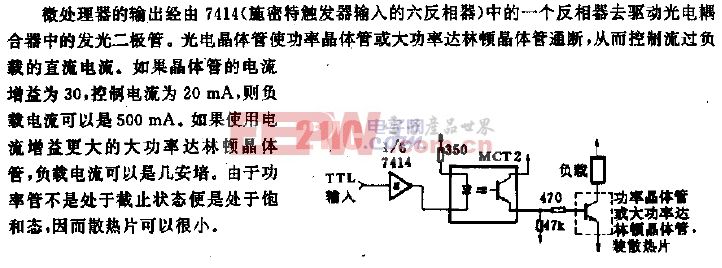
谷歌I/O四大更新:科技本质不是硬件和软件,而是知识与计算

科技的存在,应该为了我们更好地理解世界,并被世界所理解。
文|杜晨 编辑 | Lianzi 所有图片来源:谷歌
经过三年,谷歌开发者大会 I/O 终于今天回归线下。
位于谷歌山景城总部旁边的 Shoreline 露天剧院今天座无虚席。上千名公司员工、合作伙伴代表,以及幸运的第三方开发者,终于在他们最熟悉的地方得以齐聚一堂。
在欢快的电子舞曲之后,谷歌 CEO Sundar Pichai 走了出来:“哈咯,大家能听到我吗?”这引得台下一阵欢笑。
“过去两年里,每次我进会议都是静音的,所以我想也许我应该跟大家一起测试一下麦。”
Pichai 表示,今年的 I/O 大会会发布和预告一系列科技含量非常高的产品和功能,横跨谷歌的搜索、地图、Android 软件、Pixel 硬件产品,以及 AI 研究等多个部门。
然而这些产品和功能本身,并不是科技的本质。
几年前,谷歌重新设计了自己的公司使命:整合全球信息,使人人都能访问并从中受益。在 Pichai 看来,这个使命有两个最根本的组成部分:知识和计算。在 Pichai 的带领下,谷歌在过去几年内在技术和产品创新方面所做的努力,包括感知计算 (Ambient Computing)、多模态学习、融合搜索 (Multisearch)、超大规模语言模型、增强现实等——其实归根结底,都是在做两件事:
1)加深对于信息的理解,将其变为知识;
2)推进计算的范式创新,从而让任何人在世界任何角落,都可以更容易地访问和获取知识。
最直接的例子,就是谷歌在过去两年所扮演重要的信息枢纽角色:
在2021年,人们通过谷歌搜索和地图来查找疫苗接种信息超过20亿次;
在印度和孟加拉国,谷歌采用最新神经网络技术开发的季风预警系统,已经为超过2300万人提供了暴雨洪水预警,预计已挽救数十万灾民的生命。
信息只是信息,在民众之间流转的效率极低,并且很难保持准确度。但是因为有了先进的知识图谱技术,这些信息能够被系统识别、提取、精炼、汇总,最终以搜索结果、手机通知、灾害报告等形态,作为一种知识,得到了准确和高效的传播。
在今天的 I/O 大会,谷歌发布了一系列以推进知识和计算为核心的新产品、功能和技术。
| 让真实世界可以被"Ctrl-F"
今年4月,谷歌发布了一个全新的多模态搜索功能,让用户手机上通过拍照+文本的方式,进行更加定制化的搜索。比如很想买别人穿的一双鞋,但想要另一款颜色,就可以拍照,再加上“蓝色”的文字。这样,只需要进行一次搜索,就可以更容易地找到自己正在寻找的信息和产品。
但这还不够。对于谷歌来说,他们想要索引和组织的信息,早已不仅限于网上。比如,我们用谷歌地图来搜索真实世界中的地理位置相关信息。但如果想要更进一步,让用户可以更加精确地搜索真实世界,特别是他们附近的特定信息,能做到吗?
在今天 I/O 大会上,谷歌还真发布了一个这样的功能:Multisearch Near Me(周边多重搜索).
我们可能都遇到过这样的情况:在网上看到一道之前从未见过,但让你口水直流的菜,但是你压根都不知道它叫什么菜,属于什么菜系,附近有没有对应的餐馆。
这个功能就是专门来解决这个痛点的。你只需要拍照或者把照片上传,然后文字输入加上 “在我周围”:谷歌不仅能告诉你这道菜叫什么名字,还能够搜到附近有这道菜的店家。
这个搜索能力不仅限于食物,因为它的背后是谷歌搜索已经在采用的多模态机器学习引擎。一个模型可以同时理解并处理文字、图片、语音等多种不同模态的信息。原则上,任何物体它都能够搜索,包括并不限于食物、商品、服务(比如美甲)等。
这个功能将于今年内正式推出,初期仅支持英文,后续将会增加更多语言。与此同时,这个功能已经上线谷歌移动端 App,用户已经可以开始使用。
除此之外,今年谷歌在视觉搜索上面还有另一个大动作:对移动的取景框内,多个不同物体,进行同时和连续搜索,并且通过AR叠加的方式来展现这些物体相关的信息。
比如在超市,面对一整面货架的咖啡豆,不知道该买哪一款,你只需要掏出手机,打开 Google Lens(谷歌搜索和相机的视觉搜索功能),就可以看到这些不同品牌咖啡豆的评分了。
不仅如此,你还可以继续进行条件过滤,比如“高分”、“深烘焙”、“不含坚果等”:
这个功能叫做 Scene Exploration,目前仍在开发中,尚无具体发布的计划。除了 AR 之外,它也同样利用了刚才提到的多重搜索技术。
Pichai 表示:这就像给真实世界加入了 "Ctrl-F" 功能一样。
| 谷歌地图:观察真实的世界,现在有了全新角度
疫情两年以来,很多人恐怕已经忘记旅行是一种怎样的体验。这也是为什么很多人现在只能通过谷歌地图/地球,以及浏览各种网站照片和旅行视频来“过眼瘾”。
深知这一点,谷歌地图团队决定给用户们送上一份大福利。
先看下面这张图。如果不说清楚的话,你可能以为这是一张伦敦实景照片:
但其实,这是谷歌地图团队使用最先进的绘图和机器学习技术,开发出的全新的3D渲染地图功能 Immersive View:
对于一些知名的地标建筑,比如伦敦的大本钟和西敏寺大教堂,用户可以旋转3D地图查看不同角度,甚至还可以自选查看地标建筑物在不同时间和天气下多变的样貌:
谷歌地图 Immersive View (沉浸式视图)将在今年内推出,支持 Android 和 iOS,支持的城市和地标有限,首批包括洛杉矶、伦敦、纽约、旧金山和东京,之后将逐渐增加更多城市和知名建筑物。
| AI 帮你“长求总”
在谷歌,Pichai 会要求员工给他发送较长文档或电邮的时候,把内容总结成 TLDR (Too Long Didn't Read,也就是“长求总”),放在文档或电邮的最前面。这引发了团队的思考:如果更多东西也能被 TLDR,那该多好?
之前谷歌还就真的推出过这么一个功能:
在文档当中,机器学习模型会在后台运行,从文档和聊天记录当中提取文本,提炼出关键内容,然后自动生成一份总结:
以下面这份团队出游计划为例:AI 可以提取出组织者、成员、每一位成员的登记状态和提问,以及相关参考资料等重要信息,放在文档的开头,让文档的参与者可以一目了然。
而在这届 I/O 大会上,谷歌宣布把这个 TLDR 功能迁移到整个企业套件 Google Workspace 的更多功能里,比如 Space 和 Google Chat。
(Space 是谷歌企业服务的团队沟通产品,和 Slack 对标。)
毕竟我们可能都有特别喜欢在聊天的时候一句话只发几个字,还不停的发的同事或朋友——有了这个功能之后,我们也许就可以直接屏蔽ta的消息通知,然后隔段时间看一下总结就行了。
在这个 TLDR 功能的背后,实际上是谷歌在自然语言理解和处理方面的一次“大跃进”式的突破。
在过去,类似的文本总结功能通常需要神经网络模型同时具有长文本段落理解、信息压缩和语言生成方面的能力,对于以往的模型来说是不可能的。
随着谷歌近几年在超大规模语言模型和多模态机器学习方面的进步,这一看起来非常简单,正常人可以轻松具备的能力,才终于被机器获得。
| 用计算的力量,让知识无远弗届
去年,谷歌推出了 LaMDA (Language Model for Dialog Applications),一个主要用于对话类应用的语言生成模型。我们在去年的 I/O 大会报道中曾经详细介绍过这个模型。
今年,谷歌在 LaMDA 的基础上进一步开发,强化了模型的参数量和能力,并终于推出了 LaMDA 2 模型。已经有数千名谷歌员工在试用这一模型并为 Google AI 的研究开发团队提供反馈。
在此基础上,谷歌还推出了一个名为 AI Test Kitchen 的测试环境。这是一个应用,目前仍在小范围封闭测试中,主要目的是让一小部分人跟它背后的 LaMDA 2 进行对话,提出各种各样的问题,或者让它完成各种各样的任务。
目前 AI Test Kitchen 已经开放了三个 Demo:
1)想象 Imagine it,用户给出一个地点,让模型自己想象那里的景色并生成描述:
2)分解步骤/规划列表 List it,你可以问它一个复杂的问题,比如“把大象装进冰箱”,然后看它把完成任务需要的步骤列出来。
值得一提的是,分解和生成的步骤列表当中的每一项,还可以继续分解裂变;而且,它不仅能够生成列表(提炼知识),还能够在具体步骤上提供额外的详细指导(设定几种不同的具体情况,并提供不同的建议)。
3)描述 Talk About It,给一个既定的话题,让他随便说些什么。
目前,LaMDA 模型技术还处于早期阶段,在实际试用和完成具体任务的时候会出现一些预料之中或之外的异常情况,比如在用户意图继续讨论当前话题的时候出现跑题,或者分解生成的步骤列表存在错误信息等。
目前,谷歌搜索和其它一些重度依赖知识图谱 (Knowledge Graph) 的产品,已经在利用类似的语言生成模型了。通过 AI Test Kitchen,谷歌希望测试者能够更多地和 LaMDA 进行互动,做出评价,给予反馈。
在未来,谷歌的计划是采用其在最近一年里开发的超大规模语言模型集大成者——PaLM(全称 Pathways Language Model)来完成更加复杂的语言模型类任务。
PaLM 和前序超大规模语言模型最大的不同,就在于它有一个“思路链条”(Chain of Thought) 系统,并且能够在输出结果的时候把这个推理逻辑一同体现出来。这和以往被认为是黑盒子的神经网络模型工作方式产生了非常大的不同,不仅在 AI 可解释性上获得了长足进展,还展现出神经网络在仿生(人类)的工作机制上的重要进步。
开发超大规模语言模型、多模态神经网络等目前最先进的机器学习技术,并且将其用于谷歌的核心商业产品,对于这家公司来说尤为重要。
互联网乃至整个人类社会每天都在生成大量的信息,而谷歌需要维持将这些信息高效地转变成成为知识,并且让这些知识可以被每一位用户及时、方便地获取的能力。
虽然今天谷歌仍然是世界的百科全书,但只有维持这种能力,谷歌才能继续实现其当前商业地位和人类社会地位的永续。
| One More Thing: 借助 AR 和翻译的力量,打破语言的隔阂
这场 I/O 大会也发布了不少硬件产品,它们并非我们今天主要关注的对象,你可以通过硅星人的母站品玩的报道来了解这些硬件产品。
不过值得一提的是,还真有一款今天展示的硬件,以它自己独特的方式,强化了今天谷歌想要传达的主题。
主题演讲的最后,Pichai 播放了一段视频,展示了谷歌正在开发的一款智能眼镜原型产品。
这支眼镜,看起来一点都不“智能”。然而,它却能够实时翻译面前的人所说的话,并且把翻译结果显示在镜片上:
更厉害的是,它还能够翻译美国手语 (ASL):
语言是人际沟通最重要的工具。然而,如果对方说的是完全不懂的语言,或者当对方是聋哑人的时候,我们之间的沟通就成了一堵难以跨越的高墙。
在高墙面前,谷歌选择了它最熟悉的方式——用技术去消弭隔阂,使得难以进行的沟通,终于得以成为可能。
曾几何时,“科技以人为本”作为一家科技公司的标语,被传为佳话。而在今天,谷歌更加具体地帮助我们拆解了“科技以人为本”的概念究竟是什么:
科技的本质是知识与计算。而归根结底,知识与计算的存在,都应该是为了我们更好地理解世界,并被世界所理解。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。