3D器件堆栈的新型组装方法

半导体封装的下一个重大飞跃将需要一系列新技术、工艺和材料,但总的来说,它们将使性能得到数量级的提高,这对于 AI 时代至关重要。
并非所有这些问题都得到完全解决,但最近的电子元件技术会议 (ECTC) 让我们得以一窥自 ChatGPT 的推出震惊科技界以来,过去几年所取得的巨大飞跃。AMD、TSMC、Samsung、Intel 和许多设备供应商详细介绍了混合键合、玻璃芯基板、微通道或直接冷却冷却以及通过背面电源方案散热方面的改进。
“AI 改变超级计算机/高性能计算空间的方式令人惊叹,”AMD 高级副总裁兼企业研究员 Sam Naffziger 在关于 AI 计算的演讲中表示。“ChatGPT 和 Geminis 已经摄取了整个互联网数据世界并训练了模型,但高质量的文本数据已经被完全消耗掉了。AI 变得越来越智能的方式是通过称为后训练和测试时计算或思维链推理的方法,这是模型相互检查、生成合成数据并迭代响应并产生更深思熟虑的结果的地方。尽管智能的每一次增长都非常有价值,但需要多两到三个数量级的计算才能获得智能的线性回报。因此,对计算的需求将继续增长,而这样做是为了降低成本,而这正是我们行业非常擅长的。我们改进我们的制造流程。我们的产量越来越高,产量提高,成本下降。随着这一趋势的持续,芯片制造的创新,尤其是封装的创新将发挥核心作用。
ECTC 详细介绍的主要进展包括:
Intel 的混合键合低至 1μm 间距;
台积电对 CoWoS 的直接冷却,包括 4 个 SoC 和 6 个 HBM;
ITRI/Brewer Science 的 10 层 RDL,采用聚合物/铜混合键合;
佐治亚理工学院的小芯片作为冷却剂,通过 TSV/硅柱进行液体冷却;
Corning/Fraunhofer IZM 用于光收发器的玻璃波导;
三星用于移动处理器和 DRAM 的铜基加热块,以及
Imec 的热通量与热点的 3D 多芯片仿真。
热切屑
的液体冷却随着强制空气冷却达到极限,切屑层的液体冷却开始形成。“我们正在设法使用高速风扇冷却高达 1,000 瓦的设备,而风扇功率消耗了大约 20% 的服务器机架预算,而我2R 损失占 10% 到 20%,“Naffziger 说。“所以现在我们有 40% 的电力仅用于输送电流和提取热量。这显然不是构建高效计算系统的方法。这就是推动直接液体冷却无情发展的原因,这种冷却在泵和冷凝器中有一些电力开销,但比具有巨大散热器的高速风扇要小得多。
在会议上,台积电的 Yu-Jen Lien 介绍了一种称为硅集成微型冷却器 (IMEC-Si) 的液体冷却架构,该架构正在使用有机中介层 (CoWoS-R) 上的 1.6X 标线大小的测试车辆进行可靠性测试。该散热器旨在模拟 4-SoC、8-HBM 封装,使用 40°C 水流速 10 升/分钟,可以耗散超过 3,000 瓦的均匀功率。这种液体冷却方法可提供卓越的冷却效果(高达 2.5 W/mm)2功率密度)相对于具有热界面材料方案的间接液体冷板。

图 1:使用 10 L/min 水(下图)的直接液体冷却 CoWoS 比使用 TIM、盖子和冷板配置的 CoWoS 散发更多的热量。来源:IEEE ECTC [1]
TSMC 的组装流程应用了一个保护层来覆盖 SoC 背面的铜柱阵列。将组件翻转到载体晶片上,然后进行 C4 碰撞。翻转和保护层去除后,传统的 CoWoS 流程之后,在 SoC 周边分配弹性体密封剂。密封剂可最大限度地减少翘曲并密封芯片到盖子的区域。“回流焊后,将具有单个入口和出口的歧管组装到集成系统上,该歧管旨在在多个冷却室之间实现均匀的流量分布。”[1]
台积电配备 4 个 SoC 和 6 个 HBM 芯片的 3.3X 掩线测试车经历了 160-190μm 的翘曲范围,这会导致盖子和 SoC 芯片之间的流速和轮廓发生变化。该封装通过了氦气泄漏测试和早期可靠性测试。
对直接切屑冷却的需求非常迫切,以至于佐治亚理工学院提出了一个新颖的概念,即小芯片作为冷却剂。“想象一下,我们设计的小芯片成为现成开源社区的一部分,这些小芯片设计具有不同的冷却能力,比如说具有不同的直径、间距,但也具有不同的 TSV 设计,”佐治亚理工学院 3D 包集成中心主任 Muhannad Bakir 说。“我们可以在该结构中构建独特的 TSV 结构、独特的冷却结构以及独特的其他功能,以帮助热能和电力输送。因此,它实际上只是成为堆栈中的混合粘合解决方案。Bakir 的小组展示了由硅制成的微型翅片引脚散热器,具有 5nm TSV(见图 2),可以冷却 >300W/cm2。[2]

图 2:微流体冷却包括硅散热器和用于芯片-芯片连接的硅通孔。来源:IEEE ECTC [2]
另一种冷却方法在 Samsung 用于移动应用的新型架构中的应用处理器顶部放置了一个加热块(见图 3)。[3] Kyung Don Mun 及其同事探索了一种非对称内存和处理器结构,该结构为处理器、内存和基于铜的热路径模块的放置提供了设计灵活性。
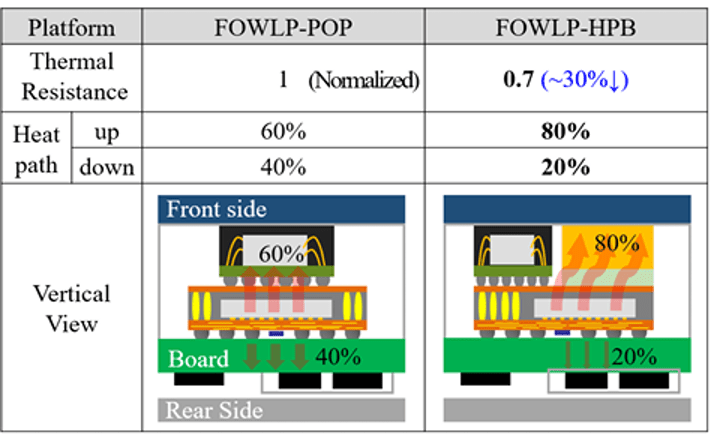
图 3:从逻辑结构上的对称存储器(左)切换到处理器上带有铜热路径块的非对称结构(右),改善了具有背面供电网络的 2nm 栅极全环绕逻辑器件的散热效果。来源:IEEE ECTC [3]
具有背面供电网络的应用处理器的 2nm 栅极全环绕晶体管结构需要将模块的散热提高 20%。三星使用 Ansys 的有限元模型来识别高风险区域并仿真翘曲。“RDL 图形设计优化对于这种异构封装设计尤为重要,因为薄 RDL 容易受到热机械应力集中和裂纹失效的影响,”Mun 说。选择具有更宽图形宽度和更长图形长度的再分布层减少了翘曲。成型材料、双面 RDL 和热界面材料得到了进一步改进,以实现更高的导热性和散热性。
混合键合
细间距多层有机再分布层 (RDL) 作为硅中介层和层压衬底的可行替代品越来越受欢迎。这种转变是由 RDL 以低成本提供高速互连的能力推动的。工业技术研究所 (ITRI) 和 Brewer Science 展示了聚合物/铜 RDL 的五层堆叠,然后是铜-铜混合键合,针对高速数字应用中的高 I/O、低回波损耗和低插入损耗。[4]
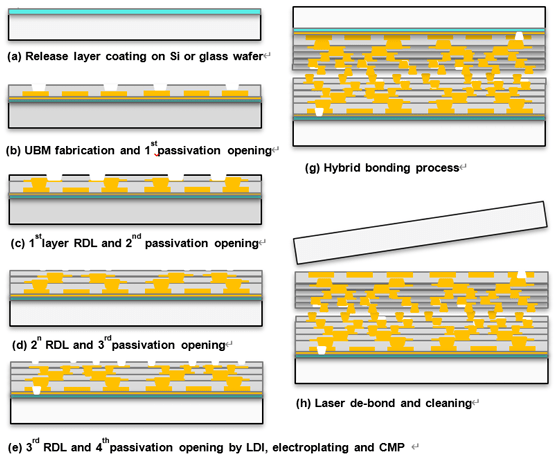
图 4:聚合物/铜堆积的再分布层之后是具有受控翘曲的 Cu-Cu 混合键合。来源:IEEE ECTC [4]
在玻璃载体晶圆上构建线/空间 RDL (4 至 10μm L/S)后,使用负色调光刻胶和 i-line 曝光对低 k 聚合物 (2.5) 进行图案化,然后进行蚀刻、用钛阻挡层和铜填充焊盘,然后用铜 CMP 平坦化。混合键合使用 300°C (1.06 MPa) 的热压键合,然后通过 UV 激光进行载体晶圆解键合。低模量、高热稳定性和低吸湿性等聚合物特性旨在实现多层 RDL 堆栈的低翘曲。
近年来,使用传统电介质(SiO2基/铜)的混合键合的间距缩放已经从10μm(制造中)扩展到1μm(研发中)。Intel 高级首席工程师 Adel Elsherbini 和他的同事讨论了实现此类扩展所需的一些功能。[5]
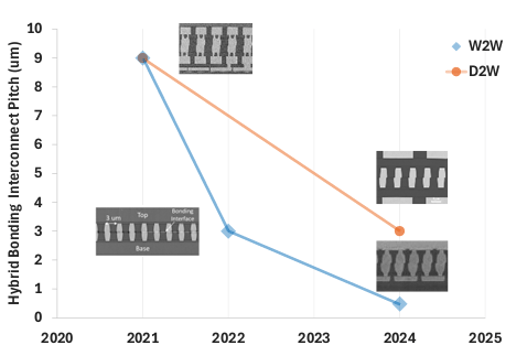
图 5:Intel 使用混合键合的研究结果。来源:IEEE ECTC [5]
他们的论文指出,系统架构通常决定是选择晶圆到晶圆 (W2W) 还是晶片到晶圆 (D2W) 键合。晶圆到晶圆键合的主要限制是它需要相同大小的小芯片键合。该技术更成熟,可实现更精细的间距。晶片到晶片键合没有尺寸限制,只使用已知良好的晶片。“对于 C2W 应用,随着 HB 间距继续扩展到 1μm 及以上,贴装精度要求突破了当前一代芯片键合机的极限。为了确保电气连续性,整个小芯片区域需要达到相同的精度水平,低至几十纳米。类似于 W2W 键合的跳动和变形控制,芯片内精度控制变得越来越重要,“作者说。
“传统的贴装精度标准,如小芯片中心或最差角错位,已经不够用了。D2W 工艺控制在键合过程中变得越来越复杂,以更多地关注每个小芯片级别的翘曲控制、芯片成型和键合波传播控制。另一方面,为了量化晶粒内部键合精度,需要新的对准标记策略和更好的键合后精度测量计量,以了解从芯片制备一直到键合的小芯片级变形行为。作者指出,红外剥离可以重复使用硅载体晶圆,从而降低拥有成本。
使用背面电源
去除热量背面供电是一种新颖的互连方案,它在晶圆背面构建供电网络,以显著降低与向晶体管供电相关的电压下降。顶部的互连器仅可自由传输信号,从而提供许多电气优势。
然而,相对于标准互连堆栈,这种新方法加剧了热点问题(见图 6)。“如果你从正面的相对视图来看,晶体管中产生的所有热量都会直接进入硅片,到达散热器或冷板,”IBM 研究院高级技术人员 Dureseti Chidambarrao 说。“但还有一个额外的不幸情况,你喜欢背面的电源——因为你把电源和信号分开了,所以这是一种不那么复杂的制造方式——但我们现在面临着这个挑战,试图从这种堆栈中去除热量,因为热尖峰和热电路被困住了。”

图 6:背面电源会感应出新的热流模式,因为有源器件夹在金属堆栈之间。来源:Laura Peters/半导体工程
IBM 开发了一个各向异性模型,可以准确计算通过后端堆栈的热传递,同时考虑材料属性。该 AI 模型将设计与互连堆栈中的本地功率密度、工作负载和材料属性联系起来。“你拿 GDS 文件,它实际上会一起计算多个级别和多个层的平均属性,这样你就可以在每个给定位置获得正确的 [传热] 平均属性。现在你有办法计算每个瓷砖,而且你可以越来越细化它,“Chidambarrao 说。
在设计阶段考虑此类热因素的重要性怎么强调都不为过。“封装和芯片正在相互作用,并且已经变得非常紧密耦合,因此这是一个完整的系统技术优化问题,你必须担心设计中的热问题,”他说。“这尤其必须发生在背面电源上,我什至没有想象到最糟糕的事情——在 3D 芯片上放置背面电源。如果这是你想做的,那么解决方案显然要严格得多。
背面供电已经被设计到芯片中。“我们预计明年将首次在产品中实现背面电源,”imec 的主要技术人员兼热建模和特性研发团队负责人 Herman Oprins 说。“虽然背面电源最初是无源结构,但进一步这也将用于包括信号时钟和其他功能。方法有很多种,但最重要的是你需要通过 nanoTSV 连接正面和背面。
NanoTSV 要求将硅减薄到至少 300nm,可能小于 100nm。此外,还需要进行详细的建模来了解此类设备的冷却需求。
Oprins 说:“如果你有一个局部热点和超薄硅,你的温度实际上会升高,因为你有更少的电量(硅)来分散它。另一方面,背面有金属堆栈,因此这种密集的金属阵列可能有助于设备的热量扩散。
Imec 之前表明,实施背面电源会造成 10% 到 30% 的热损失 (ECTC 2024)。今年,Oprins 的小组使用 BSPDN 模拟了堆叠逻辑对内存或内存对逻辑的热效应。这些仿真包括芯片的面对面混合键合和背对面键合,结合使用玻尔兹曼传输方程和蒙特卡洛仿真。仿真说明了均匀芯片加热与热点影响之间的温升差异(见图 7)。
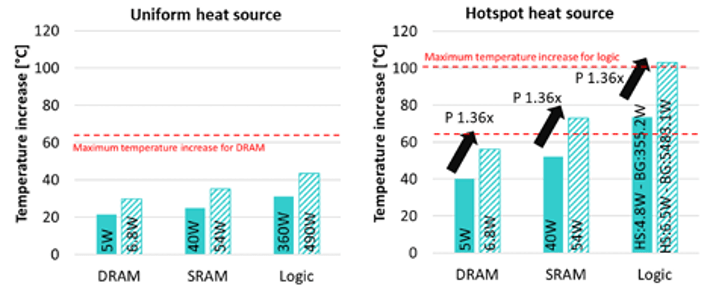
图 7:具有均匀器件加热(左)的器件温度升高与有额外热点的器件。来源:IEEE ECTC [7]
“堆栈中逻辑和内存芯片的顺序对热性能的影响更大,”Oprins 说。“由于靠近冷却,Logic-on-top 导致逻辑温度较低,但由于堆栈中的高热耦合,内存温度较高。”多层 memory-on-logic 表明,BSPDN 的热影响减少了多个芯片堆叠。在这种情况下, logic on top configuration 受 memory die temperature 的热限制,而对于 memory-on-top configuration,logic temperature 是限制因素。该论文总结道:“更高效的冷却表明,3D SoC BSPDN 的热性能得到了显著改善,从而实现了具有校准功耗的内存逻辑配置。[7]
Oprins 强调了液体冷却的重要性。Oprins 说:“看看 3D 架构,如果你每个芯片堆叠 5 个芯片,比如说耗散 100 瓦并使用传统的空气冷却,那么你最终得到的最大结温远大于 500°C。如果集成冷板,则最高结温约为 250°C。 然而,如果你能以某种方式在电堆内开发层间冷却,那么突然之间就有机会真正将温度降低到 50°C 左右,“imec 的 3D 电堆模拟说。
共封装光学器件
行业对更快数据网络和设备接口速度的需求正在急剧增加。数据中心机架内部的一个关键推动因素是将光学引擎与 GPU 和 HBM 集成到同一个封装中。“借助共封装光学器件 (CPO),我们有机会将电气互连与光学连接集成到一个封装中,”ASE 研究员 CP Hung 说。“这是该行业的新里程碑。通过将光学引擎移到更靠近处理器的位置,我们将每根光纤的 200 Gb/s 提高到 6.4Tb/s,带宽增加了 32 倍。
尽管 CPO 做出了承诺,但未知数仍然存在。“CPO 肯定会发生,而且这种势头肯定会推动它尽早发生,”ASE 工程、营销和技术推广高级总监 Mark Gerber 说。“使用 CPO 时,热侧和翘曲侧都存在敏感性。重要的是,该行业希望保持当今存在的光学引擎的可插拔(即可替换)方面。但是,虽然 plug-able 很容易切换,但它们并不容易掌握。
在 ECTC 上,ASE 展示了其用于 ASIC 交换机和以太网/HBM 共封装光学平台的模块化平台。
热仿真在选择先进封装散热堆栈的架构、工艺和材料方面也发挥着关键作用。“从历史上看,在单片芯片集成中,封装设计和散热器的热仿真是按照通过/不通过的方式进行的,”Amkor Technology 的热仿真工程师 Tom Nordstog 说。借助多小芯片封装,仿真在封装设计的早期阶段发挥着更明显的作用。“热仿真是一项风险/回报练习,旨在选择最终设计。理想情况下,封装的热设计发生在芯片设计之前。我们看到最积极的客户在这些早期阶段就采用热仿真。
康宁和Fraunhofer IZM提出了一种可扩展的“平面2D波导电路',可以通过减少对光纤电缆终端和手动组装的需求,为未来几代CPO解决方案减少所需的空间、复杂性和成本。[8]该团队使用 460 x 303 毫米熔融成型玻璃面板制造了具有波导布局的单模板级互连,旨在满足将 1024 个光链路从面板连接到 CPO 模块的光互连要求,用于 102.4 Tb/s 数据中心交换机应用。Fraunhofer IZM 工程师设计了工艺流程(见图 8),其中包括将单模波导集成到玻璃中的热离子交换工艺,与 1310nm 波长的单模光纤的光模式相匹配。移除掩模后,执行第二个反向离子交换过程步骤,将波导的核心埋在玻璃表面以下,以减少传播损耗。
Brusberg 说:“为了与玻璃波导面板的光纤连接,组装了 MPO-16 适配器,并将玻璃波导电路集成到 1U 机架机箱中,以展示仅 0.7 mm 的扁平外形。这种新颖的方法可以为基于 PCB 的光收发器铺平道路。

图 8:工艺流程包括金属沉积、光刻胶涂层、波导成像和离子交换,以将银扩散到图案中。来源:IEEE ECTC [8]
引用
Y-J Lien,“集成在 CoWoS 平台上的直接到硅液体冷却”,IEEE 电子元件和技术会议,2025 年 5 月,正在出版。
Yan 等人,“面向 3D IC 的 TSV 兼容微流体冷却”,IEEE Transactions on Components, Packaging and Manufacturing Technology,第 15 卷,第 1 期,第 104-1,12 页,2025 年 1 月,doi:10.1109/TCPMT.2024.3516653。
D. Mun 等人,“一种增强散热的移动应用中设备端 AI 的新型架构”,IEEE 电子元件和技术会议,2025 年 5 月,正在出版。
-H. Lee 等人,“通过可转移铜/聚合物混合键合实现具有新颖结构的分层多层和堆叠通孔,用于高速数字应用”,IEEE 电子元件和技术会议,2025 年 5 月,正在印刷中
Chang 等人,“先进 BEOL 堆栈等效热特性的热建模和分析”,IEEE Transactions on Components, Packaging and Manufacturing Technology,doi:10.1109/TCPMT.2025.3564833。
Elsherbini等人,“通过低于1um间距的混合键合和先进的硅载体技术实现的Mid-BEOL异构集成,用于AI和计算应用”,IEEE电子元件和技术会议,2025年5月,正在出版。
R. Chowdhury,“Backside Power Delivery and Chiplet Architectures中后端线热阻的快速准确机器学习预测”,IEEE 电子元件和技术会议,2025 年 5 月,正在出版。
Brusberg,“用于面板和共封装光收发器之间板级光互连的大规模玻璃波导电路”,IEEE 电子元件和技术会议,2025 年 5 月,正在出版。

评论