史无前例!苹果开诚布公谈机器学习

即使是如此重视保密的苹果,现在随着时势的改变,一些东西也和过去不一样了,最明显的莫过于它对人工智能和机器学习技术的态度。我们已经看到了一个更加开放的苹果,它在机器学习这个领域的进展如何呢?今天大家已经可以清楚地了解了。
本文引用地址:https://www.eepw.com.cn/article/201707/362056.htm

我们都知道苹果是一家特别注重保密文化的公司,基本上只有在新产品公开的那一刻,你才会真正从官方的口中了解到它是什么样的,而它又使用了些什么材料和什么技术。这样的文化曾经为我们带来无数惊喜,但时过境迁,坚持这种作风的苹果似乎遇到了新的困境。
所以近两年来,我们看到了一个和过去不太一样的苹果。它比起以往,似乎更加愿意和外界分享自己的科技成果。当然了,保密策略肯定是主旋律,但好歹是有了例外 —— 比如说机器学习。
在这一段时间里,我们看到了苹果高管们更多地抛头露面,向媒体谈及他们对人工智能和机器学习的看法。在苹果的发布会中,“机器学习”成为了一个高频词汇。前一阵子,高管们还集体在访谈中放声“我们的机器学习技术也很先进”,并透露了公司一直以来对该技术的应用实例。
在这之后,苹果宣布旗下的人工智能团队可以参与相关的学术讨论,并允许研究者发表论文。不久前苹果的人工智能专家汤姆·格鲁伯还在 TED 大会上,阐述了苹果如何看待这种技术。对粉丝们来说,苹果这么做在过去几乎是不可想象的。
似乎是为了证明它之前的那些承诺真的不是空话,苹果就在刚刚开放了一个博客,专门刊载公司的机器学习进度。这前所未有的决定,将让我们看到苹果怎样的机器学习成就呢?
苹果的技术进展
我们都知道,人工智能有一项很重要的应用就是图像识别,而这也是苹果在最近几次系统升级中着重强调的,通过照片的自动整理分类,事实上我们也已经用上了这些技术。
那么要如何让设备能够准确判断图片上的东西究竟是什么呢?那就需要训练了。人类首先要找好大量被手动标注是某样物体的,确定无误的图片,比如最简单的“猫”、“狗”、“眼睛”这些,然后让机器去学习和辨认,这样它才能开始尝试自己识别类似的图片。
苹果表示,这样的过程成本实在是太高,因为要提高机器识别的准确率,图片数量必须非常庞大,据了解目前是 100 万张起步,如果还要再多人工标注就几乎不可能。而且,这些图片还得拥有足够的多样性,毕竟可以被标注为“猫”、“狗”、“眼睛”的图片种类太多了,太过单一,机器如果遇到更复杂的情况就可能会认不出了。
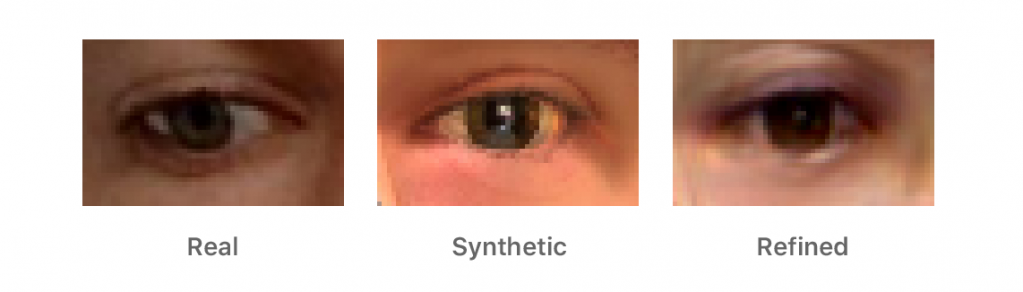
当然还有一种办法:既然人工标注图片数量越多越难实现,那么可以使用模拟的手段,自动生成海量自动被标注好的图片,让机器去不断进行识别。然而这种解决方案也有一个大问题,那就是自动生成的图片往往不够真实,这样会极大影响到人工智能识别图片的准确性。苹果的第一篇博文,就是尝试去解决这个难题的。
其实苹果的思路很简单:如果模拟器生成的图片不够真实,那就让它变得更真实就好了。有趣的是,研究者们为此又设计了一套学习网络。
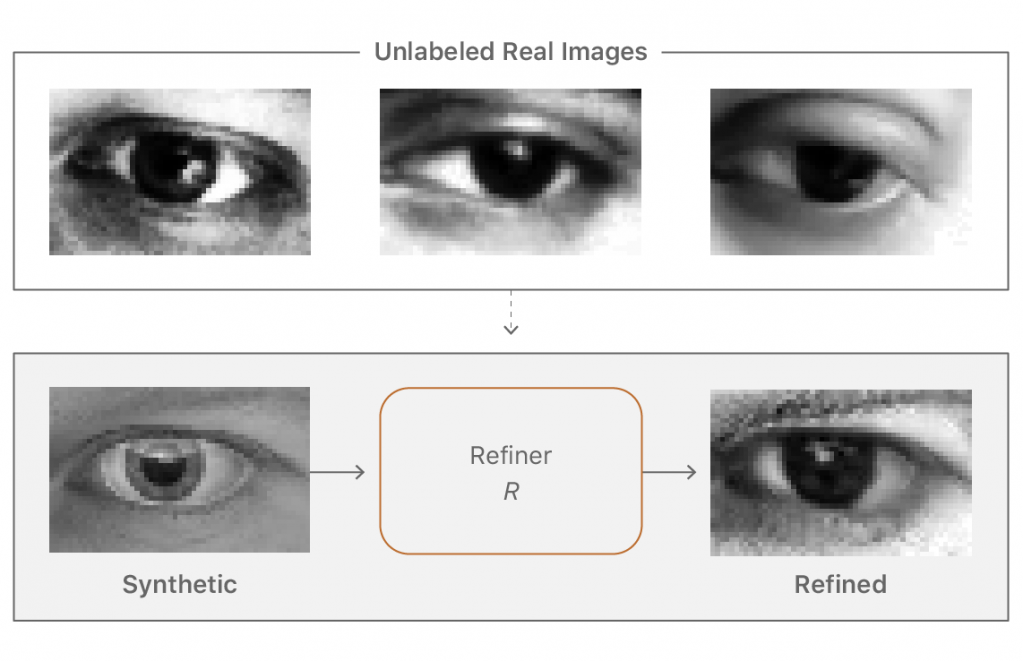
根据博文所说,苹果为达到这个目的,开发出了所谓的精制器(Refiner R)和辨别器(Discriminator D)。当模拟器生成图片后,精制器 R 负责让它变得更加真实,以通过辨别器的考验。辨别器的数据库中有大量的真实图片(有趣的是,苹果表示这些图片可以是未标注的 —— 又省一笔人工费),它负责根据这些真实图片,辨别精制器给它的图片是否为真。
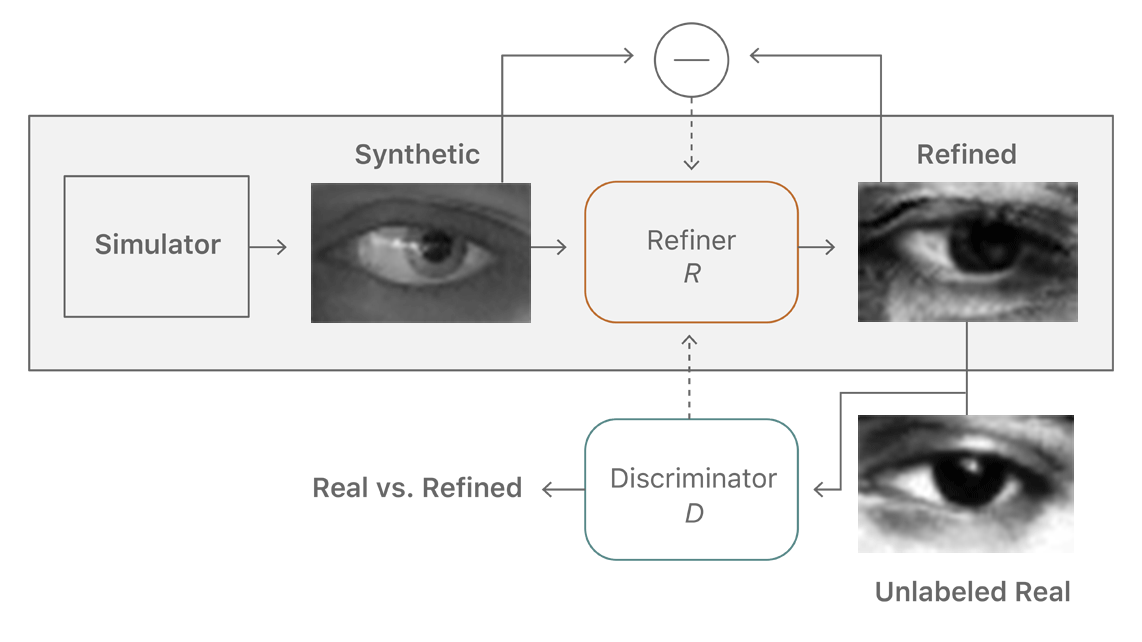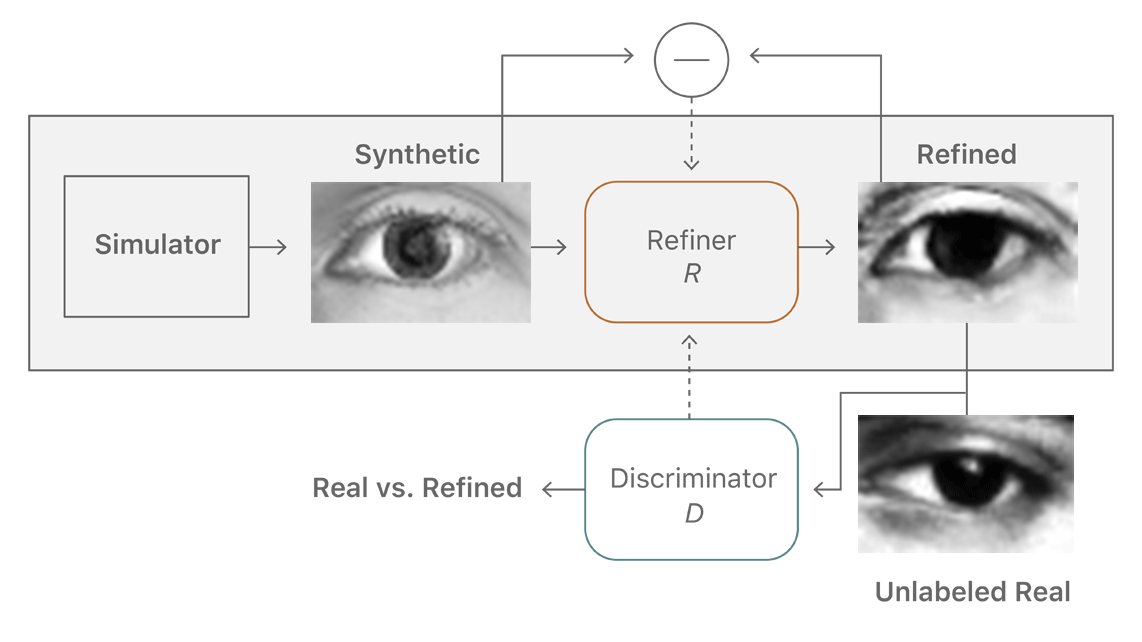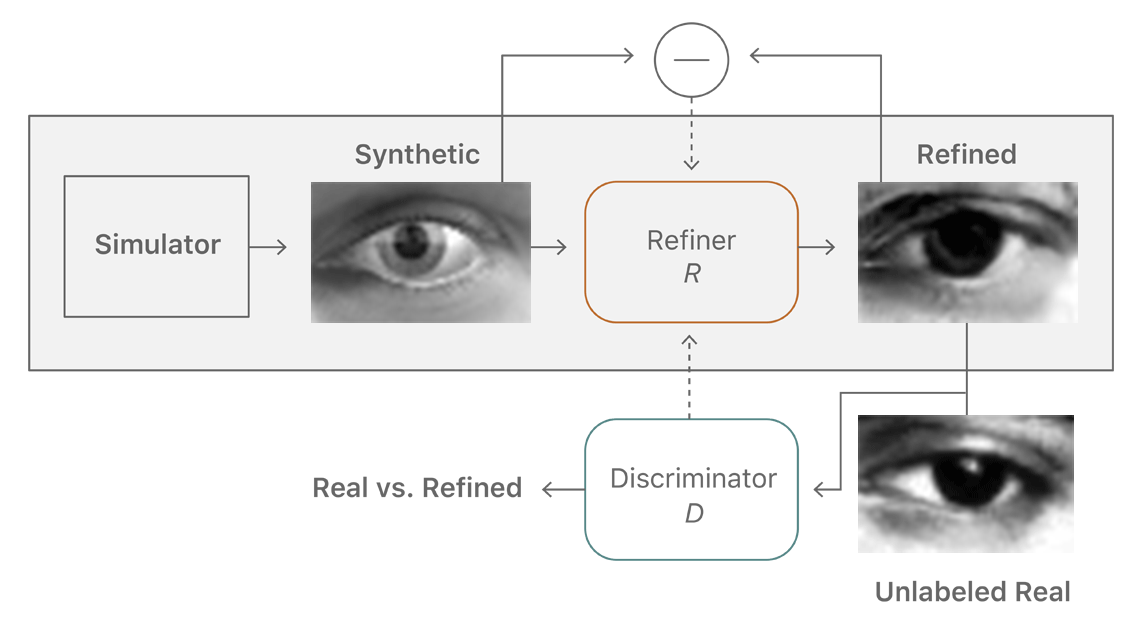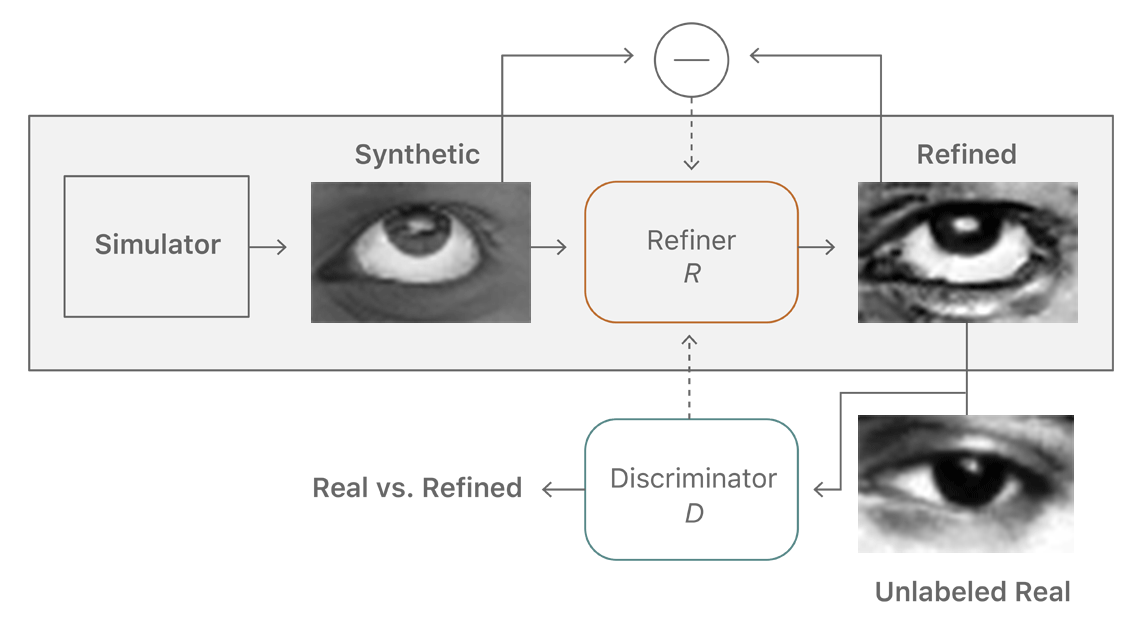
精制器千方百计要骗过辨别器,而后者则要努力认清前者的“鬼把戏”。两个机制在不断地“斗法”中提升着自己的能力,直到辨别器再也分不清,学习过程就算完成了。这样,就能够在不需要人工标注的情况下,生成海量接近真实的图片让人工智能不断去学习了,如此就可以大量减少成本。
还有一点很重要,那就是苹果必须要保证整个学习过程不“跑偏”。因为在精制器和辨别器不停较量和升级的过程中,难保会因为各种各样的因素,让精制器修改的图片和辨别器认定的标准开始走极端,让最终得到的图片直接变形。所以苹果加入了一些规范机制。
首先苹果将一幅图片分成许多部分,然后根据这些部分中的像素特征,对较量中出现的失真进行统计,失真偏差越大,判定损失就越大。除了局部的判定外,还有一个整体的自我规范损失机制,建立一个生成图片修改前后的差异对比。局部和整体结合,保证了图片不会在这个过程中发生很大的异变。除此之外辨别器本身也有记忆功能,能够记住那些之前已经被判定为假的图片。
还有一点很有趣,那就是苹果暂时还没有找到让系统自动判定学习中止的办法,目前只能是保存学习过程中的所有图片,人工目测生成图像已经和真实非常接近时中止学习。
采用了这样的解决方案,据说效果还是非常不错的。苹果曾邀请志愿者接受测试,10 位志愿者看了 1000 组图片,分别有真实图片和经过精制器修改的生成图片。成功分辨出真实图片的有 517 组,概率上接近 50%,说明人们无法确定图片真假,更多是 2 选 1 的概率。而当志愿者们去看真实图片和原始生成图片时,200 组图片他们成功分辨出了多达 162 组。
好戏还在后头
从苹果的这第一篇博文中,我们可以清楚地看到它在机器学习领域的进展和思路,可以说是史无前例的开诚布公。它这么做,自然是为了表明自己在人工智能领域并没有落后,希望能够因此吸引更多人才。
人工智能和机器学习作为苹果未来技术发展和产品功能开发的重头戏,我们会在越来越多的发布会上看到它们的身影。如果你对此曾经也有疑虑,那么苹果现在就是在不断表明自己的态度,让人们放心。
博客开了,这也只是第一篇博文而已。可想而知,未来苹果还会公布更多它的技术进展。在解决了图像识别的问题后,接下来它还会用机器学习来实现什么呢?这实在是让人期待啊。







评论