基于小波包变换和压缩感知的人脸识别算法

引言
本文引用地址:https://www.eepw.com.cn/article/235426.htm人脸识别是一个经典的模式识别问题。压缩感知理论的出现和发展,给人脸识别带来了新的启发,使得基于稀疏表示的人脸识别技术得到了广泛研究。传统的基于稀疏表示的人脸识别是利用压缩感知超完备库下的稀疏表示,将训练图片直接构造为冗余字典,再求解重构算法下的最优稀疏线性组合系数,然后根据这些系数来对人脸图像进行分类。
郑轶、蔡体健[1]针对人脸求解稀疏表示时正交匹配追踪算法运算度高,提出了一种改进的算法,加快了逆矩阵和大矩阵乘积的求解,但在构成训练字典时对光照[2]、表情[3]、姿态[4]等考虑较少。Allen Y. Yang[5]等针对压缩感知基于最小一范数求解最优稀疏表示时算法运算度高,提出了一种凸优化算法,取得了不错的识别率,但仍然是超完备库下的稀疏表示。平强、庄连生[6]等针对人脸识别姿态问题提出了基于仿射变换的人脸分块稀疏表示,提升了算法的识别性能,但仿射变换和分块稀疏表示都增加了运算复杂度。
本文针对上述字典构成问题,提出基于基函数字典下的稀疏表示,寻找一个正交基,使得信号表示的稀疏系数尽可能的少,小波基符合这一要求,同时小波包变换能提取人脸低频、高频四个频带的特征,包括人脸的整体特征和局部纹理特征,小波包多层变换后还可以2n的速度对人脸图像进行降维。本文在运用压缩感知时,只利用压缩感知对高维人脸图片进行降维,不进行重构算法寻求最优稀疏解,大大降低了算法的复杂度。实验结果表明本算法与相关算法比较识别率较高,运算时间基本无劣势,对训练样本的数目要求较低。
1 基本理论
1.1 小波变换的基本理论
小波变换是一种变换分析方法,它将原始图像与小波基函数进行内积运算,图像经小波分解后可得到一个近似分量和三个方向的细节分量,三个细节分量分别具有高度的局部相关性,而整体相关性能最大限度地消除。选择小波基时具体要考虑小波基的正交性,使得各子带间数据相关性最小;紧支性使应用精度较高,不需要人为截断数据;小波基的对称性也是十分重要的,因为可以构造紧支的正则小波基,从而具有线性相位[7]。
小波包变换区别于小波变换,它不仅对信号的低频分量进行连续分解,而且对高频分量也进行连续分解,不仅可得到许多分辨率较低的低频分量,而且也可得到许多分辨率较低的高频分量,如图1所示,这种变换称之为小波包变换 [8]。
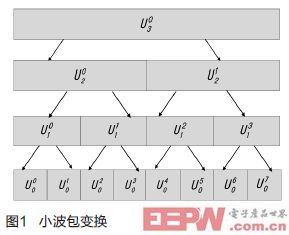
图1中,箭头向左表示当前层低通滤波变换,箭头向右表示当前层高通滤波变换。
1.2 压缩感知理论
压缩感知理论[9]指出,只要信号是可压缩的或在某个变换域是稀疏的,那么就可以用一个与变换基不相关的观测矩阵将变换所得高维信号投影到一个低维空间上。压缩感知信号稀疏表示主要有两个方向[10],一是基函数字典下的稀疏表示,二是超完备库下的稀疏表示。稀疏信号通过观测矩阵投影如公式(1)所示:
![]()
其中为观测矩阵,为稀疏信号,为信号经观测矩阵投影后所得列向量。
将压缩感知作为特征提取的方法,必须保证观测矩阵不会把两个不同的稀疏信号映射到同一个采样集合中,这就要求从观测矩阵中抽取的每M个列向量构成的矩阵是非奇异的,同时需要保证观测矩阵和稀疏基不相干。
2 本文稀疏表示的人脸识别算法
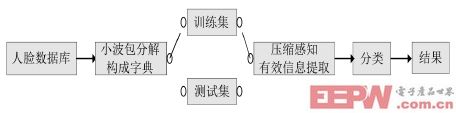
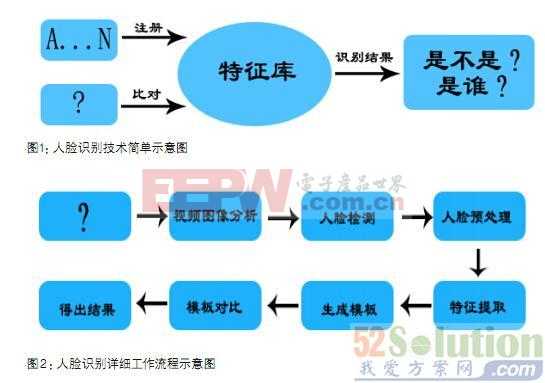
本文将小波包变换和压缩感知结合应用于人脸识别,具体识别过程如图2所示。
2.1 二层小波包分解构成基函数字典
根据前文描述小波包变换,2D-WPT 是一维离散小波变换的扩展,其实质是将二维信号在不同尺度上进行分解,得到原始信号的近似分量和细节分量。原始图像经过1层2D-DWT分解后图像被分成4个部分:近似部分,水平细节,垂直细节以及对角细节。
近似部分是对人脸的全局描述,主要受光照、姿态和位置影响,三个细节分量是对人脸的局部细节描述,主要受表情和遮挡饰物(如眼镜,胡须等)的影响[11]。每部分图像大小为原始图像的四分之一大小,对图像起到了降维的作用。

图3是对一幅大小为100×100的人脸图像进行小波变换的结果。
图3(a)为原始人脸图像,图(b)为对原始图像进行的一层小波分解,分别为原始图像的低频分量(左上)垂直高频分量(右上)、水平高频分量(左下)和对角高频分量(右下),图(c)为低频分量进行两层分解。上述小波变换选取的小波基为db1,考虑了小波基的紧支撑、高阶消失矩和对称性,db1是比较适合对人脸图像进行小波变换的小波基,大量实验也证明了db1在进行人脸重构时,平均重构误差是最小的,即db1更适合提取人脸特征,证明了分析的正确性。
本文进行了小波包的分解,既完成了基于基函数字典下的稀疏表示,也提取了人脸识别的整体信息和局部细节信息。在构成基函数字典时,需将低频、高频分量分别构成列向量,最后组成一个大的列向量,保留其中的结构信息。
小波包变换采用两层分解,取第二层分解结果作为特征,使得图像维数得到降低,进而也使得降维时压缩感知的运算量大大减少。如果小波包分解层数过多,会造成计算耗时,同时图像信息也会因为多次分解而部分丢失。
2.2 压缩感知降维
人脸图像经小波包变换构成基函数字典后,信息具有稀疏性,同时包含人脸表情、姿态等细节信息,从而用压缩感知进行进一步的有效信息的提取和降维,将基函数字典矩阵与观测矩阵运算后得到一个维数较低的向量,作为人脸的最终特征向量。最后本文用训练图像和测试图像特征向量之差二范数分类器进行分类,得到了良好的识别效果。
本文选用的观测矩阵为哈达玛矩阵,它是由+1和-1元素构成的正交方阵,它的任意两行(或两列)都是正交的,即保证了观测矩阵是非奇异的,符合压缩感知对观测矩阵的要求,同时哈达玛矩阵也便于硬件实现。
本文算法应用于人脸识别具体做法描述如下:
(1)输入c类N个训练样本,进行二层小波包分解将训练样本投映到小波域,进而构成基函数字典训练空间A;
(2)给定一个测试图像,用二层小波包分解将其投映到小波域空间,进而构成测试空间x;
(3)将训练样本的字典空间按结构排成列向量,运用压缩感知计算 (i=1,2…N)将Yi的每一列作为最终进行比较的特征向量;
(4)将测试图像小波域的测试空间按结构排成列向量,运用压缩感知计算:;
(5)在每个最终特征向量上用 (i=1,2…N)计算特征向量之差的二范数;
(6)若,则x与第i个训练样本为同一类。
3 实验结果
选用Yale人脸数据库和ORL人脸数据库[12]作为实验素材,其中Yale A人脸总数165,15类,大小为,影响识别因素为光照、表情、姿态、饰物。训练样本为每类4幅图片,测试图像为每类其他7幅人脸。ORL人脸总数为400,40类,大小为,影响识别的因素为姿态。训练样本为每类3幅图片,测试图片为每类其他7幅人脸。实验环境为Intel Core2 Duo CPU--E7500 2.93GHz,2.00GB RAM,matlab7.0(R2009a)。
为验证本文算法的识别率和运行时间的有效性进行了实验,并与基于压缩感知的FOMP人脸识别算法[1]进行了比较。如表1所示为Yale A 人脸识别结果,其中运行时间为105幅测试图像运行总时间。如表2所示为ORL人脸识别结果,其中运行时间为240幅测试图像运行总时间。
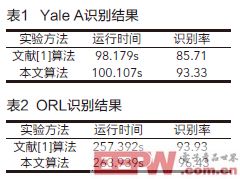
(1)由表1实验结果,本文算法因进行了小波包变换构成基函数字典,提取了整体特征和局部细节特征,对表情、姿态的变化鲁棒性高一些,进而识别率有一定优势。虽然本文未进行运算量高的正交匹配算法寻找最优稀疏解,小波包变换也能起到降维作用,但由于进行小波包变换占用时间,使得本算法时间上仍有一定劣势。
(2)由表2实验结果,得知两个算法的识别率都有提升,说明压缩感知对姿态有一定的鲁棒性,而本文算法识别率上仍然有一定优势,说明小波包变换构成基函数字典,增强了算法的姿态鲁棒性。
(3)通过对表1实验结果分析,发现本算法错误识别的人脸图像大多光照较弱或光照不均匀,说明本文算法对光照的鲁棒性能较差。分析其原因,在光照较差的情况下,图像是人脸的概貌,纹理信息较弱,使得小波包变换不能有效的提取细节特征,影响了识别率。
4 结束语
本文提出了一种基于小波包变换和压缩感知的人脸识别算法,与传统方法相比,本文采用基函数字典表示,将小波包变换和压缩感知相结合,充分利用了小波包变换和压缩感知的优势,克服其缺点,使得识别率得到了提升,时间复杂度也得到了有效的控制。同时本算法不需要对图片进行预处理,对遮挡物、表情有很好的鲁棒性。但本文算法对光照的鲁棒性能较差,还需要进一步研究加以改善。
参考文献:
[1]郑轶,蔡体健.稀疏表示的人脸识别及其优化算法[J].华东交通大学学报,2012,29(1):10-14
[2]Wagner A,Wright J.Toward a practical face recognition system: robust alignment and illumination by sparse representation[J]. IEEE Transactions on Pattern Analysis and Mac-hine Intelligence,2012,34(2):372-386
[3]Hsieh C K,Lai S H.Expression-invariant face recognition with Constrained optical flow warping[J].IEEE Transactions on Multimedia,2009,11(4):600-610
[4]Huang J,Yuen P C.Choosing Parameters of kernel subspace LDA for recognition of face images under pose and illumination variations[J].IEEE Transactions on Cybernetics,2007,37(4):847-862
[5]Yang A Y,Zhou Z H.Fast L1-Minimization Algorithms for Robust Face Recognition[J].IEEE TRANSACTIONS ON IMAGE PROCESSING,2013,22(8):3234-3246
[6]平强,庄连生,等.姿态鲁棒的分块稀疏表示人脸识别算法[J].中国科学技术大学学报,2011,41(11):975-981
[7]李月琴,栗苹,等.无线电引信信号去噪的最优小波基选择[J].北京理工大学学报,2008,28(8):723-726
[8]Chan W L,Choi H,Baraniuk R G.Coherent multiscale image processing using dual-tree quaternion wavelets[J].IEEE Transactions on Image,2008,17(7):1069-1082
[9]Inoue K,Kuroki Y.Illumination-robust face recognition via sparse representation[C].IEEE of Visual Communications and Image Processing, 2011:1-4
[10]Donoho D.Compressed sensing[J].IEEE Transactions on Information Theory,2006,52(4):1289-1306
[11]Soulard R,Carre P. Quaternionic wavelets for texture classification[J]. Pattern Recognition Letters,2011,32(13)1669-1678
[12]Oliver research laboratory[DB/OL].http//www.uk.research.att.Com/data/att_faces.Zip.Cambridge
全息投影相关文章:全息投影原理


评论