七大统计模型详解

一、多元回归
本文引用地址:https://www.eepw.com.cn/article/201812/395418.htm1、概述:
在研究变量之间的相互影响关系模型时候,用到这类方法,具体地说:其可以定量地描述某一现象和某些因素之间的函数关系,将各变量的已知值带入回归方程可以求出因变量的估计值,从而可以进行预测等相关研究。
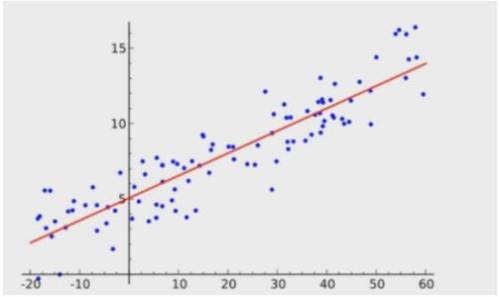
2、分类
分为两类:多元线性回归和非线性线性回归;
其中非线性回归可以通过一定的变化转化为线性回归,比如:y=lnx 可以转化为y=u u=lnx来解决;
3、 注意事项
在做回归的时候,一定要注意两件事:
(1) 回归方程的显著性检验
(2) 回归系数的显著性检验
检验是很多学生在建模中不注意的地方,好的检验结果可以体现出你模型的优劣,这点一定要注意。
二、聚类分析
1、概述:
聚类分析指将物理或抽象对象的集合分组为由类似的对象组成的多个类的分析过程。
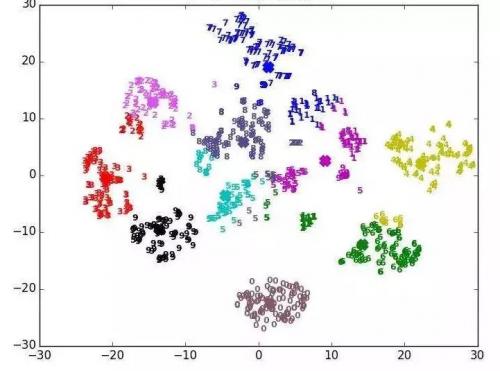
2、分类
聚类主要有三种:
(1) K均值聚类
(2) 系统聚类
(3)二阶聚类
类的距离计算方法:
(1) 最短距离法
(2) 最长距离法
(3) 中间距离法
(4) 重心法
(5) 类平均法
(6) 可变类平均法
(7) 可变法
(8) 利差平均和法
3、注意事项
在样本量比较大时,要得到聚类结果就显得不是很容易,这时需要根据背景知识和相关的其他方法辅助处理。
还需要注意的是:如果总体样本的显著性差异不是特别大的时候,使用的时候也要注意!
三、分类
1、概述
分类是一种典型的有监督的机器学习方法,其目的是从一组已知类别的数据中发现分类模型,以预测新数据的未知类别。
这里需要说明的是:预测和分类是有区别的,预测是对数据的预测,而分类是类别的预测。
2、常用分类模型:
(1)神经网络
(2)决策树
3、注意事项
A. 神经网络适用于下列情况的分类:
(1) 数据量比较小,缺少足够的样本建立数学模型
(2) 数据的结构难以用传统的统计方法来描述
(3) 分类模型难以表示为传统的统计模型
B. 神经网络的优点:
分类准确度高,并行分布处理能力强, 对噪声数据有较强的鲁棒性和容错能力,能够充分逼近复杂的非线性关系,具备联想记忆的功能等。
C. 神经网络缺点:
需要大量的参数,不能观察中间学习过程,输出结果较难解释,会影响到结果的可信度,需要较长的学习时间,当数据量较大的时候,学习速度会制约其应用。


评论