2016人工智能技术发展进程梳理

如果说2015年大家还在质疑深度学习、人工智能,认为这是又一轮泡沫的开始,那么2016年可以说是人工智能全面影响人们生活的一年。从AlphaGo到无人驾驶,从美国大选到量子计算机,从小Ai预测“我是歌手”到马斯克的太空计划,每个焦点事件背后都与人工智能有联系。纵览2016年的人工智能技术,笔者的印象是实用化、智能化、芯片化、生态化,让所有人都触手可及。下面我们以时间为坐标,盘点这一年的技术进展。
本文引用地址:https://www.eepw.com.cn/article/201702/343473.htm3月9-15日,棋坛新秀AlphaGo一战成名,以4:1成绩打败韩国职业棋手围棋九段李世石(围棋规则介绍:对弈双方在19x19棋盘网格的交叉点上交替放置黑色和白色的棋子,落子完毕后,棋子不能移动,对弈过程中围地吃子,以所围“地”的大小决定胜负)。
其实早在2015年10月,AlphaGo v13在与职业棋手、欧洲冠军樊麾二段的五番棋比赛中,以5:0获胜。在与李世石九段比赛中版本为v18,赛后,AlphaGo荣获韩国棋院授予的“第〇〇一号 名誉九段”证书。7月19日,AlphaGo在GoRantings世界围棋排名中超过柯洁,成为世界第一。
看到AlphaGo这一连串不可思议的成绩,我们不禁要问,是什么让AlphaGo在短短时间内就能以如此大的能量在古老的围棋这一竞技项目迅速击败数千年历史积累的人类?
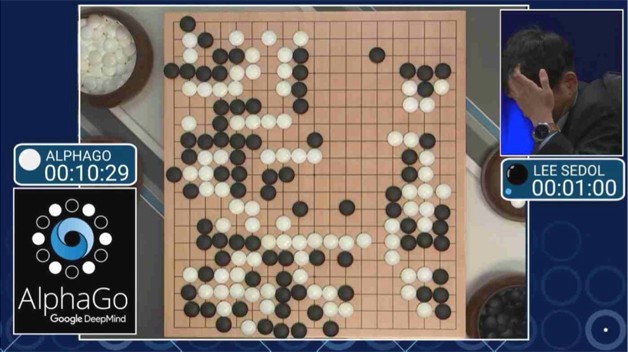
图1 AlphaGo与李世石的对阵
AlphaGo由Google在2014年收购的英国人工智能公司DeepMind开发,背后是一套神经网络系统,由许多个数据中心作为节点相连,每个节点内有多台超级计算机。这个系统基于卷积神经网络(Convolutional Neural Network, CNN)——一种在大型图像处理上有着优秀表现的神经网络,常用于人工智能图像识别,比如Google的图片搜索、百度的识图、阿里巴巴拍立淘等都运用了卷积神经网络。AlphaGo背后的系统还借鉴了一种名为深度强化学习(Deep Q-Learning,DQN)的技巧。强化学习的灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。不仅如此,AlphaGo借鉴了蒙特卡洛树搜索算法(Monte Carlo Tree Search),在判断当前局面的效用函数(value function)和决定下一步的策略函数(policy function)上有着非常好的表现。作为一个基于卷积神经网络、采用了强化学习模型的人工智能,AlphaGo具有广泛适应性,学习能力很强,除了玩游戏、下围棋,最近的DeepMind Health项目将人工智能引入了疾病诊断和预测中,为人们的健康提供更好的保障。
AlphaGo系统和IBM在上个世纪打败国际象棋大师卡斯帕罗夫的深蓝超级计算机有什么不同?
国际象棋AI算法一般是枚举所有可能招法,给局面打分。AI能力主要分为两方面:一是局面打分算法是否合理,二是迭代的深度。国际象棋开局的时候可以动8个兵(*2)和两个马(*2)共20种招法,虽然开局到中期招法会多一点,但是总数也就是几十种,游戏判断局面也简单,将军的加分,攻击强子加分,被将军或者有强子被攻击减分,控制范围大的加分,国际象棋里即将升变的兵加分,粗略一算就可以有个相对不错的判断。
围棋棋盘上每一点,都有黑、白、空,三种情况,棋盘上共有19*19=361个点,所以可能产生的局数为3的361次方种(可以想象,从137亿年前宇宙初始下起,60亿人口每天下60亿盘,到目前为止,只下了不到亿亿亿万分之一)。
围棋可选招法非常多,在初期可以全盘落子,打劫的时候则要找“劫材”。围棋判断形势的复杂度也很高,因为所有棋子地位平等,不在于一子定胜负,但每一子对于全局又都是牵一发而动全身,所以需要的是整体协调和全局决策。AlphaGo不仅能很快计算围棋当前局面的效用函数和决定下一步的策略函数,还能结合蒙特卡洛树搜索算法进行纵深的分析,得到整局棋的“最优解”。无论从计算复杂度还是决策的深度上,AlphaGo都有质的飞跃。
小结: AlphaGo可能是Google公关塑造的一个AI形象,但这是一次十分成功的尝试,引起了世界性的关注。在这些华丽的成绩之外,技术铺垫仍然是一项不容小觑的工作,包括DQN算法模型与硬件平台。我们接下来会详细介绍。
深度增强学习DQN
增强学习是最近几年中机器学习领域的最新进展。
增强学习的目的是通过和环境交互学习到如何在相应的观测中采取最优行为。行为的好坏可以通过环境给的奖励来确定。不同的环境有不同的观测和奖励。
增强学习和传统机器学习的最大区别在于,增强学习是一个闭环学习的系统,算法选取的行为会直接影响到环境,进而影响到该算法之后从环境中得到的观测。
增强学习存在着很多传统机器学习所不具备的挑战。
首先,因为在增强学习中没有确定在每一时刻应该采取哪个行为的信息,算法必须通过探索各种可能才能判断出最优行为。如何有效地在可能行为数量较多的情况下有效探索,是增强学习的重要问题。
其次,在增强学习中一个行为不仅可能会影响当前时刻的奖励,而且还可能会影响之后所有时刻的奖励。
在最坏的情况下,一个好行为不会在当前时刻获得奖励,而会在很多步都执行正确后才能得到。在这种情况下,判断出奖励和很多步之前的行为有关非常难。
虽然增强学习存在很多挑战,它也能够解决很多传统机器学习不能解决的问题。首先,由于不需要标注的过程,增强学习可以更有效地解决环境中所存在着的特殊情况。比如,无人车环境中可能会出现行人和动物乱穿马路的特殊情况。只要模拟器能模拟出这些特殊情况,增强学习就可以学习到怎么在这些特殊情况中做出正确的行为。其次,增强学习可以把整个系统作为一个整体,从而对其中的一些模块更加鲁棒。例如,自动驾驶中的感知模块不可能做到完全可靠。前一段时间,特斯拉无人驾驶的事故就是因为在强光环境中感知模块失效导致的。增强学习可以做到,即使在某些模块失效的情况下也能做出稳妥的行为。最后,增强学习可以比较容易学习到一系列行为。
自动驾驶需要执行一系列正确的行为才能成功驾驶。如果只有标注数据,学习到的模型每个时刻偏移了一点,到最后可能就会偏移非常多,产生毁灭性的后果。而增强学习能够学会自动修正偏移。
DeepMind曾用五款雅达利(Atari)游戏Pong、打砖块、太空侵略者、海底救人、Beam Rider分别测试了自己开发的人工智能,结果发现:游戏后,神经网络的操控能力已经远超世界上任何一位已知的游戏高手。
DeepMind用同样的一套人工智能,测试各种各样的智力竞技项目,取得了优异的战绩,足以证明坐在李世石面前的AlphaGo,拥有多强的学习能力。

图2 Atari游戏画面
小结:如果说深度学习相当于嗷嗷待哺的婴儿,需要人们准备好大量有营养的数据亲手喂给它,那么增强学习就是拥有基本生活能力的青少年,叛逆而独立,充满激情,喜欢挑战,不断在对抗中学习成长。虽然与成熟的人工智能仍有较大差距,但可以肯定,这只是个时间问题。










评论