基于DSP的电力线载波OFDM调制解调器

1 OFDM原理
2 电力线载波通信系统结构
Homeplug是工业界第一个电力线家庭网络标准.系统参考Homeplug采用的频谱范围4.5MHz~21MHz,并在Homeplug物理参数的基础上确定本系统参数为:
采样频率fs=1/T = 15MHz
数据符号时间Td = 256×T=17.07μs
循环前缀时间Tcp = 172×T=11.47μs
OFDM符号时间Ts = 428×T=28.5μs
数据子载波数为256
子载波间隔Δf=1/Td=0.05858MHz
总子载波占用带宽 N×Δf=15MHz
由于加入了11.47μs的循环前缀,系统可以消除11.47μs以内的回波干扰.但是同时也付出频带利用率仅0.59B/Hz和损失功率2.23dB的代价.考虑到电力线恶劣的通信环境,付出的代价是值得的.
电力线高速通信系统的系统结构如图1所示.输入数据在OFDM信号调制部分依次经过串/并变换、IFFT、加入循环前缀、并/串变换后,输出调制后的信号,其频带范围为0~15MHz、数据速率为8.97MB.经过调制的信号经过数/模变换和上变频后,通过系统耦合部分进入电力线. 电力线上的信号通过系统耦合部分,输出的信号通过下变频、模/数变换后输入给OFDM信号解调部分.在经过串/并变换、去除循环前缀、FFT、并/串变换后,输出串行数据流.
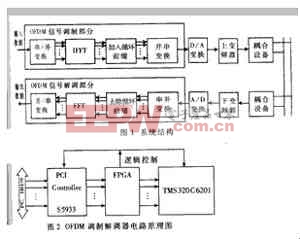
3 OFDM调制解调器的硬件实现
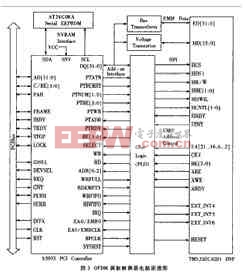
S5933是AMCC(Applied Micro Circuits Corporation)公司开发的32bit PCI控制器,具备强大、灵活的PCI接口功能,适用于高速数据传输场合.S5933芯片的特点是符合PCI2.1规范,支持PCI主、从两种工作方式,支持多种数据传输方式,适用于不同的数据传输场合,支持PCI全速传输,提供8/16/32bit的Add-On用户总线,有高低字节顺序调整功能,支持穿行和并行的BOOT/POST码功能,160脚PQFP封装.
DSP部分选用TI公司的TMS320C6201.TMS320C6201有32位的外部存储接口EMIF,为CPU访问外围设备提供了无缝接口.为了便于多信道数字信号处理,TMS320C6201配备了多信道带缓冲能力的串口McBSP.McBSP的功能非常强大,除具有一般DSP串口功能之外,还可以支持T1/E1、ST-BUS、IOM2、SPI、IIS等不同标准.TMS32C6201提供的16位主机接口(HPI)使得主机设备可以直接访问DSP的存储空间.通过内部或外部存储空间,主机可以与DSP交换信息,也可以利用HPI直接访问映射进存储空间的外围设备.TMS320C6201的DMA控制器有四个独立的可编程通道,可以同时进行四种不同的DMA操作.
4 OFDM在DSP上的软件实现
调制部分的子程序被系统调用前,发送的数据已装入数据存储器.子程序被调用时,数据区的首地址以及长度被作为入口参数传递给子程序.程序执行时首先进行一系列的配置工作,如配置DSP片内外设以及数模转换器的各种参数等.之后,串口中断产生,中断服务程序自动依次读取发送存储器中的内容,经串口输出给数模转换器.然后程序从数据存储区读取一帧数据,并行放入IFFT工作区的相应位置,随后进行IFFT以及加入循环前缀(即复制数据的后若干位插入到数据的前段).所得数据存入发送存储器以便中断服务程序将其输出.
5 FFT在TMS320C6201上的优化算法
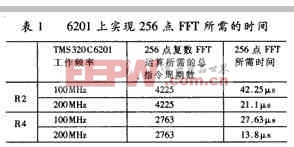
表1给出256点Radix2FFT和Radix4FFT在TMS320C6201上所需的指令周期,以及在不同的工作频率下完成FFT所需的时间. 由表1可以看出,在TMS320C6201上采用Raidx4算法比采用Radix2算法更加高效.并且,为了满足系统需求,即在17.07μs之内完成256个复数点的FFT运算,TMS320C6201必须采用200MHz的工作频率.
为使代码达到最大效率,程序将尽可能将指令安排为并行执行.为使指令并行操作,程序确定指令间的相关性,即一条指令必须发生在另一条指令之后.根据TMS320C6201的数据通路和流水线工作方式,在此给出一种高效实现16点Radix4FFT的方法.其基本思想是分解传统的FFT蝶型算法循环体,将其分别展开在A、B通路内计算两个FFT蝶型算法.每个蝶型算法分别只分配自己这一侧的寄存器组和功能单元.这样在循环体内两个蝶型算法是完全不相关的,能够并行执行.下面给出基于C.S.Burrus和T.W.Parks的Radix4FFT算法的优化算法的代码实现.
void radix4(int n,short x[], short w[])
{
int n1,n2,ie,wa1,wa2,wa3, wb1, wb2,wb3,ia0,ia1,ia2,ia3,ib0,ib1,ib2,ib3,j,k;
short ta,tb,ra1,ra2, rb1,rb2,sa1,sa2,sb1,sb2,coa1,coa2,coa3,cob1,cob2,cob3,sia1,sia2,
sia3,sib1,sib2,sib3;
n2=n;
ie=1;
for(k=n;k>1;k>>=2)
{ //number of stage
n1=n2;
n2>>=2; // distance between input datas
wa1=0;
for(j=0;jwb1=wa1+ie;
wa2=wa1+wa1;
wb2=wb1+wb1; //since heremost of the folow-ering two instructions are parallel
wa3=wa2+wa1;
wb3=wb2+wb1;
coa1=w[wa1*2+1];
cob1=w[wb1*2+1];
sia1=w[wa1*2];
sib1=w[wb1*2];
coa2=w[wa2*2+1];
cob2=w[wb2*2+1];
sia2=w[wa2*2];
sib2=w[wb2*2];
coa3=w[wa3*2+1];
cob3=w[wb3*2+1];
sia3=w[wa3*2];
sib3=w[wb3*2];
wa1=wb1+ie;
for(ia0=j,ib0=j+1;ia0{//loop of two butterflies caculation
ia1=ia0+n2;
ib1=ib0+n2;
ia2=ia1+n2;
ib2=ib1+n2;
ia3=ia2+n2;
ib3=ib2+n2;
ra1=x[2*ia0]+x[2*ia2];
rb1=x[2*ib0]+x[2*ib2];
ra1=x[2*ia0]-x[2*ia2];
rb1=x[2*ib0]-x[2*ib2];
ta=x[2*ia1]+x[2*ia3];
tb=x[2*ib1]+x[2*ib3];
x[2*ia0]=ra1+ta; // x[2*ia0]
x[2*ib0]=rb1+tb; // x[2*ia0]
ra1=ra1-ta;
rb1=rb1-tb;
sa1=x[2*ia0+1]+x[2*ia2+1];
sb1=x[2*ib0+1]+x[2*ib2+1];
sa2=x[2*ia0+1]-x[2*ia2+1];
sb2=x[2*ib0+1]-x[2*ib2+1];
ta=x[2*ia1+1]+x[2*ia3+1];
tb=x[2*ib1+1]+x[2*ib3+1];
x[2*ia0+1]=sa1+ta;
x[2*ib0+1]=sb1+tb;
sa1=sa1-ta;
sb1=sb1-tb;
x[2*ia2]=(ra1*coa2+sa1*sia2)>>15;
x[2*ib2]=(rb1*cob2+sb2*sib2)>>15;
x[2*ia2+1]=(sa1*coa2-ra1*sia2)>>15;
x[2*ib2+1]=(sb1*cob2-rb1*sib2)>>15;
ta=x[2*ia1+1]-x[2*ia3+1];
ra1=ra2+ta;
rb1=rb2+tb;
ra2=ra2-ta;
rb2=rb2-tb;
ta=x[2*ia1]-x[2*ia3];
tb=x[2*ib1]-x[2*ib3];
sa1=sa2-ta;
sb1=sb2-tb;
sa2=sa2+ta;
sb2=sb2+tb;
x[2*ia1]=(ra1*coa1+sa1*sia1) >>15;
x[2*ib1]=(rb1*cob1+sb1*sib1) >>15;
x[2*ia1+1]=(sa1*coa1-ra1*sia1)>>15;
x[2*ib1+1]=(sb1*cob1-rb1*sib1)>>15;
x[2*ia3]=(ra2*coa3+sa2*sia3) >>15;
x[2*ib3]=(rb2*cob3+sb2*sib3) >>15;
x[2*ia3+1]=(sa2*coa3-ra2*sia3)>>15;
x[2*ib3+1]=(sb2*cob3-rb2*sib3)>>15;
}
}
ie =2
}
}










评论