ARM Thumb Thumb-2指令集

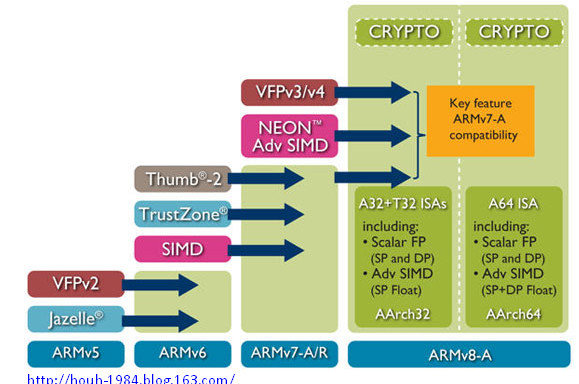
图1. ARM体系结构演进图
ARM指令集(A32)
ARM指令集为32位指令集,指令地址必须对齐在4字节边界,可以实现ARM架构下所有功能。大多数ARM数据处理指令采用的是3地址格式(除了64位乘法指令外),即两个源操作数和一个结果操作数。
ARM指令分为以下几种: 一、ARM 存储器访问指令 二、ARM 数据处理指令 三、乘法指令 四、跳转指令 五、ARM协处理器指令 五、ARM 杂项指令 | |||||||||||
所有异常都会使微处理器返回到ARM模式状态,并在ARM的编程模式中处理。由于ARM微处理器字传送地址必须可被4整除(即字对准),半字传送地址必须可被2整除(即半字对准)。而Thumb指令是2个字节长,而不是4个字节,所以,由Thumb执行状态进入异常时其自然偏移与ARM不同。
Thumb指令集
对于ARM指令来说,所有的指令长度都是32位,并且执行周期大多为单周期,指令都是有条件执行的。每条Thumb指令有相同处理器模型所对应的32位ARM指令。而THUMB 指令的特点如下:
- 不会经常条件执行使用指令:除了跳转指令 B 有条件执行功能外,其它指令均为无条件执行
- 源寄存器与目标寄存器经常是相同的以减少操作数
- 可用寄存器数量少
- 常数的值比较小
- 不经常用内核中的桶式移位器(barrel shifter)
Thumb指令集是对32位ARM指令集的扩充,它的目标是为了实现更高的代码密度。Thumb指令集实现的功能只是32位ARM指令集的子集,它仅仅把常用的ARM指令压缩成16位的指令编码方式。在指令的执行阶段,16位的指令被重新解码,完成对等的32位指令所实现的功能。与全部用ARM指令集的方式相比,使用Thumb指令可以在代码密度方面改善大约30%。但是,这种改进是以代码的效率为代价的。尽管每个Thumb指令都有相对应的ARM指令,但是,相同的功能需要更多的Thumb指令才能完成。因此,当指令预取需要的时间没有区别时,ARM指令相对Thumb指令具有更好的性能。与ARM指令集相比较,Thumb指令集中的数据处理指令的操作数仍然是32位,指令地址也为32位,但Thumb指令集为实现16位的指令长度,舍弃了ARM指令集的一些特性,若使用32位的存储器,ARM代码比Thumb代码快约40%,若使用16位的存储器,Thumb代码比ARM代码快约40%~50%.显然,ARM指令集和Thumb指令集各有其优点,若对系统的性能有较高要求,应使用32位的存储系统和ARM指令集,若对系统的成本及功耗有较高要求,则应使用16位的存储系统和Thumb指令集。当然,若两者结合使用,充分发挥其各自的优点,会取得更好的效果。 在编写Thumb指令时,先要使用伪指令CODE16声明,编写ARM指令时,则可使用CODE32伪指令声明。Thumb 指令集没有协处理器指令,信号量指令以及访问 CPSR 或 SPSR 的指令,没有乘加指令及 64 位乘法指令等,且指令的第二操作数受到限制;大多数 Thumb 数据处理指令采用2地址格式.Thumb指令集与 ARM 指令的区别一般有如下几点: | |
Thumb-2指令集(T32)
THUMB-2指令集是介绍ARM CPU中的THUMB的扩展,新指令对性能和代码密度的改进,从而提供低功耗,高性能的最优设计,更好的平衡代码性能和系统成本,Thumb-2是混合的16-bit和32-bit指令格式,其16位指令在运行时被转换为32-bit指令执行。Thumb-2指令集在Thumb指令的基础上做了如下的扩充:增加了一些新的16位Thumb指令来改进程序的执行流程,增加了一些新的32位Thumb指令以实现一些ARM指令的专有功能32位的ARM 指令也得到了扩充,增加了一些新的指令来改善代码性能和数据处理的效率给Thumb指令集增加32位指令就解决了之前Thumb指令集不能访问协处理器、特权指令和特殊功能指令的局限。新的Thumb指令集现在可以实现所有的功能,这样就不需要在ARM/Thumb状态之间反复切换了,代码密度和性能得到显著的提高。Thumb-2的出现使开发者只使用一套指令集就享有高性能、高代码密度,不再需要在不同指令之间反复切换了。开发者只需要关注对整体性能影响最大的那部分代码,其他的部分可以使用缺省的编译配置就可以了。
新的Thumb-2技术可以带来很多好处:
可以实现ARM指令的所有功能
增加了12条新指令,可以改进代码性能和代码密度之间的平衡
代码性能达到了纯ARM代码性能的98%
相对ARM代码,Thumb-2代码的大小仅有其74%
代码密度比现有的Thumb指令集更高:代码大小平均降低5%;代码速度平均提高2-3%
为了提高处理压缩数据结构的效率,新的ARM架构为Thumb-2指令集和ARM指令集增加了一些新的指令来实现比特位的插入和抽取。为了增加处理常数的灵活性,新架构中为Thumb-2指令集和ARM指令集增加了两条新的指令。MOVW可以把一个16-bit常数加载到寄存器中,并用0填充高比特位;另一条指令MOVT可以把一个16-bit常数加载到寄存器高16比特中。这两条指令组合使用就可以把一个32-bit常数加载到寄存器中。通常在访问外设寄存器之前会把外设的基址加载到寄存器中,这时就会需要把32-bit常数加载到寄存器中。在之前的架构中需要通过literal pools来完成这样的操作,对32位常量的访问一般通过PC相对寻址来实现。Literal pools可以保存常量并简化访问这些常量的代码,但是,在Harvard架构的处理器中会引起额外的开销。这些开销来自于需要额外的时钟周期来使数据端 口能够对指令流进行访问;这种访问可能是需要把指令流加载的数据缓存中,或者从数据端口直接访问指令存储器。将32位常量分成16比特的两个部分保存在两条指令中,意味着数据直接在指令流中,不再需要通过数据端口来访问了。相对于literal pool方式,这种解决办法可以消除通过数据端口访问指令流的额外开销,进而提高性能,降低功耗。
ARM/Thumb状态切换
在基于ARM 处理器的嵌入式开发中,为了增强系统的灵活性以及提高系统的整体性能经常需要使用16 位的Thumb 指令,所以需要在ARM 和Thumb 状态之间来切换(Interworking)微处理器状态。只要遵循ATPCS调用规则,Thumb子程序和ARM子程序就可以互相调用。首先介绍切换(Interwoking)的基本概念及切换时的子函数调用。
ARM处理器总是从ARM状态开始执行。因而,如果要在调试器中运行Thumb程序,必须为该Thumb程序添加一个ARM程序头,然后再切换到Thumb状态,调用该Thumb程序。
- Thumb状态 BX Rn
- ARM状态 BX
Rn
其中Rn可以是寄存器R0—R15中的任意一个。指令可以通过将寄存器Rn的内容拷贝到程序计数器PC来完成在4Gbyte地址空间中的绝对跳转,而状态切换是由寄存器Rn的最低位来指定的,如果操作数寄存器的状态位Bit0=0,则进入ARM状态,如果Bit0=1,则进入Thumb状态。在非Interworking函数调用中,调用函数使用BL(Branch with Link)指令,即将返回地址保存在连接寄存器LR中,同时跳转到被调用的子函数程序入口。从子函数返回时执行指令 MOV PC, LR(当然也可能是其他形式的指令,如出栈指令)将LR值直接放入PC中,从而返回到调用函数中的下一条指令的地址,然后继续执行程序。在Interworking函数的调用中,需要在编译时对此函数所在的源程序指定编译开关选项:-apcs / interwork ,即保证程序遵守ARM/Thumb程序混合使用的ATPCS规则。一般来说,这时生成的目标代码会增加2%左右。这样在编译器(compiler)处理这个函数时就会用BX 指令取代MOV PC,LR指令,而且连接器(linker)会自动的产生一小段代码(veneers)来改变处理器状态(ARM/Thumb),对于C/C++程序来说,当编译时如果增加 –apcs/interwork 选项,那就是告诉连接器自动增加一小段代码(veneer)来实现函数调用时ARM/Thumb的状态切换。但是对于使用C程序中的Interwork选项,需要注意的是:
- 对于一个C /C++源程序中不能同时包含ARM/Thumb指令;
- 如果C/C++程序间接的调用另一种指令系统下的子程序,编译该程序时需要增加-apcs/interwork选项;
- 编译用于交互工作的ARM C代码: armcc -apcs/interwork
- 编译用于交互工作的Thumb C代码:tcc -apcs/interwork
- 如果调用程序和被调用程序是不同的指令,而被调用程序是Non-Interworking代码,这时不要使用函数指针来调用该被调用程序。
对于汇编程序来说,如果本代码是被调用的函数,则需按照以下步骤处理:
- 编译时增加-apcs/interwork 选项;ARM汇编armasm -32 -apcs /interwork;Thumb汇编代码:armasm -16 -apcs /interwork;
- 在入口处保护返回地址(lr)以及寄存器(r0-r7,r8-r12(ARM))
- 返回前恢复保护的寄存器
- 用BX来返回;
- EXPORT本函数名;
如果本代码是调用函数,那就只需要用BL指令来实现子函数的调用即可,也就是正常的处理。当然,用户也可以自己来编写这些状态切换程序,这样执行代码的效率会更高些。对于C/C++程序和汇编程序的相互调用同样需要遵守以上的规则。另外,在实际应用中,如果要在ARM/Thumb状态间来切换程序,最好的办法是所有的函数在编译时都增加 -apcs/interwork选项。关于汇编代码,也可在程序中使用CODE32或CODE16命令明确告知汇编程序下面的代码是ARM代码还是Thumb代码,这样在汇编时则无需使用-32、-16选项;当然也可在单个汇编原文件中混合使用ARM以及Thumb代码,这是需要使用CODE32以及CODE16命令,并且需要注意状态的切换,使用BX Rn,根据Rn的Bit[0]来确定目标是ARM代码还是Thumb代码。如AREA Init,CODE,READONLY CODE32;通知编译器其后的指令为32位的ARM指令。
前面所提到的内容是针对ARM微处理器内核为V4T架构时的切换情况,而对于V5TE架构的ARM内核,除了完全支持V4T架构的代码(具有veneers)外,代码在连接时不再增加veneers,而是使用新的指令BLX(Branch and Link with Exchang)来实现状态切换。这条指令完成完成的任务是:在跳转时将返回的指令地址保存在LR寄存器中,同时将PC中的最低位的值拷贝到CPSR寄存器中的T位,从而改变处理器状态(Exchange)。一般来说,对于调用函数使用BLX指令即可,被调用函数则与V4T架构相同,也是使用BX指令来返回。
ARM/Thumb代码性能比较
前面提到Thumb代码所需的存储空间约为ARM代码的60%~70%;Thumb代码使用的指令数比ARM代码少约30%~40%;若使用32位的存储器,ARM代码比Thumb代码速约40%;若使用16位的存储器,Thumb代码比ARM代码速约40%~50%;与ARM代码相比,使用Thumb代码,存储器的过耗会下降约30%。下面是arm-linux-gcc编译器采用不同的编译选择对armv7-a,、thumb-2 和thumb-1指令集编译CoreMark的测试结果,结果如下:
- 最好的编译选项:-O3 -funroll-loops -marm -march=armv5te -mtune=cortex-a8
- armv7-a指令集最好的编译选项:-O3 -funroll-loops -marm -march=armv7-a -mtune=cortex-a8 95.2%
- Thumb-2指令集最好的编译选项:-O3 -funroll-loops -mthumb -march=armv7-a -mtune=cortex-a888.7%
- Thumb-1指令集最好的编译选项:-O2 -mthumb -march=armv5te -mtune=cortex-a8 66.4%
- Cortex-A9是Cortex-A8的tune的99.5%
- 默认选项-O2 -mthumb -march=armv7-a 性能比为80.8%
Top of Form
Score | Optimisation | Unroll? | ISA | Arch | Tune | % of best |
5634.6 | -O3 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a8 | 100.0% |
5607.7 | -O3 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a9 | 99.5% |
5601.5 | -O2 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a9 | 99.4% |
5580.0 | -O3 | -marm | -march=armv5te | -mtune=cortex-a8 | 99.0% | |
5548.6 | -O3 | -marm | -march=armv5te | -mtune=cortex-a9 | 98.5% | |
5505.1 | -O2 | -marm | -march=armv5te | -mtune=cortex-a8 | 97.7% | |
5427.4 | -O2 | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a8 | 96.3% |
5386.5 | -O3 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a9 | 95.6% |
5364.4 | -O3 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a8 | 95.2% |
5332.3 | -O2 | -marm | -march=armv5te | -mtune=cortex-a9 | 94.6% | |
5330.8 | -O3 | -marm | -march=armv7-a | -mtune=cortex-a8 | 94.6% | |
5283.7 | -O3 | -marm | -march=armv7-a | -mtune=cortex-a9 | 93.8% | |
5253.5 | -O2 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a9 | 93.2% |
5066.5 | -O2 | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a8 | 89.9% |
4996.6 | -O3 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 88.7% |
4995.6 | -O3 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 88.7% |
4947.2 | -O3 | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 87.8% | |
4858.3 | -O2 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 86.2% |
4774.8 | -O2 | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 84.7% |
4763.8 | -O2 | -marm | -march=armv7-a | -mtune=cortex-a9 | 84.5% | |
4737.8 | -Os | -marm | -march=armv5te | -mtune=cortex-a8 | 84.1% | |
4731.1 | -O2 | -marm | -march=armv7-a | -mtune=cortex-a8 | 84.0% | |
4688.6 | -O3 | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 83.2% | |
4665.6 | -Os | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a8 | 82.8% |
4630.7 | -Os | -marm | -march=armv5te | -mtune=cortex-a9 | 82.2% | |
4595.6 | -Os | -funroll-loops | -marm | -march=armv5te | -mtune=cortex-a9 | 81.6% |
4562.7 | -Os | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a8 | 81.0% |
4551.7 | -O2 | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 80.8% | |
4521.5 | -Os | -funroll-loops | -marm | -march=armv7-a | -mtune=cortex-a9 | 80.2% |
4519.8 | -Os | -marm | -march=armv7-a | -mtune=cortex-a8 | 80.2% | |
4500.8 | -Os | -marm | -march=armv7-a | -mtune=cortex-a9 | 79.9% | |
4237.6 | -O2 | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 75.2% | |
3739.7 | -O2 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a8 | 66.4% |
3730.6 | -O2 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a9 | 66.2% |
3658.8 | -Os | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 64.9% | |
3657.0 | -Os | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a8 | 64.9% |
3629.3 | -O2 | -mthumb | -march=armv5te | -mtune=cortex-a8 | 64.4% | |
3585.1 | -Os | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 63.6% | |
3580.8 | -Os | -funroll-loops | -mthumb | -march=armv7-a | -mtune=cortex-a9 | 63.6% |
3522.2 | -O3 | -mthumb | -march=armv5te | -mtune=cortex-a8 | 62.5% | |
3473.0 | -O2 | -mthumb | -march=armv5te | -mtune=cortex-a9 | 61.6% | |
3338.9 | -O3 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a8 | 59.3% |
3219.1 | -O3 | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a9 | 57.1% |
3170.6 | -O3 | -mthumb | -march=armv5te | -mtune=cortex-a9 | 56.3% | |
2753.7 | -Os | -mthumb | -march=armv5te | -mtune=cortex-a8 | 48.9% | |
2748.6 | -Os | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a8 | 48.8% |
2747.4 | -Os | -mthumb | -march=armv5te | -mtune=cortex-a9 | 48.8% | |
2743.7 | -Os | -funroll-loops | -mthumb | -march=armv5te | -mtune=cortex-a9 | 48.7% |
Bottom of Form
http://lion3875.blog.51cto.com/2911026/532719
http://www.cnx-software.com/2011/04/22/compile-with-arm-thumb2-reduce-memory-footprint-and-improve-performance/#ixzz1qTCwHRc4
https://wiki.linaro.org/MichaelHope/Sandbox/CoreMark1
http://blog.csdn.net/itismine/archive/2009/11/01/4753701.aspx
http://hi.baidu.com/yzx408/blog/item/a050741180944c1cb8127b79.html
http://houh-1984.blog.163.com/
32位RISC芯片ARM 体系结构支持两种指令集:32位的ARM指令集执行效率高,对ARM体系架构所有功能的完整支持;16位的Thumb指令集是ARM指令集的子集并以良好的代码密度著称。如果抛开预取指令时间不计,ARM指令相对Thumb指令将有更好的运行性能(预取指令时需要根据指令地址偏移量来取指, ARM支持更大的地址偏移量而比较耗时)。最近ARM公司推出的的Thumb-2/Thumb2指令集据称是上述两种特性的综合,是ARM指令集的性能和Thumb指令集的代码密度的折中。号称达到98%的ARM性能而又能降低代码密度达30%。在目前的大多数ARM应用中依然采用ARM + Thumb代码的混杂模式。ARM code对应的CPU(ARM处理器)工作状态称为ARM State,Thumb对应的称之为Thumb State,这两种状态的不同主要通过CPSR[bit 5]区别。CPSR(当前程序状态寄存器)保存了处理器的当前工作状态,[bit 5]也被称为T bit。对于所有带有J标志的处理器核,比如ARM926EJ-S和ARM1136J-S,J(Jazelle)代表ARM核中集成了Jazelle技 术。CPSR[bit24]则被成为J bit,如果这位为1,则代表当前CPU工作在Java State下而CPU的取指和解码都是直接操作Java操作数栈。当然要生成Jazelle支持的字节码需要特殊的Java编译器和JVM,一般由第三方 平台软件厂商提供,比如日本的Aplix公司。在ARM处理器的运行过程中,汇编指令BX以及BLX可以完成ARM State和Thumb State之间的切换(BXJ和BLXJ完成ARM/Thumb State和Java State之间的切换)。但如果程序有一部分工作在ARM工作状态下,一部分工作在Thumb工作状态下,而这两段代码却有交互调用,则在编译C/C++和汇编源文件时要 加上 -apcs /interwork选项。ARM公司的ADS(ARM Developer Suite,-apcs /interwork)和RealView的RVDS(RealView Developer Suite,--apcs /interwork) 都支持这样的编译选项,他们会在链接时自动检测函数之间的调用关系和工作状态提供粘合剂(Veneers)以便程序能够在不同的工作状态下切换。arm-linux-gcc编译器个别版本不支持这个选项,所以在开发ARM + Linux平台下使用的程序时应该注意到这个问题。最后比较了arm-linux-gcc编译器下ARM(armv7-a)、Thumb-1、Thumb-2指令集以及armv5te、Cortex-A9与Cortex-A8的tune选项效率性能和代码密度。

评论