采用TI多标准基站SoC实现性能、效率与差异化的全面提升

接收加速器协处理器 (RAC) RAC 能为多达 256 个 WCDMA 用户执行上行链路码片率解扩运算。其包含基于矢量的高灵活性可配置关联引擎,能够支持大量的同步关联。
RAC 支持下列模式的运算:
FD:用于生成原始符号的径解扩
FT:用于执行 EOL(过早、按时、延迟)测量的径跟踪
FPE:用于执行径干扰关联的径功耗估算
9
PM:在天线上执行脉冲响应曲线以进行径探测的路径监控器
PD:在签名上执行脉冲响应曲线以进行前导码检测
SPE:执行宽带媒体流功耗测算的媒体流功耗估算功能
下面是 RAC 支持的上行链路物理通道:
DPCCH:专用物理控制通道
DPDCH:专用物理数据通道
HS-DPCCH:高速专用物理控制通道
E-DPCCH:增强型专用物理控制通道
E-DPDCH:增强型专用物理数据通道
PRACH:物理随机访问通道
Turbo 解码器 3 (TCP3d)
Turbo 解码器 3 协处理器 (TCP3d) 是前代 Turbo 解码器 2 的改进版本。TCP3d 可支持 WCDMA、TD-SCDMA、LTE 和 WiMAX,是一种在上行链路处理中对 Turbo 代码进行解码的可配置外设。TCP3d 的输入是系统位和校验位的软决策,而输出既可为软决策,也可为硬决策。为了最大限度地减少与使用该协处理器相关的开销,TCP3d 可生成 Turbo 交错表,并能在除执行解码之外还支持基于代码模块的 CRC 计算。其结果是 TCP3d 的开销比 TCP2 低 7 倍。TCP3d 在 TCI6616 上的吞吐量在 6 次迭代后为 389Mbps。
Turbo 编码器 (TCP3e)
Turbo 编码器协处理器3 (TCP3e) 是用于 Turbo 代码编码的协处理器,可支持 WCDMA、TD-SCDMA、LTE 和 WiMAX。输入 TCP3e 的是信息位,输出的则是编码后的系统位和校验位。它支持基于代码模块的 CRC、turbo 编码和 turbo 交错表生成,最大吞吐能力为 643Mbps。
快速傅立叶转换协处理器 (FFTC)
快速傅立叶转换协处理器 (FFTC) 可实施用于 LTE 和 WiMAX 的 FFT/iFFT 和 DFT/iDFT。多内核导航器 (Multicore Navigator) 使数据能够直接在协处理器端进行输入和输出路由,并传输到 I/O。此外,其还能执行周期性的前缀移除和插入以及频率转换,从而进一步降低 DSP 上的处理负载。FFTC 的吞吐能力为每秒 12.72 亿个副载波。
10
图 4 - TCI6616 方框图
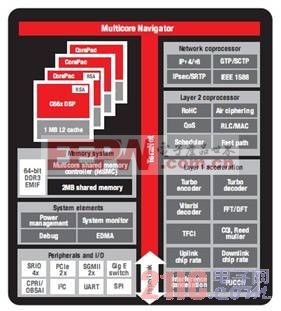
全面集成 —— TCI6616
图 4 显示了 TCI6616 的方框图。
TCI6616 具有创新型 KeyStone 架构、增强型 C66x 内核并新增了 LTE 和 WCDMA 协处理器,能够为无线基站应用实现较其他 SoC 高 5 倍的性能提升。
TCI6618 AccelerationPacs
TCI6618 为 TCI6616 增添了加速特性,可将 LTE 性能翻番。由于 TCI6618 能够与 TCI6616 实现引脚兼容,因而 OEM 厂商可通过选择系统适用的器件轻松灵活地进行平台优化。
由于 LTE 系统能够处理比 3G 系统高得多的数据速率,因而加速测重于对比特率的处理。
比特率协处理器
比特率协处理器 (BCP) 是一种多标准的协处理器,其能够大幅减轻 DSP 的所有比特率处理任务,从而使信号链的位处理部分无需占用任何 DSP 周期。它能够显著简化了软件设计,并能实现极低的系统时延。BCP 可执行以下功能:
调制/解调
交错/解交错
速率匹配/解速率匹配
11
• 加扰/解扰
• LTE 的 PUCCH 解码
• Turbo 和卷积编码
• CRC 连接和校验
BCP 不仅能够针对 MIMO 均衡实现 turbo 干扰消除,而且还实现了高性能PUCCH format 2 解码。当 LTE 达到最大下行链路 2.2 Gbps 的吞吐量、上行链路 1.1 Gbps 的吞吐量时,BCP 可减轻大约 15 GHz 的DSP MIPS。对于 WCDMA 而言,最大下行链路吞吐量可达 800 Mbps,最大上行链路吞吐量达 400 Mbps。
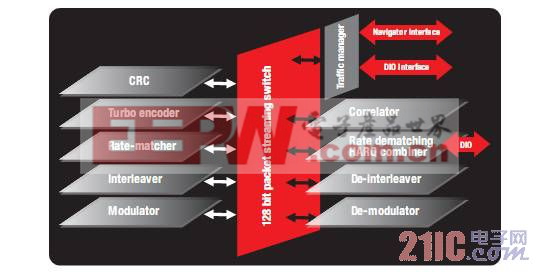
图 5 - BCP 体系架构
在 BCP 内部,数据可通过一个内部交换结构从一个子模块流入另一个子模块。分组 DMA 流量管理器可通过 128 位的 BCP 导航器或直接 I/O 接口将流量从 BCP 进行输入与输出路由。BCP 以分组为单位进行数据处理,并能同时处理不同的标准。当将任务请求发送至 BCP 时,该任务首先被置入 BCP 导航器队列中。BCP 调度程序依据任务优先级选择需要处理的任务。接着,由子模块处理该任务。最后,可将 BCP 结果写入缓冲器,并将描述符置入完整的队列上有待进一步处理。因为极少需要软件的介入,因此对 DSP 的周期需求显著减少,同时 LTE 处理时延也会大幅降低。
我们在此将介绍另一种可简化 DSP 处理需求的方法,通过诸如连续或并行干扰消除(SIC 或 PIC)等高级接收机技术来提升接收机的 MIMO 性能。这些算法需要功能强大的比特率协处理器才能高效地实现。解码算法的迭代特征要求对数据进行多次解码、处理、重新编码和解码,这对一般普通的系统而言可谓巨大的计算负担,但对于 TCI6618 却能轻松处理。
采用 TI 多标准基站 SoC 实现性能、效率与差异化的全面提升 2011 年 2 月
12
Turbo PIC/SIC 的性能改进意义重大。例如,在 2x2 MIMO 方案中,一个调制为 QPSK 的典型的城域信道中,turbo PIC/SIC 能产生超过 3 dB 的信噪比 (SNR) 性能增益,从而与一般的接收机方法相比可提升高达 40% 的频谱利用率。这不仅对运营商的意义重大,同时也是 TCI6618 与其他产品的重要差别点。
图 6 显示了 Turbo 干扰消除的数据流。BCP 和 FFTC 可从反馈路径分担绝大多数的 Turbo 均衡周期。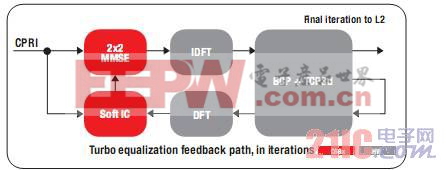
图 6 - Turbo 干扰消除数据流
控制信道解码器
作为 LTE 物理上行链路控制信道,PUCCH 可承载上行链路的控制信息,例如调度请求、确认、重传请求、信道状态信息以及信道质量指示 (CQI) 等信息。信道信息解码会消耗很大的处理资源。(见图 3)
PUCCH CQI 通过 Reed Muller (20, A) 模块代码进行编码。各种不同类型的算法均可对此信息进行解码。一种非常实用的基于 MRC 的算法可在软件内实施,但其性能不高。BCP 针对 PUCCH format 2、2a、2b 实现了高级的联合信道均衡和解码算法。这与其他更为基础性的算法相比,可实现更高的性能。图 7 显示了分别采用 TCI6488 和 TCI6618 的实施周期比较。在该例中,我们对带 5 个资源模块的系统进行了仿真,每个系统均有 12 个 UE,并且使用 Reed Muller (20, 13) 进行编码。在具备双天线的情况下,对于从 DSP 内核上的软件到硬件加速器的传输处理中,BCP 承担了 98% 的总 PUCCH format 2 处理量。
与典型算法相比,使用联合检测算法能将信噪比 (SNR) 性能提高 1 到 3 分贝。这种增强的性能不仅将显著改进链路预算,而且还能减少 UE 的干扰,并提高下行频谱利用率,从而提高整个 LTE 系统的性能,以为移动用户带来更精彩的体验。
全面集成 —— TCI6618
除了 BCP 协处理器无与伦比的性能外,TCI6618 还添加了额外的 FFTC 和TCP3d 协处理器,能够实现 SoC 功能的完美平衡。因此,在 6 个迭代中,FFTC 的总吞吐量为 1,908 Mbps,TCP3d 的总吞吐量则为 582 Mbps。与 TCI6616 相比,TCI6618 凭借均衡 CPU 内核和协处理器 将 LTE 的能力提升了 2 倍以上。TCI6618 通过 2x2 MIMO 天线配置且利用高级接收机算法,可以支持两个 20MHz 的 LTE区,下行吞吐量总计可达 300Mbps,而上行吞吐量总计则可达 150Mbps。










评论