MPEG声音编码的单片DSP实现

MPEG声音编码是一种基于人耳听觉特性的子带声音编码算法,它属于一种感觉声音编码方法.感觉声音编码算法的基本结构如图1所示.根据编码器着重于频率分辨率还是时间分辨率,可分为子带编码器和变换编码器.MPEG声音第2层编码算法在频域上把声音信号划分为32个子带,属于一种子带编码器.在图1中,时频映射也称滤波器组,用于把输入的声音信号映射成亚抽样的频率分量.根据使用的滤波器组的性质,即滤波器组在频域的分辨率的大小,这些频率分量又可叫做子带样值或频率线.
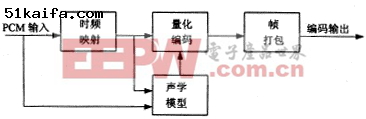
(a) (b) 图1 感觉声音***结构框图
滤波器的输出或者与滤波器组并行的时频变换的输出,提供给心理声学模型以估计时间相关的声音掩蔽门限.心理声学模型使用了人们所知的同时掩蔽效应,包括有调音的掩蔽特性和无调音的掩蔽特性.如果使用声音的前后掩蔽效应,还可进一步提高掩蔽门限估计的准确性.子带样值或频率线按照尽量保证量化噪声的频谱处于掩蔽门限以下的准则进行量化和编码,这样能保证被人耳感知的量化引入的噪声最小.根据对复杂度的要求,可以使用块压扩或熵编码的分析合成方法.
帧打包把量化编码的输出和相关边信息按照规定的格式组合起来,以便供***使用.
2 编码质量和DSP速度
单片ADSP-2181实现MPEG声音编码关键需要解决两个问题:一是如何保证声音编码质量;其次是如何充分利用DSP的运算速度.而这两个问题往往又是一对矛盾,需要找到其最佳结合点.
一般而言,决定MPEG声音编码器的优劣主要是声学模型的好坏.但是,对于使用单片16bit定点DSP的应用而言,这个结论就不再适用了.分析表明,此时有限字长效应对编码质量的影响成了主要矛盾.特别是分析滤波器组,截尾效应竟带来了33倍于16bitAD转换量化误差的噪声,而窗系数的有限长度表示则使本来高达96dB旁瓣衰减的滤波器响应降低到不到70dB.因此,要保证声音编码质量,分析滤波器组算法必须进行精度扩展.
关于速度问题,首先想到的是使用快速算法,我们也尝试了在子带滤波中使用快速算法[4].
但是,实践证明,这些快速算法使用在DSP上效果并不理想,其原因有以下3条:(1)只考虑了加法和乘法的次数,而对附值、寻址等操作毫不关心,但对所有指令都是单周期的DSP而言,乘法和加法的次数相对其他操作并不显得特别重要;(2)没有考虑DSP的硬件特点,其算法不能充分发挥DSP的乘累加器(MAC)并行处理的能力;(3)ADSP-2181是为16位算法操作优化的,在需要精度扩展的情况下,运算量将以数量级的速度急剧增加.
基于以上质量和速度要求的分析,我们选用了适合DSP乘累加指令的多相结构滤波器组实现方式,且采用基于MAC结构的精度扩展方法,较好地解决了编码质量和DSP速度之间的矛盾.另外,对抽样数据的输入方式、心理声学模型、比例因子编码都进行了适于ADSP-2181的改进,减少了运算量,保证了实时性.
3 算法的软件设计
软件设计是MPEG声音编码的单片DSP实现的核心,编码质量和速度的要求都需要通过精心设计DSP软件才能实现.
(1)基于MAC结构的精度扩展 MPEG声音编码的分析滤波器组可以有许多种实现方式,多相结构是MPEG标准推荐的一种,其数学表示为
(1) ![]()
(2) ![]()
分析表明,对Yk进行双字扩展可将截尾效应带来的噪声降低33倍.但是,考虑到ADSP-2181只支持16bit的乘累加运算,需要对式(1)进行转化,即
(3) Yk=HYk+2-16LYk
这样,就可利用DSP的乘累加器结构,运算量只增加约1倍,存储量只增加64个字.
(2)输入数据的组织 输入数据的组织不但要考虑方便地从数模转换器取得声音原始数据,还要考虑输入数据在片内数据RAM的存储适合作为多相滤波器组和声学模型的FFT运算的输入.多相滤波器组每次移入32个新的声音数据,移出32个旧的样值,操作如下:
Xi=Xi-32,i=511,510,…,32
Xi=next-input-audio-sample,i=31,30,…,0







评论