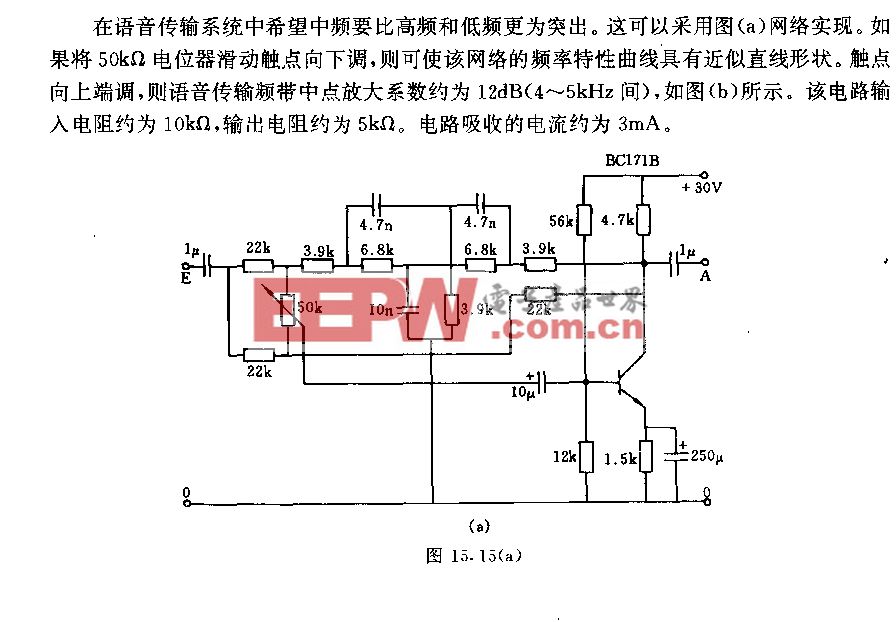
新手 C 开发者犯的十大错误:快速实用指南

C 语言赋予开发者强大的能力 —— 既能用来研发航天器,也能让你的笔记本电脑在午饭前就彻底瘫痪。这份清单不是空洞的说教,而是一份实用指南,专门指出新手开发者反复踩坑的那些问题。这些漏洞轻则让人头疼不已,重则有时会按需触发故障,有时却又几乎无法复现。
这类问题在团队处于开发冲刺阶段时,危害尤为严重。不过值得庆幸的是,其中很多错误都十分典型,我们能够将它们一一列举、剖析,并帮助你养成良好的编码习惯,让代码以最佳的方式趋于 “平淡”:在不同编译器、不同优化级别和不同平台下,都能表现出可预测性。
这些技巧适用于所有开发者,同时本文还给出了遵循 MISRA C/C++ 等标准的相关建议。
C 语言新手在为文本分配内存时,总想着 “刚刚好”—— 结果却多写了一个字节的数据(见图 1)。你根据字符串有 n 个字符,就将缓冲区大小设为 n,然后问题来了:你忘了字符串结束符也需要占用一个字节的空间。这个缺失的字节正是许多隐性缓冲区溢出问题的根源,甚至可能导致日志输出演变成内存损坏故障。这类问题具有确定性和可复现性,而且危害极大。

图 1 字符串 “差一错误” 示例:忘记字符串结束符(NUL)
专业修复方案:为 C 语言字符串分配内存时,务必预留长度+1的空间;优先使用snprintf函数(而非sprintf),并检查其返回值;读取字符串时,使用strnlen函数限制读取长度。若存在疑问,可先用memset函数初始化缓冲区,并在写入数据后,断言缓冲区的最后一个字节为 0。经验法则:如果统计了字符个数,就要加 1;如果没统计,那你就得问问自己为什么了。
2. 有符号 / 无符号类型混用:让 - 1 变成 40 亿
你将一个int类型变量(比如某个函数返回的错误码 - 1)与size_t类型变量(数组长度)进行比较,此时编译器会将int类型提升为无符号类型 —— 没错!这正是 C 语言标准规定的行为。这么一来,原本的 - 1 就摇身一变成了 4294967295,你所做的边界检查形同虚设,直接为程序崩溃敞开了大门(见图 2)。

图 2 有符号 / 无符号类型混用示例:让 - 1 引发 40 亿量级的问题
这类问题同样具有确定性和可复现性,而且隐蔽性极强。修复方案:全程使用size_t类型表示尺寸和索引;仅在 API 接口处使用显式的窄化类型转换;通过独立的渠道(比如专门的返回码)传递错误信息,而非用负数作为无效的长度值;开启编译器的-Wsign-compare警告选项。若确实需要混用类型,务必先进行标准化处理 —— 在转换为size_t类型前,验证数值是否大于等于 0,并通过断言来确认你的假设。另外,千万要重视编译器给出的警告信息,这些警告其实就是潜伏的漏洞,随时可能 “反噬” 你!
3. 误以为strncpy函数 “绝对安全”,最终导致未终止字符串被投入使用
strncpy函数看似是编程路上的 “救生衣”,但你迟早会发现:当源字符串过长时,它并不会保证目标字符串以结束符结尾(见图 3)。你以为得到了一个 “安全” 的缓冲区,结果里面的数据打印出来全是乱码,解析器无法识别,strcmp函数也无法正常工作。更糟的是,当源字符串较短时,strncpy会用 0 填充缓冲区剩余空间,造成算力浪费。

图 3 误用strncpy函数示例:误以为其 “安全”,最终导致未终止字符串问题
正确做法:如果需要在截断字符串的同时保证其以结束符结尾,请使用snprintf函数(并检查返回值)。若必须使用strncpy,则要在调用后立即手动添加结束符:buf[n-1] = '�'。这是一条简单易守的规则,不要随手写一些临时代码就想着 “以后再优化”—— 你很可能永远都不会回头处理,除非这个漏洞在实际应用中暴露出来。
4. 循环 “差一错误”:越界访问缓冲区
这是一个经典错误写法:for (i = 0; i <= len; ++i)。这个循环会写入len+1个元素,破坏数组末尾之后的字节数据。更要命的是,如果循环变量的值达到了其所能存储的最大值,就会引发无限循环(见图 4)。

图 4 循环 “差一错误” 示例:越界访问缓冲区
优秀的编译器会预判到这种情况的发生,因此这种循环结构会导致许多实用的循环优化技术无法生效。这类问题具有确定性和可复现性,而且往往只在输入数据 “刚好达到某个临界值” 时才会触发崩溃。修复方案:遵循严格的不变式规则:遍历数组元素时,使用i < len的条件;只有当索引指向实际分配的结束符位置时,才使用i <= len。对于以结束符结尾的字符串,写入数据时循环到i < n-1即可,之后再手动设置buf[i] = '�'。在调试版本中,为边界条件添加断言。
5. 对重叠内存区域使用memcpy函数,而非memmove函数
memcpy函数的设计前提是:源内存区域和目标内存区域互不重叠。一旦两者重叠,函数行为就会变得未定义,进而导致可预测的内存数据损坏。当你需要在同一个缓冲区中移动字节数据(比如删除前缀、就地插入数据)时,务必使用memmove函数 —— 它能正确处理内存区域重叠的情况(见图 5)。经验法则:同一缓冲区 + 可能存在重叠 → 使用memmove;确保无重叠 → 使用memcpy。

图 5 内存拷贝错误示例:对重叠区域误用memcpy而非memmove
6. 返回指向局部变量的指针或引用
你在栈上创建了一个缓冲区,然后返回&buf[0]—— 紧接着,函数执行结束,该局部变量的生命周期也随之终结。此时调用者拿到的是一个指向无效内存区域的指针,在简单测试中可能 “看起来正常”,但最终一定会引发确定性的程序崩溃(见图 6)。

图 6 指针返回错误示例:返回指向局部变量的指针或引用不可取
修复方案:让调用者提供目标缓冲区及其大小;或者使用malloc函数动态分配内存,并明确标注由谁负责释放该内存。经验法则:变量在栈上创建,就会随函数结束而销毁 —— 别把指向 “幽灵内存” 的指针传给别人。
7. switch语句中遗漏break:导致意外的贯穿执行
你匹配到了正确的case分支,却因为忘了写break语句,导致程序接着执行了下一个分支的代码。这种问题每次运行都会稳定复现,有时还会产生荒诞的错误结果(见图 7)。

图 7 switch语句错误示例:遗漏break导致意外贯穿执行,危害不小
修复方案:在每个case分支末尾都加上break或return语句;如果确实需要故意触发贯穿执行,务必用醒目的注释标注/* fallthrough */,并开启编译器的-Wimplicit-fallthrough警告选项。附赠专业小技巧:始终为switch语句添加default分支,哪怕你觉得已经覆盖了所有可能的情况。可以在default分支中加入断言,说不定会在不经意间帮你发现隐藏的漏洞。
8. 对指针使用sizeof运算符,误以为能得到数组长度
你将一个数组传入函数,数组会自动退化为指针;此时对指针使用sizeof(ptr),得到的结果是 8(或 4),而非数组的元素个数。这会直接导致内存分配不足、数据拷贝不完整等严重问题(见图 8)。

图 8 sizeof运算符误用示例:对指针使用sizeof,误以为能获取数组长度
经验法则:sizeof运算符只认识它直接作用的对象。要在数组声明的位置计算其长度(公式:sizeof arr / sizeof arr[0]),并将长度值与指针一起传入函数。
9. 内存分配与释放函数不匹配:new搭配delete[]、malloc搭配delete
在 C 语言中,规则很简单:每一次malloc/calloc/realloc调用,都必须在同一个指针上、同一个堆内存空间中,对应且仅对应一次free调用。释放未分配的内存、重复释放内存,或者混用自定义内存分配器,都会引发确定性的程序崩溃(见图 9)。

图 9 内存管理错误示例:内存分配与释放函数不匹配,如new配delete[]、malloc配delete
修复方案:明确内存所有权;在分配内存的同一模块中释放内存,或用醒目的注释说明内存释放规则。养成一个好习惯:写完malloc()语句按下回车后,立刻写下对应的free()语句,之后再决定free()语句应该放在代码的哪个位置。
10. 用==比较 C 语言字符串,疑惑为何 “admin” 不等于 “admin”
在 C 语言中,“字符串” 变量本质上是指针。用==比较的是指针的地址,而非字符串的内容。两个内容完全相同但存储在不同缓冲区的字符串,用==比较时永远不会相等,这会让人抓狂不已(见图 10)。

图 10 字符串比较错误示例:用==比较 C 语言字符串,疑惑为何 “admin” 不等于 “admin”
正确做法:使用strcmp函数进行完整字符串比较,使用strncmp函数进行指定长度的比较,并明确区分比较是否区分大小写(可使用strcasecmp/strncasecmp函数,具体视平台支持情况而定)。经验法则:指针只负责指向内存地址,无法证明其所指内容是否相等。
总结
仔细计算字节数,明确内存生命周期,匹配好内存分配与释放函数,定义清晰的程序不变式,尽早借助工具发现问题。开启编译器的所有警告选项,在调试版本中使用 AddressSanitizer 和 Undefined Behavior Sanitizer ,在逻辑关键节点添加断言,全程使用size_t类型表示尺寸。优先采用能够直接体现正确性的编程模式 —— 传递缓冲区时同时带上长度值,将指针和长度封装到小型结构体中,集中管理内存所有权 —— 这样编译器和代码评审人员就能帮你规避很多问题。
确定性的漏洞其实是宝贵的经验财富,只要你善于总结,就能快速成长。从现在开始养成这些好习惯,你的代码将不再 “处处是惊喜”,代码评审的效率会更高,版本发布也会从碰运气般的冒险,变成精准可控的流程。





评论