你想要的机器学习课程笔记在这:主要讨论监督学习和无监督学习

机器学习定义:A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E(一个程序从经验E中学习解决任务T进行某一任务量度P,通过P测量在T的表现而提高经验E(另一种定义:机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。)
本文引用地址:https://www.eepw.com.cn/article/201810/393509.htm监督学习:利用一组已知类别的样本调整分类器的参数,使其达到所要求性能的 过程,也称为监督训练或有教师学习。(样本有明确的标签和定义,数据间有明确的逻辑关系。通过已有的数据来预测未知的数据。),主要涉及回归问题和分类问题。

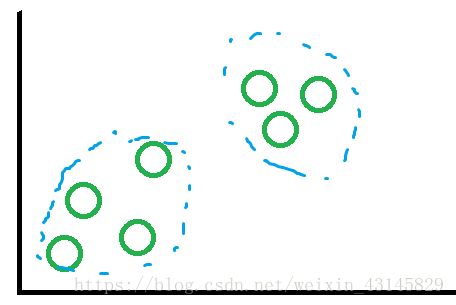
无监督学习:根据没有标记的数据样本识别各种问题。典型例子是聚类算法。
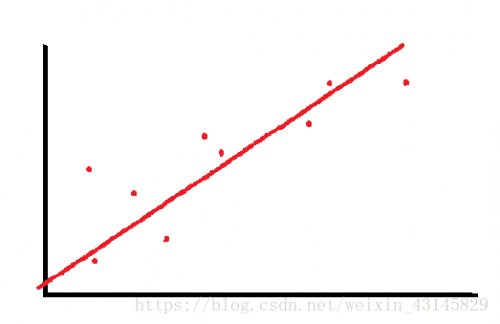
1.线性回归问题
设计一个函数,使它尽量满足我们所给出的数据(训练集,可能有很多个特征,这里简化假设只有一个特征也就是只有一个变量x,我们假设给出m组数据*),并可以对数据做出可信的预测。
如果我们的假设函数设为
hθ(x)=θ0+θ1x,此处的θ为模型参数,选择不同的θ0和θ1能够得到不同的函数图像。现在如何得到最能够拟合数据的一组θ0和θ1呢?
这个“最能拟合数据”可以理解为对每一个x,其预测值与真实值,也即
|hθ(xi)-yi| 最小,我们引入一个代价函数 J(θ0,θ1):
J(θ0,θ1)=1/2m∑(hθ(xi)-yi)^2
可以看出,我们的目的就是找出最适合的θ0和θ1,使代价函数J(θ0,θ1)的值最小。
要找出这个最小值,我们可以采用一种梯度下降的方法,在此之前,先得更深层次地理解代价函数。
我们先忽视θ0,那么代价函数是关于θ1的函数,要找出其最小值,通过图像可以看到:
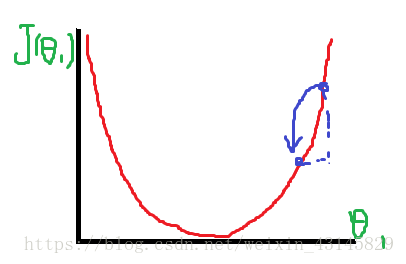
θ1取中间那一点就是我们所求值。我们可以从其他的点不断”逼近“最低点,具体操作为:
不断更新θ1:
θ1:=θ1-α/θ1*J(θ1)
后面那一项是J在θ1这一点的偏导数。可以理解为将θ1向其斜率方向偏移一点点,由于J(θ1)不断减小,偏移量也不断减小。这样随着不断更新,我们可以得到最终结果。
现在如果我们在引入θ0,那么代价函数是关于两个变量的函数,所成的图像是一个曲面,同样要找到”最低点“,应对两变量同时进行上面的更新。
同样的,如果特征量非常多,J是有关n个变量的函数,同样沿用上面的方法。
梯度下降的几个注意点:
更新式子的α可以理解为下降的”“步幅”,但α过小会导致回归速度很慢,需要更新多次。而α过大会导致无法达到最低点,在更新一次后可能越过最低点。
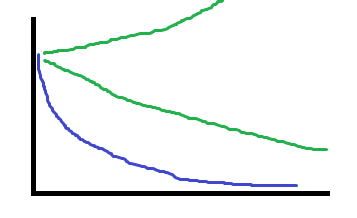
α(称为学习率)的选取可以观察(更新次数)~J的图像。
蓝色的曲线表示所取的α较合适,下面的绿色表示α过小,上面的绿色表示α过大。
对于θ的更新,式子可以展开简化为
*θi=θi-1/m∑(hθ(xi)-yi)xi
(i=0,1,2,3···n)其中x0=1;
特征缩放。对于有多个特征的数据,如果各个特征的范围比较接近,梯度下降法可以更快的收敛。
执行时更一般地将特征约束到-1到1之间。可以用这个式子:
xi=(xi-μi)/si其中μ为特征x的平均值,s为特征x的范围。
正则化问题。实际问题中一个结果可能和多个特征有关,如果特征过多,而训练数据较少,为了强行满足所有的数据,会出现“过拟合”现象:
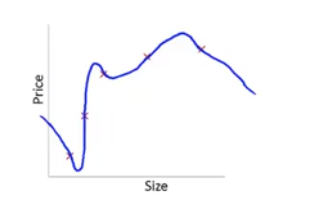
解决方法是尽量去掉不必要的特征量,或者进行正则化,将所有特征量减小(一般不包括x0)。
J(θ)=1/2m[∑(hθ(x)-y)2+λ∑θ 2](后面加的称为惩罚项)要让这个式子尽量小,那么θ就要尽量小,以此达到减小θ的目的。
将这个修改后的代价函数带入更新式。
θ=θ(1-αλ/m)-a/m∑(h(x)-y)x
这会使曲线相对平滑。正则化参数要设的大一点,但如果太大的话所有θ相当于不存在,曲线就会成一条水平直线。
2,分类问题
在分类问题中,我们简化模型为只有两个分类0和1.但数据的范围远在0至1之外,所以我们可以用logistic函数做处理:
h(x)=1/(1+e-fθ(x))
z为0时g(z)取0.5,g(z)在0到1之间
这样就可以将正负改为与0.5的大小区别,实际上h(x)=P(y=1|x;θ)
即得到的结果可以代表y为1的概率
这样当h(x)>0.5时我们可以认为对应的xi分类为使y为1,h(x)<0.5认为对应的xi使y为0。
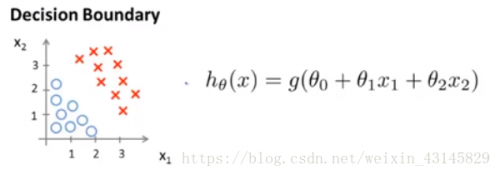
如图的h(x)将数据分为两部分,这条线叫做决策边界。在线内外的数据位置分别对应着与零的大小,概率表现在h(x)上。当然决策边界可以是不同形式的函数。



评论