
虽然数据接入是分层开放的,但是我们还是制定了标准的数据格式,比如时间序列数据存储schema,可扩展的日志消息proto格式,在这些结构化数据的定义中,可以区分出业务线、产品、流量类型、机房、版本等一些标准的监控维度信息,这样做的目的是以后可以将这些监测数据和故障定位的指标相关性分析衔接起来。
但是,这些标准化的推进需要很多参与者的认可和支持,甚至需要他们在系统架构上的重构,看似是比较困难的。
目前可以想到的办法,就是在旁路吐出监测数据时,以标准化的消息格式封装,然后保证在Goldeneye的存储层有标准的schema和接口访问。
五、今后的优化方向
时间序列预测模型,目前的模型只考虑了日期、节假日/周末、时间段的因素,没有年同比趋势、大促活动影响、运营调整影响的因素,需要抽象出来。
指标相关性由统计分析程序来确定。






评论