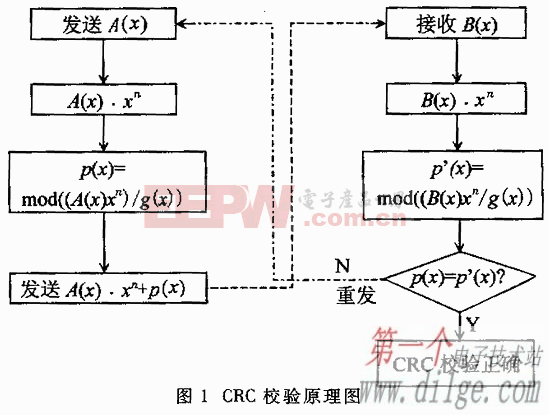
CRC校验源码学习

0xa7db, 0xb7fa, 0x8799, 0x97b8, 0xe75f, 0xf77e, 0xc71d, 0xd73c,
0x26d3, 0x36f2, 0x0691, 0x16b0, 0x6657, 0x7676, 0x4615, 0x5634,
0xd94c, 0xc96d, 0xf90e, 0xe92f, 0x99c8, 0x89e9, 0xb98a, 0xa9ab,
0x5844, 0x4865, 0x7806, 0x6827, 0x18c0, 0x08e1, 0x3882, 0x28a3,
0xcb7d, 0xdb5c, 0xeb3f, 0xfb1e, 0x8bf9, 0x9bd8, 0xabbb, 0xbb9a,
0x4a75, 0x5a54, 0x6a37, 0x7a16, 0x0af1, 0x1ad0, 0x2ab3, 0x3a92,
0xfd2e, 0xed0f, 0xdd6c, 0xcd4d, 0xbdaa, 0xad8b, 0x9de8, 0x8dc9,
0x7c26, 0x6c07, 0x5c64, 0x4c45, 0x3ca2, 0x2c83, 0x1ce0, 0x0cc1,
0xef1f, 0xff3e, 0xcf5d, 0xdf7c, 0xaf9b, 0xbfba, 0x8fd9, 0x9ff8,
0x6e17, 0x7e36, 0x4e55, 0x5e74, 0x2e93, 0x3eb2, 0x0ed1, 0x1ef0
};
根据这个思路,可以写出以下程序:
uint table_crc(uchar *ptr,uchar len) // 字节查表法求 CRC
{
uchar da;
while(len--!=0)
{
da=(uchar) (crc/256); // 以 8 位二进制数暂存 CRC 的高 8 位
crc=8; // 左移 8 位
crc^=crc_ta[da^*ptr]; // 高字节和当前数据 XOR 再查表
ptr++;
}
return(crc);
}
本质上 CRC 计算的就是移位和异或。所以一次处理移动几位都没有关系,只要做相应的处理就好了。
下面给出半字节查表的处理程序。其实和全字节是一回事。
code uint crc_ba[16]={
0x0000, 0x1021, 0x2042, 0x3063, 0x4084, 0x50a5, 0x60c6, 0x70e7,
0x8108, 0x9129, 0xa14a, 0xb16b, 0xc18c, 0xd1ad, 0xe1ce, 0xf1ef,
};
uint ban_crc(uchar *ptr,uchar len)
{
uchar da;
while(len--!=0)
{
da = ((uchar)(crc/256))/16;
crc = 4;
crc ^=crc_ba[da^(*ptr/16)];
da = ((uchar)(crc/256)/16);
crc = 4;
crc ^=crc_ba[da^(*ptr0x0f)];
ptr++;
}
return(crc);
}
crc_ba[16]和crc_ta[256]的前 16 个余式是一样的。
其实讲到这里,就已经差不多了。反正当时我以为自己是懂了。结果去看别人的源代码的时候,也是说采用 CCITT,但是是反相的。如图 3

反过来,一切都那么陌生,faint.吐血,吐血。
仔细分析一下,也可以很容易写出按位异或的程序。只不过由左移变成右移。
uint crc16r(unsigned char *ptr, unsigned char len)
{
unsigned char i;
while(len--!=0)
{
for(i=0x01;i!=0;i = 1)
{
if((crc0x0001)!=0) {crc >>= 1; crc ^= 0x8408;}
else crc >>= 1;
if((*ptri)!=0) crc ^= 0x8408;




评论