基于嵌入式系统的语音口令识别系统的实现

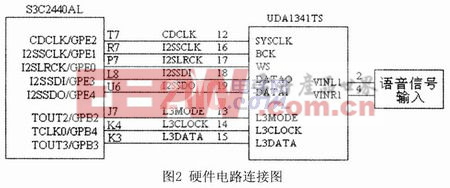
通过上述IIS总线能够得到输入的音频数据信号,而其它的信号如自动增益控制、输入数据格式的选择和输入增益的控制等控制信号通过称为“L3”形式的接口总线传输。为了减少引脚数和保持连线简单,该接口总线采用串行数据传输方式,接口总线由3条信号线组成:时分复用的数据通道线L3DATA、模式控制线L3MODE和时钟信号线L3CLOCK。模式控制线L3MODE为低电平时的传输模式为地址传输模式;为高电平时的传输模式为数据传输模式。
语音口令识别系统的硬件电路的核心芯片是嵌入式微处理器Samsung S3C2440 AL,主频为400MHz。三星公司推出的RISC微处理器S3C2440 AL具有低功耗、高性能等特点,可以广泛应用于便携式设备中。S3C2440AL具有一个IIS总线音频编码/解码接口,语音口令识别系统的硬件电路如图2所示。其IIS总线控制器通过5根信号线与UDAl34lTS编解码芯片相连。这些5根信号线分别是:系统时钟信号CDCLK:位时钟信号I2-SSCLK;字选择控制信号I2SLRCK;串行数据输入信号I2SSDI;串行数据输出信号I2SDO。S3C2440 AL使用L3接口传输其他(如自动增益控制、输入数据格式的选择和输入增益的控制等)控制信号。为了使系统间能够更好地同步,S3C2440AL需要向芯片UDAl341TS提供CDCLK,该时钟信号的频率可以选择采样频率的256倍、384倍或512倍。本文引用地址:https://www.eepw.com.cn/article/151538.htm
2 基于CDHMM的口令识别的软件设计
2.1 口令识别的软件系统框图
语音口令识别的软件系统分别由特征参数提取、语音模型库和概率输出评分三大模块组成,如图3所示:1)语音口令特征参数的提取,输入不同的语音口令,首先要进行特征参数提取,采用Mel频率参数作为CDHMM的建模参数,Mel频率参数是根据人耳的听觉特性将语音信号的频谱转化为基于Mel频率的非线性频谱,然后转换到倒谱域上。2)在训练阶段,对不同的语音口令建立CDHMM模型。3)在口令识别阶段,通过概率输出评分对待测语音口令做出识别。
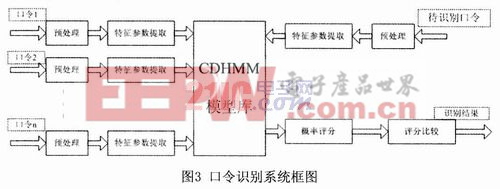
语音口令首先经过预处理,提取MFCC特征参数,然后建立此口令的CDHMM模型,把所有语音口令的模型放在模型库中,在识别阶段,通过概率输出评分,取评分最大的一个作为识别出的口令。

评论