Intel摩拳擦掌抢攻人工智能市场商机

Intel收购Nervana的目标在于取得其预计2017年问世的深度学习加速器晶片,如果该晶片的性能表现如预期,Intel的深度学习加速器硬体开发板可望…
本文引用地址:https://www.eepw.com.cn/article/201608/295488.htm处理器大厂英特尔(Intel)将于下周于美国旧金山举行的Intel Developer Forum (IDF)年度开发者论坛,进一步阐述该公司收购深度学习(deep learning)技术供应商Nervana Systems的意图──此举被视为Intel与深度学习人工智慧(AI)应用绘图处理器(GPU)竞争的重要策略。
Intel在高性能运算(high-performance computing,HPC)市场居主导地位,Nvidia则以其复杂GPU在深度学习领域有大幅进展;而Nervana Systems的GPU则是以相容于Nvidia的Cuda软体与自家Neon云端服务在市场获得关注。
Intel收购Nervana的目标在于取得其预计2017年问世的深度学习加速器晶片,如果该晶片的性能表现如预期,Intel的深度学习加速器硬体开发板可望超越Nvidia的GPU开发板,同时收购自Nervana的Neon云端服务之性能表现也将超越Nvidia的Cuda软体。
“这并Intel给Nvidia的一记重击,”市场研究机构Moor Insights & Strategy的深度学习暨高性能运算资深分析师Karl Freund接受EE Times访问时表示:“但这是进军一个成长非常快速的市场之合理策略。”
Freund进一步解释:“GPU是训练深度学习神经网路的一个热门方法,Nvidia在该领域是领导厂商;Intel则有自己的多核心Xeon/ Xeon Phi处理器,以及收购自Altera的FPGA,却没有GPU。收购Nervana是以一个非复制通用GPU策略进军深度学习市场的方法,也就是透过提供为神经网路量身打造的特制处理器。”
Nervana运算速度号称可达每秒8 terabit的Engine晶片,是一款以矽中介层(silicon-interposer)为基础的多晶片模组,配备terabyte等级的3D记忆体,环绕着3D花托状架构(torus fabric)、采用低精度浮点运算单元(FPU)的连结神经元;因此Freund指出,该晶片与竞争通用GPU相较,能以更小的尺寸支援每秒更多次数的深度学习运算。
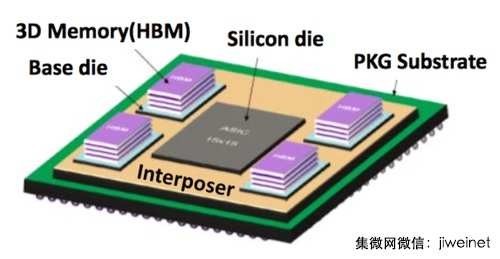
Nervana 的Engine晶片架构
Freund表示:“深度学习神经网路能摆脱通用GPU在理论上过度夸大的较低精度运算;虽然Nervana的晶片要到明年才问世、因此目前并没有公布任何性能量测基准资料,但为深度学习神经网路量身打造的特殊应用晶片,性能应该会超越在通用GPU的相同演算法。”
Intel声称,目前全世界有97%支援机器学习的伺服器都是采用Xeon/Xeon Phi晶片,但这些伺服器占据全球伺服器的比例不到10%;不过Intel也表示,机器学习是成长速度最快的AI应用,因此该公司准备好以Nervana的Engine晶片为基础的深度学习神经网路,找回因GPU竞争而流失的市占率。
针对Nervana的收购,Intel执行副总裁暨资料中心事业群总经理Diane Bryant在一篇部落格文章中表示:“人工智慧正在转变商业运作以及人们参与世界的模式,而它的子集──深度学习,是扩展AI领域的关键方法。”
据了解,Intel将把Nervana的演算法纳入Math Kernel Library,以与其产业标准架构整合;此外收购Nervana将让Intel取得Neon云端服务,因此为旗下的云端服务增加支援Nvidia深度学习技术的产品。
Freund表示,Nvidia若要维持竞争力,可能也需要以低精度特制深度学习处理器来回应Intel+Nervana。目前Nervana的团队有48位工程师与管理阶层,将归入Bryant负责的Intel资料中心事业群(Data Center Group)。










评论