谷歌TPU研究论文:专注神经网络专用处理器

过去十五年里,我们一直在我们的产品中使用高计算需求的机器学习。机器学习的应用如此频繁,以至于我们决定设计一款全新类别的定制化机器学习加速器,它就是 TPU。
本文引用地址:https://www.eepw.com.cn/article/201704/346340.htmTPU 究竟有多快?今天,联合在硅谷计算机历史博物馆举办的国家工程科学院会议上发表的有关 TPU 的演讲中,我们发布了一项研究,该研究分享了这些定制化芯片的一些新的细节,自 2015 年以来,我们数据中心的机器学习应用中就一直在使用这些芯片。第一代 TPU 面向的是推论功能(使用已训练过的模型,而不是模型的训练阶段,这其中有些不同的特征),让我们看看一些发现:
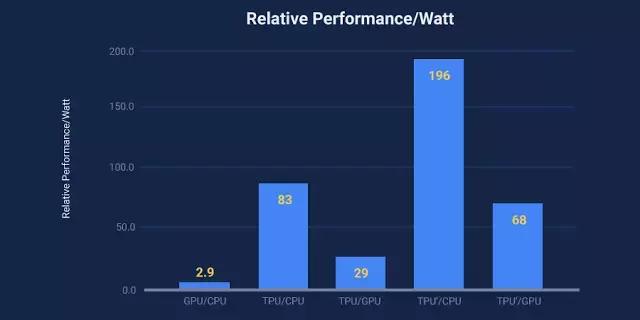
● 我们产品的人工智能负载,主要利用神经网络的推论功能,其 TPU 处理速度比当前 GPU 和 CPU 要快 15 到 30 倍。
● 较之传统芯片,TPU 也更加节能,功耗效率(TOPS/Watt)上提升了 30 到 80 倍。
● 驱动这些应用的神经网络只要求少量的代码,少的惊人:仅 100 到 1500 行。代码以 TensorFlow 为基础。
● 70 多个作者对这篇文章有贡献。这份报告也真是劳师动众,很多人参与了设计、证实、实施以及布局类似这样的系统软硬件。
TPU 的需求大约真正出现在 6 年之前,那时我们在所有产品之中越来越多的地方已开始使用消耗大量计算资源的深度学习模型;昂贵的计算令人担忧。假如存在这样一个场景,其中人们在 1 天中使用谷歌语音进行 3 分钟搜索,并且我们要在正使用的处理器中为语音识别系统运行深度神经网络,那么我们就不得不翻倍谷歌数据中心的数量。
TPU 将使我们快速做出预测,并使产品迅速对用户需求做出回应。TPU 运行在每一次的搜索中;TPU 支持作为谷歌图像搜索(Google Image Search)、谷歌照片(Google Photo)和谷歌云视觉 API(Google Cloud Vision API)等产品的基础的精确视觉模型;TPU 将加强谷歌翻译去年推出的突破性神经翻译质量的提升;并在谷歌 DeepMind AlphaGo 对李世乭的胜利中发挥了作用,这是计算机首次在古老的围棋比赛中战胜世界冠军。
我们致力于打造最好的基础架构,并将其共享给所有人。我们期望在未来的数周和数月内分享更多的更新。
论文题目:数据中心的 TPU 性能分析(In-Datacenter Performance Analysis of a Tensor Processing Unit)

摘要:许多架构师相信,现在要想在成本-能耗-性能(cost-energy-performance)上获得提升,就需要使用特定领域的硬件。这篇论文评估了一款自 2015 年以来就被应用于数据中心的定制化 ASIC,亦即张量处理器(TPU),这款产品可用来加速神经网络(NN)的推理阶段。TPU 的中心是一个 65,536 的 8 位 MAC 矩阵乘法单元,可提供 92 万亿次运算/秒(TOPS)的速度和一个大的(28 MiB)的可用软件管理的片上内存。相对于 CPU 和 GPU 的随时间变化的优化方法(高速缓存、无序执行、多线程、多处理、预取……),这种 TPU 的确定性的执行模型(deterministic execution model)能更好地匹配我们的神经网络应用的 99% 的响应时间需求,因为 CPU 和 GPU 更多的是帮助对吞吐量(throughout)进行平均,而非确保延迟性能。这些特性的缺失有助于解释为什么尽管 TPU 有极大的 MAC 和大内存,但却相对小和低功耗。我们将 TPU 和服务器级的英特尔 Haswell CPU 与现在同样也会在数据中心使用的英伟达 K80 GPU 进行了比较。我们的负载是用高级的 TensorFlow 框架编写的,并是用了生产级的神经网络应用(多层感知器、卷积神经网络和 LSTM),这些应用占到了我们的数据中心的神经网络推理计算需求的 95%。尽管其中一些应用的利用率比较低,但是平均而言,TPU 大约 15-30 倍快于当前的 GPU 或者 CPU,速度/功率比(TOPS/Watt)大约高 30-80 倍。此外,如果在 TPU 中使用 GPU 的 GDDR5 内存,那么速度(TOPS)还会翻三倍,速度/功率比(TOPS/Watt)能达到 GPU 的 70 倍以及 CPU 的 200 倍。
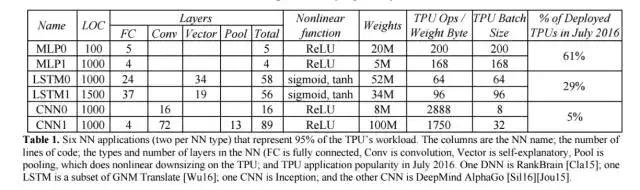
表 1:6 种神经网络应用(每种神经网络类型各 2 种)占据了 TPU 负载的 95%。表中的列依次是各种神经网络、代码的行数、神经网络中层的类型和数量(FC 是全连接层、Conv 是卷积层,Vector 是向量层,Pool 是池化层)以及 TPU 在 2016 年 7 月的应用普及程度。RankBrain [Cla15] 使用了 DNN,谷歌神经机器翻译 [Wu16] 中用到了 LSTM,Inception 用到了 CNN,DeepMind AlphaGo [Sil16][Jou15] 也用到了 CNN。
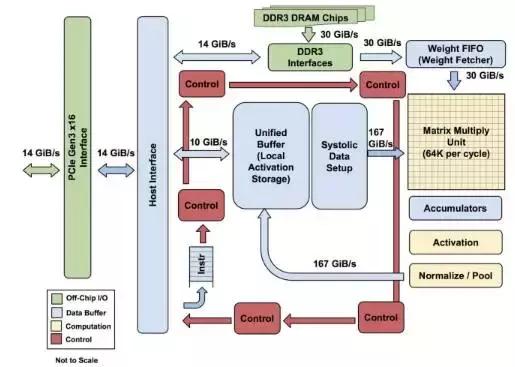
图 1:TPU 各模块的框图。主要计算部分是右上方的黄色矩阵乘法单元。其输入是蓝色的「权重 FIFO」和蓝色的统一缓存(Unified Buffer(UB));输出是蓝色的累加器(Accumulators(Acc))。黄色的激活(Activation)单元在Acc中执行流向UB的非线性函数。

评论