应用非对称双核MCU增强系统性能

本文从对比两颗分立MCU与单芯片双核MCU开始(以LPC4350为例),展开介绍了非对称双核MCU的基础知识与重要特点。接下来,重点介绍了核间通信的概念与几种实现方式,尤其是基于消息池的控制/状态通信。然后,对内核互斥、初始化流程等一些重要的细节展开了论述。最后提出了双核任务分工的两种应用模型,并分别举例。
背景与基本概念
在开发MCU应用系统时,如果单颗MCU无法满足系统的要求,一个很普遍的做法就是使用两颗或更多的MCU,把一部分“杂项工作”分配给另一个有“助理”性质的低端MCU来完成。但是,采用两颗MCU,缺点也很明显,尤其是在芯片与PCB成本、系统可靠性及功耗方面都有先天的不足。此外,若采用了不同架构的MCU,还要面临需要不同的开发工具与开发人员的挑战。如果换一种思路,让MCU内部包含两个内核,其中一个用于主控,另一个用于协控,并且它们主控与协控在架构上能够向下兼容、高效通信,则在很多场合下都可以既保持多机系统的强大,又能避免多机系统的不足。
事实上,这即是“非对称多处理器(简称AMP)”架构的特点。AMP是与“对称多处理器(简称SMP)”相对的架构,后者各处理器有一致的编程模型,并且在分配工作时主要以均衡为原则。而AMP的优点在于精细的任务分工,灵活地适应不同情景,物尽其用,以最佳地平衡成本、性能与功耗。此外,AMP的编程难度也更低。因此,在MCU应用领域,AMP较SMP更为适合。
与独立的双MCU相比,AMP架构有很多优点。其中相当关键的就是,再添加一个内核的代价远比添加一个独立的MCU要低,尤其是当两个内核架构相似时,甚至仅相当于在现有硅片上再添加一两个UART。另一方面,两个内核可以有相同的主频,并且可以通过总线矩阵平等地访问片上资源。而在分立的双MCU方案中,协控MCU的主频常常远低于主控,并且双方使用低速的串行链路通信。
接下来,我们以恩智浦(NXP)半导体公司新推出的LPC4300系列为例(尤以LPC4350型号为代表),对AMP MCU进行简单介绍。
AMP MCU一般用于相对大型的系统,这些系统对功能和性能都有较高的要求。在功能上,应支持较多的外设。LPC4350片载2个高速USB、2个CAN、工业以太网、图形LCD控制器,以及SDHC等接口;外加一些独有的逻辑可配置外设以及众多传统外设,适用于工控、能源、医疗、音频、车载、电机、监控等众多行业产品的开发。
性能的改善则是AMP MCU的灵魂。内核、存储器,以及总线架构对于性能有着至关重要的影响。图1展示了LPC4350的实现方式。
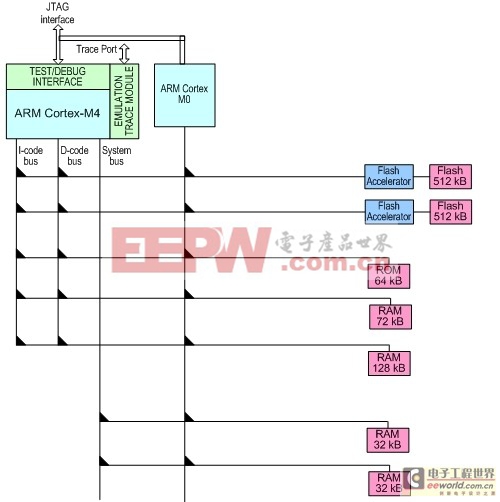
图1:LPC4350的内核、存储器以及总线连接图。
首先是内核的选择。LPC4350基于32位的ARM Cortex-M4和Cortex-M0内核(以下简称M4和M0),两个内核均可在高达204MHz的主频下执行代码。其中,M4以信号处理和浮点运算能力见长,胜任很多原先要采用DSP才能满足的应用,并且继承了Cortex-M3的控制能力;另一方面,M0以其成本、能效和处理能力的压倒性优势,正迅速吸引开发人员从8/16位架构向上过渡。更重要的是,M4完全向下兼容M0,使用同一套开发工具即可开发、调试。其次是存储器的容量和组织方式。LPC4350配备多达264KB片上RAM,并且这些RAM被划分成4组,每组连接一条单独的总线,而并非没有分块。如若不然,则会出现两个核竞争使用同一块RAM的情况——性能反而还不如只用单个内核!进一步,LPC4350还有两条总线连接到外部扩展的并行和串行存储器,故总共有6个独立的存储器地址空间——LPC4350无片上闪存。对于有片上闪存的型号,片上闪存也分为两块。
最后是总线架构。LPC4350内部有一个八层总线矩阵。它如同一组纵横开关,可以把CPU与包括存储器在内的众多从设备通过总线任意连接。合理分配总线接通关系,避免多个主设备(如CPU和DMA)同时访问相同的存储器或外设,可以最大地保证各条数据流并行不悖,从而可以充分发挥性能上的优势。
内核间通信
内核间的通信可分为两类:一类是控制与状态信息的通信,另一类则是数据通信。前者一般不携带数据,但往往有较高的实时要求;后者则主要是各类数据缓冲区,通常实时性要求偏低但数据量大。控制/状态通信有较大的通用性,并且与任务间的同步较为相似。这类通信适合由系统软件实现并提供编程接口。数据通信则往往与具体应用相关较大(尤其是在数据结构上),需要量体裁衣。在实现时,适合由应用软件定义各种数据结构。
内核间通过共享的RAM进行通信,并且每个内核都可以触发对方的一个中断源,通过准备数据-触发中断的方式进行通信,如图2所示。当然,内核也可以定期检查共享RAM的状态。
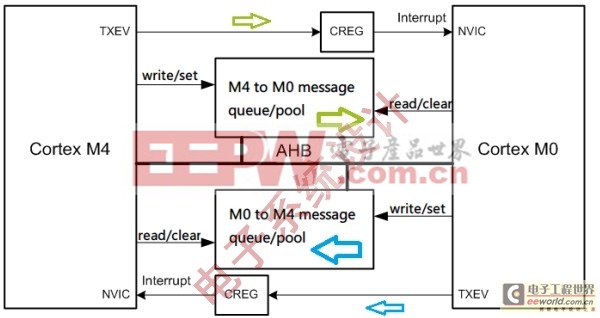
图2:内核间使用共享内存通信模式图。
接下来,我们介绍基于消息队列和消息池的控制/状态通信方案。
消息队列:开设两个消息队列,一个用于M4发送消息给M0,另一个则是M0发送消息给M4。两个队列的地址需事先约定好。队列是循环队列,可以使用简单的数组配以读、写下标来实现,也可以使用链表结构来实现。前者实现简单、开销小,但消息只能是定长,不便于携带其它信息,还有,就是必须把数组放置在共享内存区连续的位置,灵活性低。基于链表的实现用指针链接每则消息,每则消息除了公共的链表控制部分外,还可以根据消息类别携带各种各样的附加参数,并且可以由系统软件的内存管理机制灵活分配消息内存,不过,缺点是相对复杂,额外开销大。若涉及动态内存管理,实时性将远不如基于数组的方案。
消息队列有一个缺点,就是消息的串行化处理,它没有优先级的概念。但实际上,我们有实时操作系统(RTOS)及嵌套中断机制的支持,本应实现消息的并发处理。
消息池:消息池在存储结构上其实是简化的基于数组的消息队列——去掉了队列的读、写下标记录器。池中每个元素是一个消息,并且有一个字节指示每个元素的状态——空闲/已处理、新、半处理。当发送方写入消息时,扫描数组以查找空闲位置;当接收方读取消息时,也是扫描数组以查找状态。可见,消息池是基于优先级来处理消息的——小下标的元素优先得到处理。
消息池的可扫描性实现了消息的并发处理,并且可以通过中断上下文和任务上下文分两次“反刍式”处理。在处理消息池的中断服务例程中,先扫描各消息完成第一次处理,执行消息中(如果有的话)对实时性要求较高的部分。如果系统中没有使用RTOS,可以在后台的主循环中,再接下来二次扫描消息池,以完成第二次处理。对于使用了RTOS的系统,可以根据消息的优先级,创建或激活不同优先级的任务,使消息“附身”在这些任务的上下文中得到第二次处理。
消息池的一大缺点就是不宜支持较大数目的待处理消息。如有需要,可以给每则消息添加链表控制字段,我们可以把同一优先级的消息链成一串,从而彻底消除这一局限。
若干重要的细节
内核互斥:伪并行的多任务之间需要互斥访问共享资源,真并行的内核之间更是如此。尤其关键的是,一个内核无法关闭另一个内核的中断,因此还无法通过关中断临界区来保护。唯一能保证的,就是不会出现两个内核同时存取相同的地址。另外,由于架构上的局限,无法使用“自旋锁”来互斥。为此,我们可以通过施加一些编程准则来实现互斥。最简易有效的方法,就是在相同地址上给每个内核分别设置“只读”或“只写”的权限,或者是有条件的读写权限。比如,对于消息队列的读位置,只有接收方可以写,而发送方只能读取来判断队列是否空/满。又如,对于消息池,尽管发送方和接收方对池中的元素状态均可读可写,但有如下的条件:发送方只能把空闲状态改为非空闲;接收方只能把各种非空闲的状态改为空闲。再如,对于链表结构,可以只允许发送方更新各种指针;接收方通过更改链表中元素的状态和触发中断,以指示发送方更新各指针的时机。内核鉴别:M4向下兼容M0,这使我们可以重用很多的源代码。但是,有时需要鉴别当前正在哪个内核上运行。这有两种方法,分别用于不同场合:如果在编译期间鉴别即可,则可以在编译器设置中,预定义诸如“CORE_M4”和“CORE_M0”的宏,使用C/C++的条件编译来处




评论