手撕大模型|KVCache 原理及代码解析

一、为什么需要 KV Cache?
需要 重新计算所有之前 token 的 K 和 V,并与当前 token 进行注意力计算。
计算复杂度是 O(n²)(对于长度为 n 的序列)。
只需计算 新 token 的 K 和 V,然后将其与缓存的值结合使用。
计算复杂度下降到 O(n)(每个 token 只与之前缓存的 token 计算注意力)。
二、KV Cache 的工作原理
初始输入: [t0, t1, t2] 首次计算: K=[K0,K1,K2], V=[V0,V1,V2] → 生成t3 缓存状态: K=[K0,K1,K2], V=[V0,V1,V2] 第二次计算: 新Q=Q3 注意力计算: Attention(Q3, [K0,K1,K2]) → 生成t4 更新缓存: K=[K0,K1,K2,K3], V=[V0,V1,V2,V3] 第三次计算: 新Q=Q4 注意力计算: Attention(Q4, [K0,K1,K2,K3]) → 生成t5 更新缓存: K=[K0,K1,K2,K3,K4], V=[V0,V1,V2,V3,V4] ...
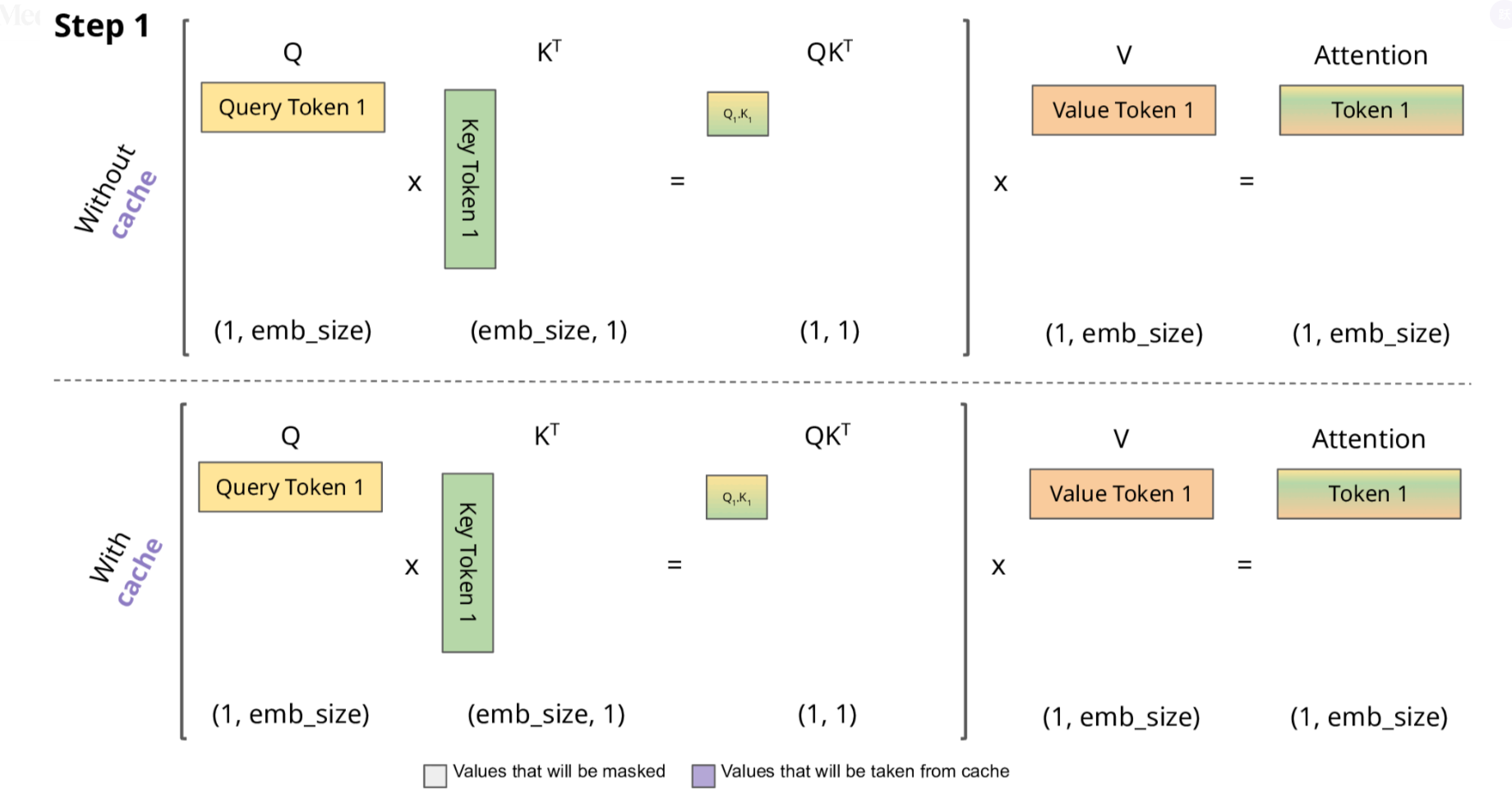
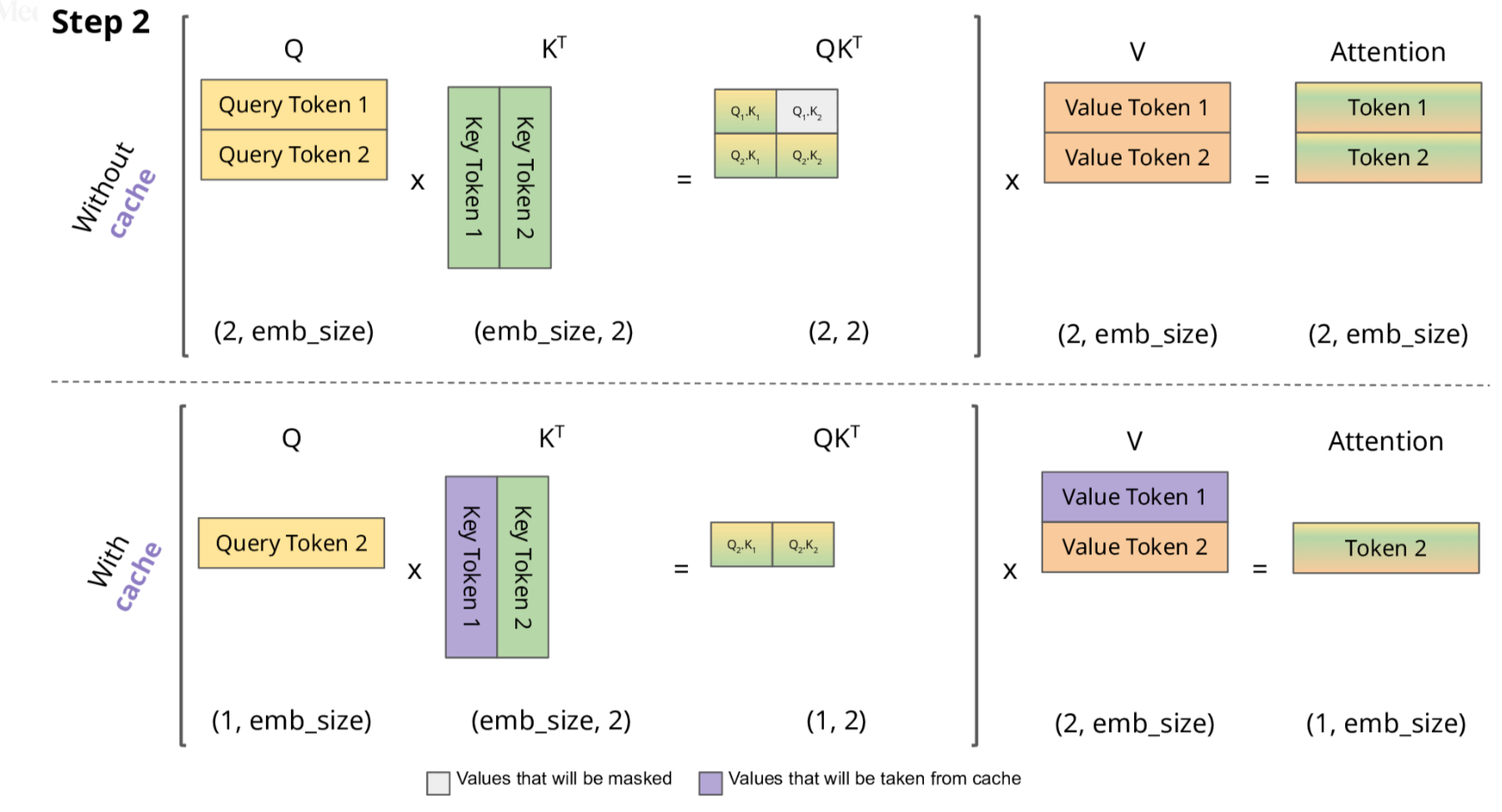
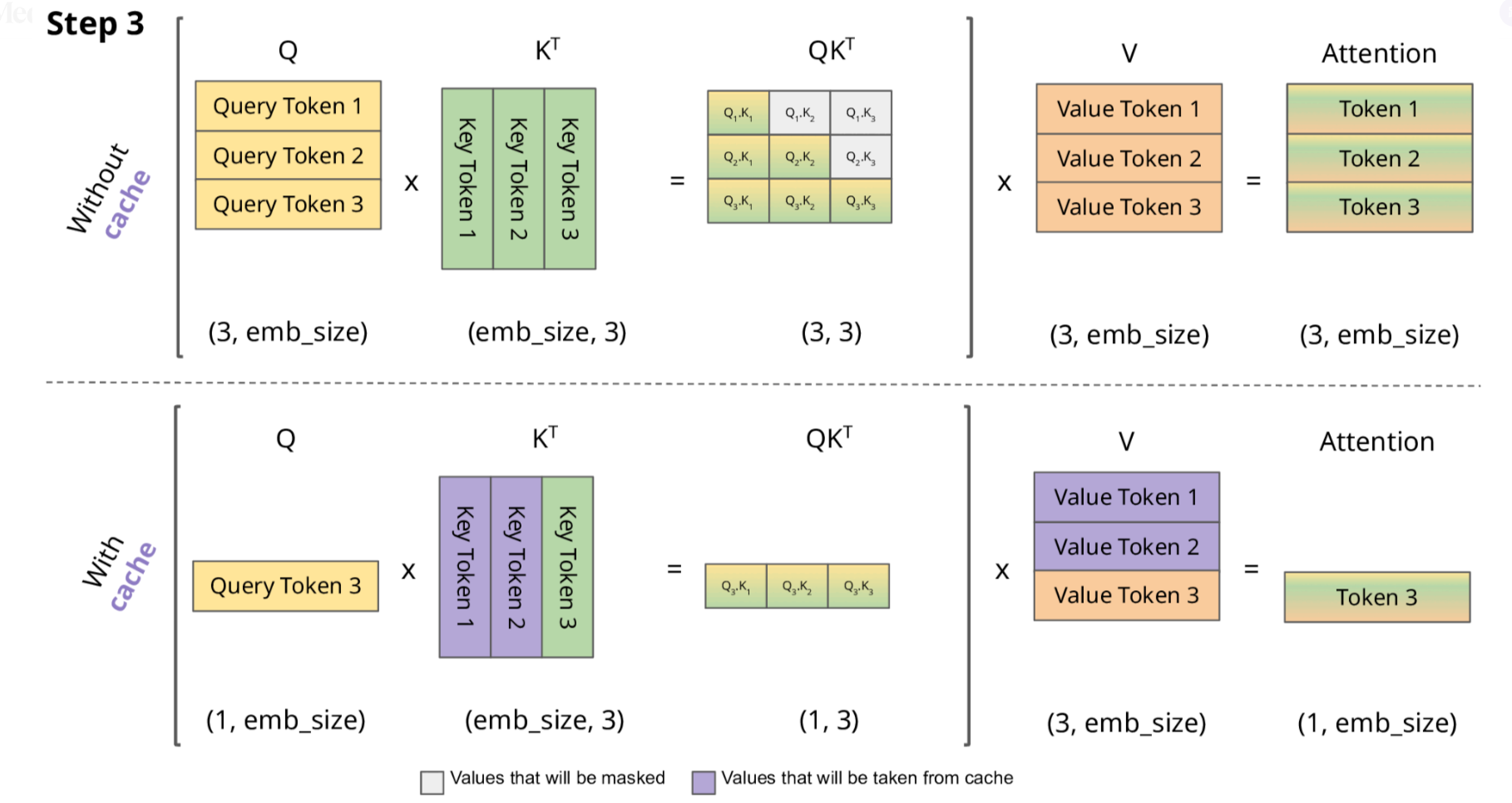
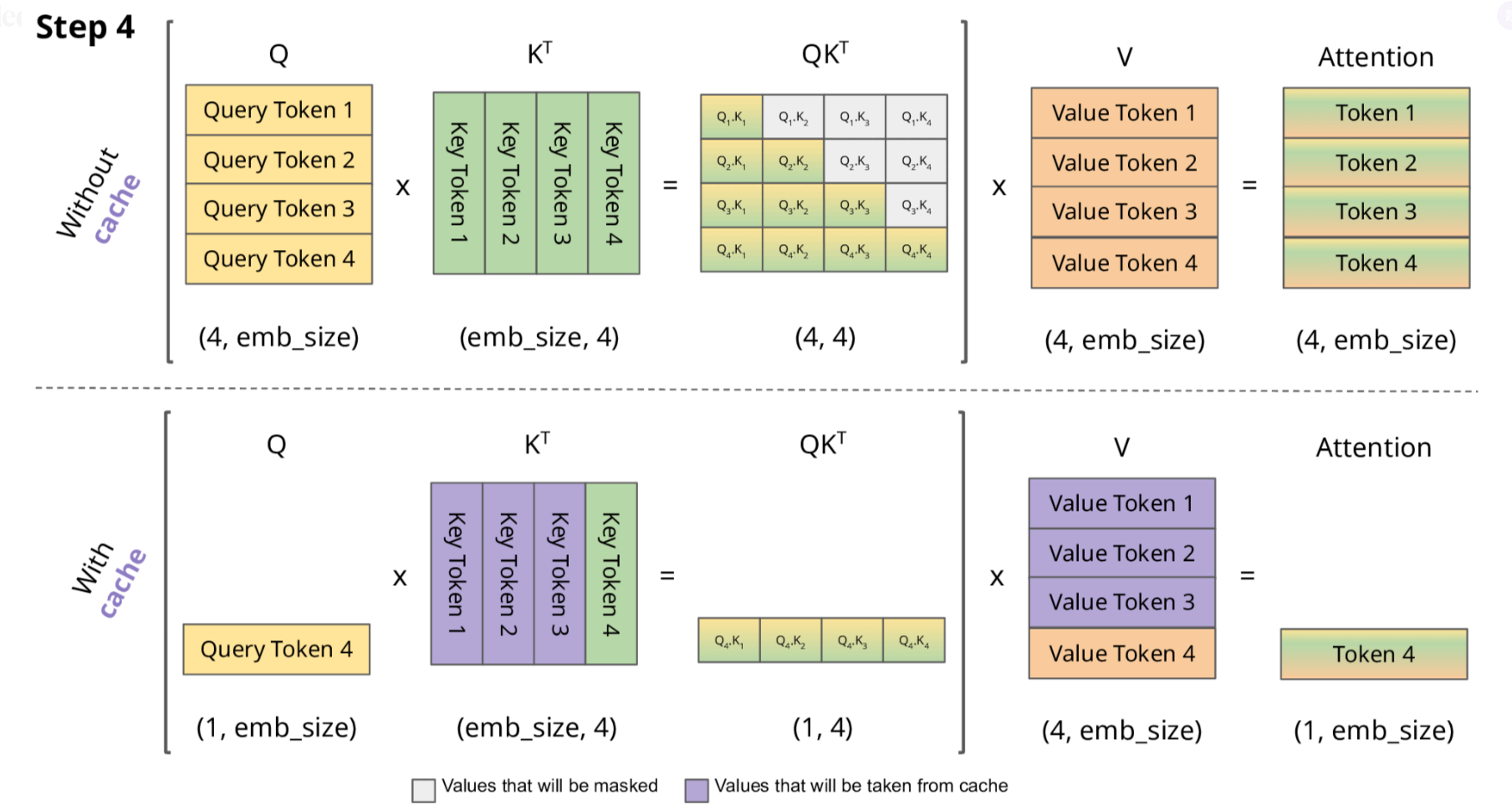
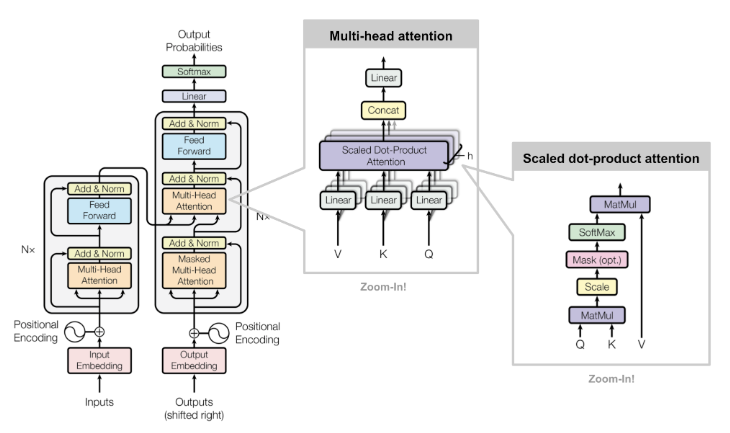
2.1 KV Cache 的技术细节
四、代码实现解析
import torch import torch.nn as nn import torch.nn.functional as F class SelfAttention(nn.Module): def __init__(self, embed_dim, num_heads): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads # 定义Q、K、V投影矩阵 self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) self.out_proj = nn.Linear(embed_dim, embed_dim) def forward(self, x): batch_size, seq_len, embed_dim = x.shape # 计算Q、K、V q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) # 计算注意力分数 attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) attn_probs = F.softmax(attn_scores, dim=-1) # 应用注意力权重 output = attn_probs @ v output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim) return self.out_proj(output)
class CachedSelfAttention(nn.Module): def __init__(self, embed_dim, num_heads): super().__init__() self.embed_dim = embed_dim self.num_heads = num_heads self.head_dim = embed_dim // num_heads # 定义投影矩阵 self.q_proj = nn.Linear(embed_dim, embed_dim) self.k_proj = nn.Linear(embed_dim, embed_dim) self.v_proj = nn.Linear(embed_dim, embed_dim) self.out_proj = nn.Linear(embed_dim, embed_dim) # 初始化缓存 self.cache_k = None self.cache_v = None def forward(self, x, use_cache=False): batch_size, seq_len, embed_dim = x.shape # 计算Q、K、V q = self.q_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) k = self.k_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) v = self.v_proj(x).view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2) # 如果使用缓存且缓存存在,则拼接历史KV if use_cache and self.cache_k is not None: k = torch.cat([self.cache_k, k], dim=-2) v = torch.cat([self.cache_v, v], dim=-2) # 如果使用缓存,更新缓存 if use_cache: self.cache_k = k self.cache_v = v # 计算注意力分数(注意这里的k是包含历史缓存的) attn_scores = (q @ k.transpose(-2, -1)) / (self.head_dim ** 0.5) attn_probs = F.softmax(attn_scores, dim=-1) # 应用注意力权重 output = attn_probs @ v output = output.transpose(1, 2).contiguous().view(batch_size, seq_len, embed_dim) return self.out_proj(output) def reset_cache(self): """重置缓存,用于新序列的生成""" self.cache_k = None self.cache_v = None
def generate_text(model, input_ids, max_length=50): # 初始化模型缓存 model.reset_cache() # 处理初始输入 output = model(input_ids, use_cache=True) next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True) generated = [next_token] # 生成后续token for _ in range(max_length - 1): # 只输入新生成的token output = model(next_token, use_cache=True) next_token = torch.argmax(output[:, -1, :], dim=-1, keepdim=True) generated.append(next_token) # 如果生成结束符则停止 if next_token.item() == 102: # 假设102是[SEP]的id break return torch.cat(generated, dim=1)
五、KV Cache 的优化策略
六、总结
七、参考链接
专栏文章内容及配图由作者撰写发布,仅供工程师学习之用,如有侵权或者其他违规问题,请联系本站处理。 联系我们
关键词:
算法
自动驾驶
算法工具链
地平线
征程5
相关推荐
高阶智驾要落地,线控底盘为什么必须执行得准
数字PID控制算法之一
CRC算法原理及C语言实现
基于LPC2138的血压测量算法开发平台电路图
Ouster推出 Rev8 OS 激光雷达系列 原生彩色激光雷达正式落地
采用Mean-Shift和Camshift算法相结合的火焰视频图像跟踪设计
自动驾驶的现状与未来(节选)
特斯拉监督版FSD加入中国市场
目标跟踪算法在红外热成像跟踪技术上的应用
计算机科学与技术反思录(2)
自动驾驶正推动汽车行业加速布局人形机器人
76-81GHz自动驾驶CMOS RADAR
加密算法之MD5算法
加快实现自动驾驶(完整小组讨论)
掘金自动驾驶,不要把大坑当机会
简单实用的单片机CRC 快速算法
[转帖]us/os就绪表的维护算法分析
vxwokrs下静态图像压缩算法(上)
PID算法
地平线征程 6 系列集成 Cadence Tensilica Vision DSP,实现规模化量产,合作加速智能驾驶解决方案部署
有关指纹算法
面向算法硬件加速的FPGA实现方法
曲面显示屏取代传统汽车挡风玻璃
实时训练驾驶人工智能
携手ADI赢得未来
2035年自动驾驶出租车市场规模将达1680亿美元
无线传感器网络低功耗分簇路由算法设计
求FSK信号的解调算法,主要是铁路上的移频信号!
ADI:传感技术助力未来自动驾驶的发展
数字PID控制及其改进算法的应用