基于DSP的宽带雷达多片流水分段脉压处理平台设计
1 引 言
本文引用地址:http://www.eepw.com.cn/article/87582.htm作为一种探测目标信息的工具,雷达在现代战争中发挥着举足轻重的作用。在雷达回波信号处理中,通常利用线性调频信号脉冲压缩技术来获得高的距离分辨率。他有效地解决了雷达作用距离与距离分辨率之间的矛盾,可以在保证雷达作用距离的情况下提高雷达的距离分辨力。数字脉冲压缩就是利用数字信号处理的方法来实现雷达信号的脉冲压缩,分为时域和频域两种实现方式。时域脉压常用数字滤波器实现,而频域脉压常用专用的FFT芯片或DSP完成。一般而言,对于小时宽带宽积信号,用时域脉压较好;但对于大时宽带宽积信号,用频域脉压较好。随着通用DSP芯片本身处理能力的不断提高,基于并行DSP芯片的雷达信号处理系统基本能够满足雷达脉冲压缩信号处理实时性的需求。
本文针对雷达回波的实时脉冲压缩处理,首先分析了频域脉压处理方法,介绍了分段脉压原理。然后研究了基于DSP的多片流水分段脉压设计,以某宽带雷达回波为例,提出了基于4片ADSP-TS101芯片的高性能并行DSP硬件处理平台设计。最后给出了硬件实现和实验结果。
2 频域脉压实现分析
对接收到的信号作数字脉压,等同于信号通过一个加权的匹配滤波器。从时域来说,输出为信号与加权的匹配滤波器的线性卷积,等价于二者在频域的乘积。需要注意的是两离散信号频率域相乘相当他们在时域作圆卷积,为使圆卷积与线性卷积等价,待处理的信号须加零延伸,避免圆卷积时发生混叠。
设输入序列x(n)长度为L,系统冲击响应h(n)长度为M(M<L),输出y(n)。对于频域处理,其运算为:
![]()
式(1)实际上是圆卷积运算,在运算时,x(n)和h(n)必须至少补零到L+M-1点,等到x(n)完全读入后,开始脉压运算,得到的y(n)有效输出长度为L点。因此频域脉压处理时间大致分为数据块读入读出时间和脉压运算时间。总运算量包括L点x(n)数据输入、L+M-1点复FFT,L+M-1点复点乘、L+M-1点复IFFT以及L点y(n)数据输出。
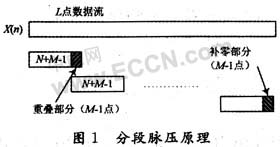
当输入序列x(n)的长度L》M,直接做L+M-1点的脉压不仅运算量大、存储单元多,而且有很大的数据读入读出延迟。可以采用重叠保留法进行分段脉压处理。设x(n)均匀分段,每段长度为N(满足N≥M,N+M-1接近2的整数次幂),在每段后面再补上后一段的前M-1个输入序列值,组成N+M-1点序列,若为最后一段,则补M-1个零。每个N+M-1点序列与h(n)脉压后,输出的结果取前N点为每段的有效输出。这样按顺序拼接在一起即可得到输入序列x(n)的脉压输出。其原理如图1所示。
3 基于DSP的多片流水分段脉压设计
当分段脉压处理时,可以采用多个分段同时脉压的并行处理技术来减少整个脉压过程的处理时间。流水线技术(Pipeline)为并行处理系统设计中实现时间并行性提供了一种有效方法,他将输入流水线的任务分为一串子任务,相继的任务不断流人流水线,利用子任务在执行时间上的重叠(Time Interleaving),使得每个子任务都处在整个操作流程不同的处理段中,且保持在不同的完成阶段来达到操作级并行。
在忽略数据内部交换以及脉压前的数据浮点化等运算时间的前提下,可以将每段脉压任务大致分为数据输入、数据脉压和脉压结果输出三个子任务。若各段分段脉压过程均采用流水线技术操作,相邻两段脉压任务分别由不同的DSP完成。那么相邻两段脉压过程进入流水的时间仅相差数据输入的操作时间,流水操作如图2所示。
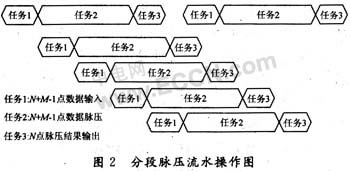
设输入序列x(n)长度为L点,分段重叠点数为M-1,分段脉压点数为d(为2的整数次幂)点,定义x(n)的分段总数为p,则p=[L/(d-(M-1))],[]表示不小于此值的最小正整数(下同)。定义每段的分段长度为N,则N=[L/p]。

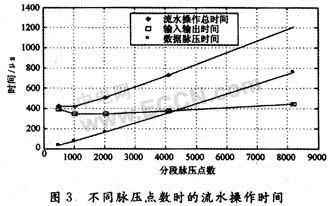
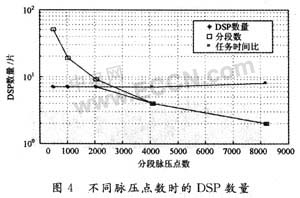
下面以某宽带雷达为例,在输入序列点数和分段重叠点数确定的情况下,采用AD公司的高性能定/浮点ADSP-TS101芯片,分析各流水任务时间、流水操作时总的脉压时间、分段数、任务时间比以及参与多片流水的DSP数量等与分段脉压点数之间的关系。设雷达脉冲宽度为1 μs,脉冲重复周期(PRT)为1 ms,带宽为200 MHz,脉压距离范围为10 km,采样率为220 MHz,I,Q两路合并输出为16 b。相邻两分段的重叠数据在ADSP-TS101之间采用Link口传输。随分段脉压点数d的变化规律见图3和图4。
由图3可以看出,流水操作时,随分段脉压点数d的增加,数据脉压时间是快速增加的,数据输入输出时间是先递减后缓慢增加的。总的脉压时间Tpip是先递减后快速增加的,这是因为,在d相对较小时,数据输入输出时间的减少量大于数据脉压时间的增加量,总的脉压时间Tpip的变化表现为减少;而随着d的增加,数据脉压时间的增加量明显大于数据输入输出时间的增加量,总的脉压时间Tpip的变化表现为快速增加,特别当d大于4 096点之后,数据脉压时间更成为总的脉压时间Tpip的主要部分。可以得出,分段脉压点数d的递减不一定总会带来总的脉压时间的减少,特别当d相对较小时,数据输入输出时间更成为制约总的脉压时间Tpip的主要因素。
由图4可以看出,随分段脉压点数d的增加,分段数反比于d,是快速递减的。任务时间比是缓慢变化的,维持在7~8的水平,这是由ADSP-TS101本身的处理速度的决定的。在对应的分段脉压点上,选择分段数与任务时间比中相对较小的值,得到参与多片流水的DSP数量NDSP,其变化趋势是递减的。可以这样理解,在d相对较小时,分段数较多,每个DSP可以完成多次分段脉压任务,DSP的数量主要由任务时间比决定;而随着d的增加,分段数快速递减,直接减少了对DSP数量的需求。
为了评价基于DSP的多片流水分段脉压设计的并行程度,在这里引用加速比(Accelerate Ratio)和并行效率的概念。可以定义NDSP个DSP处理器的加速比为:

可以看出,并行效率与加速比是密切相关的,Sp越接近于NDSP,Ep越接近于1。实际上,影响多片流水分段脉压设计并行效率的因素是多方面的,我们应该综合考虑流水操作时总的脉压时间、参与多片流水的DSP数量、加速比以及并行效率等各项指标,以尽可能达到多片流水分段脉压的最优设计。
根据式(2)~式(5),结合某宽带雷达参数,给出不同分段脉压点数d时的流水操作时总的脉压时间Tpip、参与多片流水的ADSP-TS101数量NDSP,加速比Sp以及并行效率Ep等指标,详见表1。
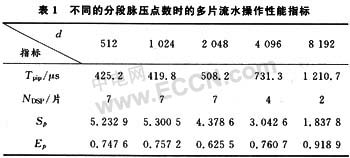
以上分析还没有考虑单片ADSP-TS101的数据内部存取以及脉压前的数据浮点化等运算时间。综合各方面因素考虑,要在1 ms内完成该宽带雷达回波的实时脉冲压缩处理,我们选择的分段脉压点数为4 096点,据此设计了基于4片ADSP-TS101芯片的多片流水分段脉压并行DSP硬件平台,该平台采用了共享总线并行结构和分布式并行结构相结合的方式,充分利用了并行总线的带宽,以及Link口的灵活、方便及快速的特点。
4 硬件平台设计实现
本文设计的实时脉压处理硬件平台是一块由4片ADSP-Ts101构成的6U CPCI前面板,结构如图5所示。DSP1,DSP2,DSP3,DSP4采用共享总线结构和MeshSP结构相结合的方式,构成板上的多片流水分段脉压并行运算模块。4片DSP在通过集成于芯片内部的发布式总线仲裁逻辑共享总线的同时,还通过Link口构成了两两互连的网格结构,这样充分发挥ADSP-TS101芯片的并行处理能力的优势。两种并行计算结构的结合,既减少了处理器对总线的竞争,又大大增强了处理器问的数据交换能力。数据总线和地址总线上连接存放程序代码的FLASH芯片和作为外部存储的SDRAM芯片,能够满足系统对大批量数据的处理需求。
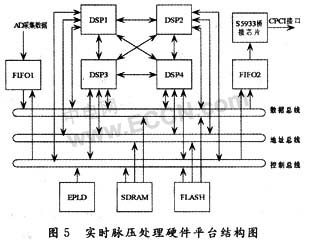
FIFO1和FIFO2作为数据的输入输出缓存,宽带雷达的视频回波数据首先在FIFO1中缓存。当FIFO1中写入14 667点完整的目标回波数据后,由EPLD向DSP发出数据有效标志。当DSP检测到数据有效标志后,将FIFO1中数据写到DSP缓冲区。数据在DSP之间的传输主要通过Link口实现,当DSP将脉压结果写入FIFO2后,EPLD向CPCI接口芯片S5933发送数据有效标志。当S5933检测数据有效标志后将FIFO2中数据写到主机。实物图如图6所示。

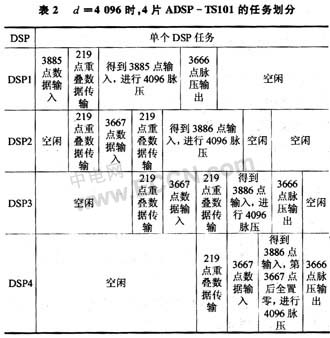
下面给出4片DSP的任务划分,见表2,当d=4 096时,p=4,N=14 667/4,我们取各分段长度分别为3 666,3 667,3 667,3 667。
5 实验结果及结论
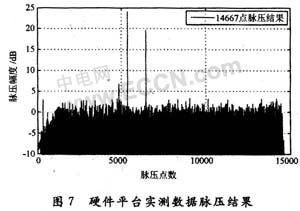
雷达回波数据经过脉压处理之后,由CPCI总线接口传输给计算机,通过Matlab软件将脉压结果显示如图7所示。经过实测,整个脉压处理过程从数据输入到脉压结果输出共耗时约780μs。完全满足脉冲重复周期(PRT)1 ms的要求。
在雷达回波的实时处理过程中,脉冲压缩处理占有举足轻重的地位。本文在进行基于DSP的多片流水分段脉压设计时,做了两个假设:第一个是将每段脉压任务分为数据输入、数据脉压和数据输出三个子任务,忽略其他的运算时间,进行流水设计,得出了总的脉压时间;第二个是假设相邻的子任务由不同的DSP完成,据此得出了参与多片流水的DSP数量。然后综合考虑了总的脉压时间、参与多片流水的DSP数量、加速比以及并行效率等因素,在输入序列点数和分段重叠点数确定的情况下,研究了分段脉压的分段长度设计,指导设计实现了基于4片ADSP-TS101芯片的高性能并行DSP硬件平台。最后通过实测数据验证了硬件平台的设计。












评论