苹果推高精度手写识别系统,可准确识别3万字符集

在手机、平板和可穿戴设备不断普及的今天,手写识别比以往任何时候都重要。但这并非易事,拿汉字来说,让移动设备识别大量手写汉字字符还是个挑战。
本文引用地址:https://www.eepw.com.cn/article/201709/364988.htm今天,苹果机器学习博客发表文章《Real-Time Recognition of Handwritten Chinese Characters Spanning a Large Inventory of 30,000 Characters》,介绍了苹果如何在iPhone、iPad和Apple Watch的Scribble模式中解决上述问题。
这套基于深度学习的识别系统,能准确处理多达3万个字符。为了提高准确性,苹果研究人员还特别注意了数据的收集环境、典型字体和训练方案。他们发现,这套系统还能支持更大的字符库。
苹果研究人员的实验表明,只要训练数据集的数量够大质量够好,准确率只会随着字符量的增加缓慢下降。量子位将这篇博客中的要点翻译整理,与大家分享——

简介
手写识别能够提高用户在移动设备上的体验,尤其适用于汉字这种相对复杂文字的使用者。由于汉字数量和书写样式多,手写识别确实是个大挑战。
字母类的语言也就涉及到100多个字母的排列顺序,但在中国国家标准GB 18030-2005《信息技术中文编码字符集》中就收录了27533个字符。
日常生活中,人们只用得到最具代表性的一小部分。因此,国标GB2312-80《信息交换用字符编码字符集·基本集》中仅包含6763个字符。中科院自动化研究所创建的CASIA数据库中所用字符有6763个,其中一级字符(常用字)3755个,二级字符(非常用字)3008个。
然而,早期识别算法主要依赖分析笔画的构造。后来,研究人员对研究汉字整体结构的方法产生了兴趣。由于众多汉字具有相似性,汉字识别的难度加大,研究人员通过分类降低错误识别。
在MNIST数据集的拉丁文任务中,卷积神经网络(CNN)崭露头角。因为训练数据足够大,根据需要补充合成样例,CNN无疑是最好的方法。美中不足的是,这些研究中分的类别很少。
当我们开始研究汉字的大规模识别时,CNN似乎是个不错的选择。但这种方法需要将CNN扩展至约3万个字符,并且在嵌入设备上实时保持性能。

系统结构
我们采用的是CNN通用架构,类似于之前在MNIST上手写识别实验中的架构。系统结构如图所示:
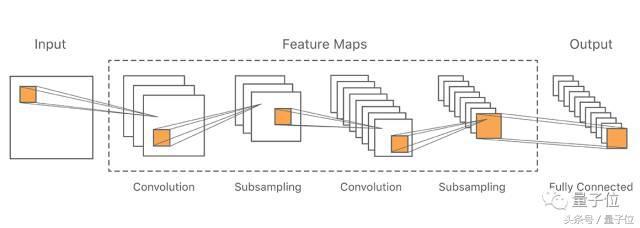
△典型的CNN架构
出于性能原因,我们将输入设定为一个中等分辨率的图像(48x48像素),这是普通手写汉字的大小。之后我们将它输入至特征提取层,交替进行卷积和子采样。最后一个特征提取层通过全连接层输出。
从一个卷积层到下一个卷积层,我们选择了kernel的大小和特征映射的数量得出粗粒度特征。通过用2x2 kernel,我们对最大池化层进行了采样,每个输出层都有一个节点。
下图展示了使用CNN的运行结果,其中“Hz-1”指的是一级字符库(3755个字符),“CR(n)”表示输入法界面排序为n的可能字符的准确度。除了常见的“最可能字”(top-1)和top-10的准确性外,我们也特意提到了top-4的准确性,因为输入法界面一开始会显示4个可能汉字,而top-4的准确性是用户体验提升的重要指标。

△在CASIA在线数据库3755个字符上的运行结果
除此以外,我们对在iOS设备内部收集的额外训练数据感兴趣。此数据涵盖了更多字体样式,并包含每个字符大量的训练实例。在同一个有3775个字符测试集的训练结果如下:

这次训练准确度有些许提高,总体来说,在测试集中出现的大多数汉字书写风格已经在CASIA训练集中得到了很好覆盖,也表明折叠训练数据不会使准确性下降,附加样式在对底层模型没有负影响。
扩展至3万字
我们想为用户提供从印刷体到草书等各种可能的输入字体。为了尽可能多涵盖不同的汉字书写风格,我们从中国几个地区找到了一些书法家的数据。让我们惊讶的是,大多数用户表示没有见过这些罕见的汉字。
因此,我们又收集了不同年龄段、性别和不同教育背景的用户数据,发现了各种各样的书写风格。下图显示了样例中“花”字在楷书、草书和“随便画几笔”风格下的样本。

事实上,在日常生活中,用户输入经常是“随便画几笔”,出现一种非常不相似的曲线变化。有时也会让系统混淆成其他字符。下图展示了我们在数据中观察到的一些具体例子。需要注意的是,有足够的训练数据能区分像Figure 7这样的草书变化很重要。

用这种方法,我们收集了大量汉字,将可识别字符从3755增加到大约3万。

△30000个字符在CASIA在线数据库的结果
为了解系统如何支持30000个手写字符识别,我们还在许多不同测试集上对其进行评估,这些测试集支持所有字体的字符。平均测试结果如下:

△不同字体的30000个字符在多个内部测试集的平均结果
当然,上面两张图的结果不能直接比较,因为它们属于不同的测试集上。但我们能发现,top-1和top-4的准确性相当,top-4达到了95.1%的准确率,结果尚好。
综上所述,我们在嵌入式设备上构建了覆盖3万个字符的高精度手写识别系统。只要有足够数量和质量的训练数据,识别准确度就不会大幅降低。未来,我们能精确识别的汉字字符还会更多。






评论