基于DSP的高分辨SAR多普勒调频率的估算

2 DSP编程实现
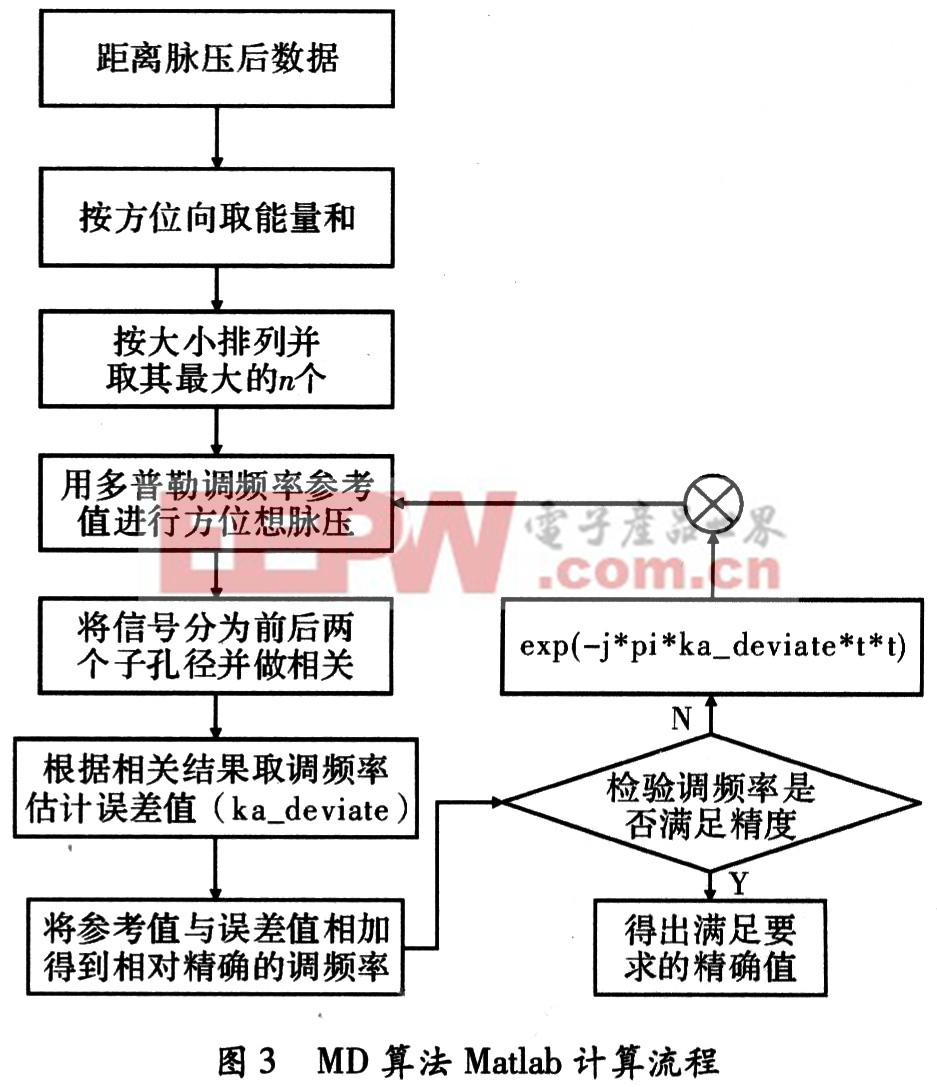
在实测数据的Matlab处理中,MD算法流程实现如图3所示。为了使多普勒调频率估计精度满足实际的需要,通常需要用估计出的多普勒调频率作为调频率参考值从对距离脉压数据做方位脉压,然后重复子孔径相关等后面的步骤,得出更精确的调频率值。一般重复3次即可,次数越多越精确,但是考虑的成像效果以及实时性的要求,3次重复就可以得出满意的结果。这里n为所选取的最大的能量和数量,这里选64即可以满足要求。
文中选用ADI公司的TSs-20lS高性能数字信号处理器在运算能力、与外部通信能力及在大内存设计等方面都优于其它类型的处理芯片。其主要特点有:(1)内部时钟频率最高为600 MHz,指令周期1.67 ns(在此系统中内部核时钟采用500 MHz,指令周期为2 ns),24 MB的片内DRAM存储器,分为6个4 MB的存储器块,每个块包含128 000个32位字,每个块内存连接着交叉线通过它自身的缓冲和一个128 000 kB的4-Way缓冲器;(2)芯片内包含两个运算模块(X-ComputeBlocks,Y-Compute Blocks),每个模块包括一个整数ALU、一个乘法器、一个移位器和一个寄存器组(32-word)和一个通信逻辑单元。其中,ALU用于寻址和指针操作;(3)4条128 bit的总线提供高的带宽连接内部存储块。扩展端口包含主机端口、SDRAM控制器、静态管线接口、4个DMA通道。4个LVDS连接端口(每一个都连接2个DMA通道),支持8片DSP共享总线的片上仲裁,无需其它逻辑。IEEE 1149.1兼容的JTAG测试端口用于片上仿真。外部端口的DMA传输速率可达1 GB/s,每个链路口的DMA传输速率可达1 GB/s,共计5 GB/s的外部I/O能力。而且,ADSP-TFS201S的静态超标量结构使其每周期能够执行多达4条指令、24个16位定点运算和6个浮点运算;4条相互独立的内部数据总线(128位),每条连接到6个4 MB的内部存储器块。提供了4 bit的数据、指令I/O访问和33.6 GB/s的内部存储器带宽。因此运行在500 MHz时,ADSP-TS201S的可以提供48亿次40位的MAC运算或者12亿次的80位MAC运算。雷达成像中用到了大量的FFT运算,TS201在计算。FFT时速度很快。例如,运行在500 MHz时,做1 024点的FFT只需18.8μs。ADSP-TS201S有丰富的内部存储资源,而且也特别适合于并行计算,组成高速并行处理器。这对于高分辨SAR实时成像系统而言非常有利。
在此实时成像中的多普勒调频率估计中,数据块为512×4 096(方位向和距离向)个复数。分别按照并且需要计算16个调频率值,即按距离单元分为16个子数据块,每个块为512×256个复数。为保证计算精度,一个复数占2×32 bit的存储单元,即实部虚部各占一个4 bit单元。
由于数据从SDRAM读到内部存储器中需要很多机器周期,在此时计算块就会处于空闲状态,不利于提高运行速度和执行效率,所以在实际计算时,采用如图4所示的流程来提高效率。图4中,相同的箭头表示同时交换数据。当计算块在计算内部存储区1的数据时,内部存储区2通过TS-201S的DMA模块直接和SDRAM交换数据。当计算完内部存储区1的数据时,计算块就直接计算内部存储区2的数据,同时内部存储区1通过 TS-201S的DMA模块直接和SDRAM交换数据,此时计算块一直处于满负荷状态,不用为等待数据而变得空闲,这种运算方式即所谓的“乒乓”方式。在使用DSP实现算法流程时,按方位向求能量和、方位脉压及子孔径相关的运算量最大,重点在这几方面进行优化。
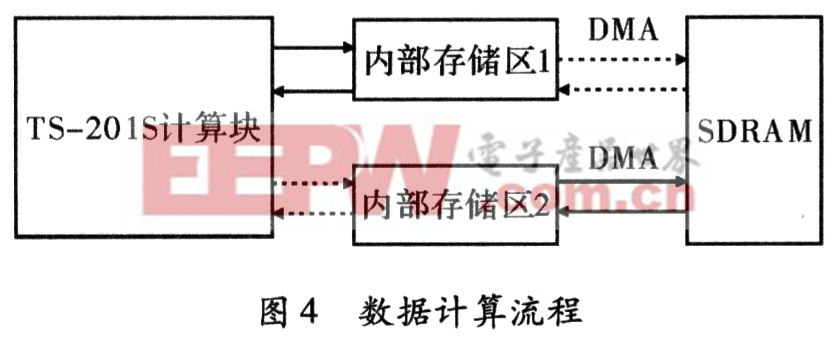
在按方位向取能量和的计算中,512个复数先取模再平方再求和,大概需要2 500多个机器周期,而从SDRAM中读取这512个数据需要1 200多个周期,因为512个复数相当于1 024个实数,并且DMA大约为一个周期传送一个数据。按照“乒乓”方式计算,相当于没有读取数据的时间,所以速度的提升是十分明显的。为了能够更加充分的利用计算块,在计算块和内部存储区之间也采用了类似的“乒乓”方式。在运算量极大的按方位向求能量和中,一个计算数据块512×2中有512个复数。其中,一个复数的模的平方需要计算两次乘法(每次乘法需要两个机器周期)和一次加法(一个机器周期),总和还需要512次加法,所以总共要计算大约3 500多个机器周期。所有的16个多普勒调频率估计,仅在计算能量和就需要约3 500×4 096多个机器周期,所以用尽可能少的机器周期来完成这个计算显得尤为重要。充分利用TS-201S处理器中计算块内部有两个并行的独立计算模块X-Compute Blocks和Y-Compute Blocks,而且每个计算模块都有一个乘法器和加法器,则同时读取两个复数分别到两个计算模块中,然后在寄存器中选一个作为和的存放地,初始为0,以及两个作为平方后的存放寄存器。先计算实部的平方(2个周期),再做虚部的平方以及将实部的平方与和寄存器相加存到和寄存器中(2个周期),读取下两个复数(1个周期),实部平方的计算及上一组数据的虚部平方与和寄存器相加并存放(2个周期),在做虚部平方及实部平方与和寄存器相加并存放(2个周期),依此类推,直到所有的复数计算完毕。从中可以看出,大约需要5个周期就可以计算两个复数,全部计算完成大概需要2 500多个周期,与3 500多个周期相比还是节省了很多。








评论