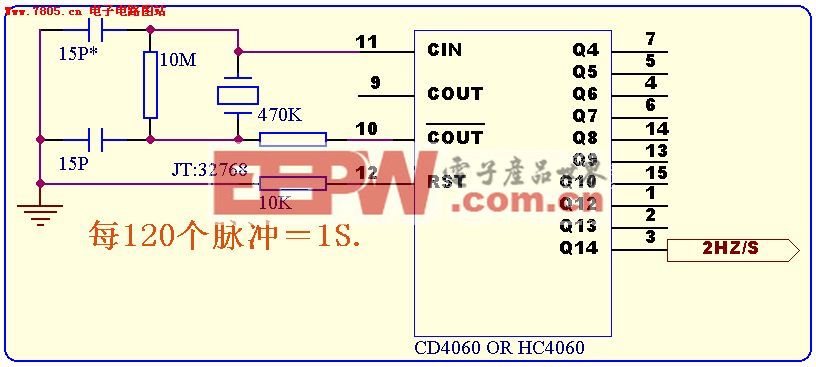
RGB图像重建非刚性物体三维形状(CVPR)

概述
动物在自然界中广泛存在,分析它们的形状和运动在很多领域至关重要。但是给动物形状建模比较困难,因为捕捉人体形状的的3D扫描方法对野生动物不太适用,因此这篇文章提出了一种单独从图像捕捉动物的3D形状的方法。
动物的可变形性使这个问题极具挑战性,为了解决这个问题,作者使用了一个动物形状的先验模型来拟合数据,然后在一个典型的参考姿势变形动物的形状。与以前的方法相比,该方法明显提取了更多3D形状的细节,并且能够使用少量的视频帧来建模新物种。此外,投影的3D形状足够精确,以至于能够从多个帧中提取真实的纹理图。
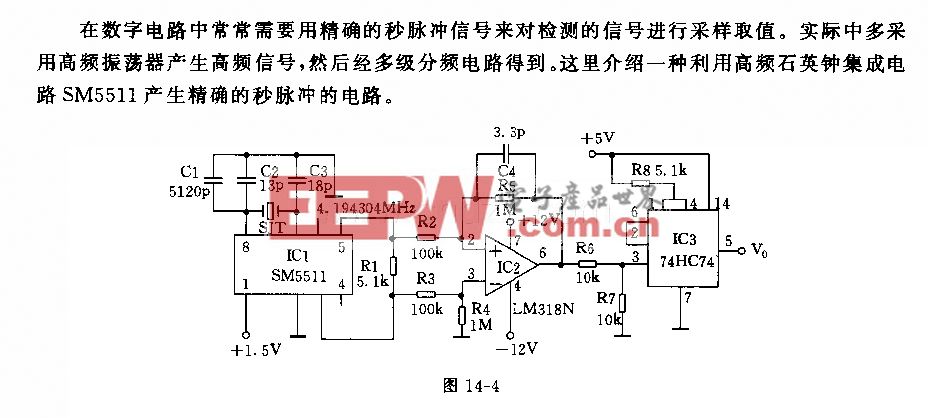
简介
研究动物不仅对科学很重要,对整个社会也很重要。计算机视觉可以为动物的三维捕获、建模和跟踪提供方法,不幸的是,现在很少有方法支持捕捉逼真的动物形状和纹理,像下图一样。

现在已经有成熟的工具来制作人体的三维模型,这些模型真实、可微分、计算效率高。
相比之下,给动物建模的方法比较少。但是动物三维模型的可用性,将打开很多领域,例如生物力学、神经科学和仿生机器人等等。
尽管有很多关于人体形状模型的研究,但是不能将这些方法直接用到建模动物形状。主要原因是人体模型很容易得到,同样的方法对动物来说却比较困难,不容易获得3D训练数据集。
从动物的图像和视频比较容易获得,因此,大部分以前的工作都集中在从图像和视频中学习三维模型,但是不能提取逼真的动物形状。现存的工作基于人工干预,就像本文中作者采用的方法一样。
从图像中估计动物形状的关键挑战是它们是可连接和可变形的,并且动物处在不同的状态。尽管这样,动物的基本形状是一致的,因此,作者认为关键在于将动物的铰接结构与其形状分开。
考虑到问题的复杂性,作者使用了SAML模型,它捕捉了各个动物的形状。SMAL是从跨越一系列动物物种的玩具雕像的3D扫描中学习到的【1】,作者使用了SMAL模型的两个关键方面:基于顶点的形状与关节分解可以估计一致的形状和近似估计新物种形状的能力。由于SMAL模型缺乏动物细节,因此使用它作为细化形状的起点。作者在此基础上推陈出新,发明了一个新的方法,并给它名为为“SMALR”,意为精致的小。
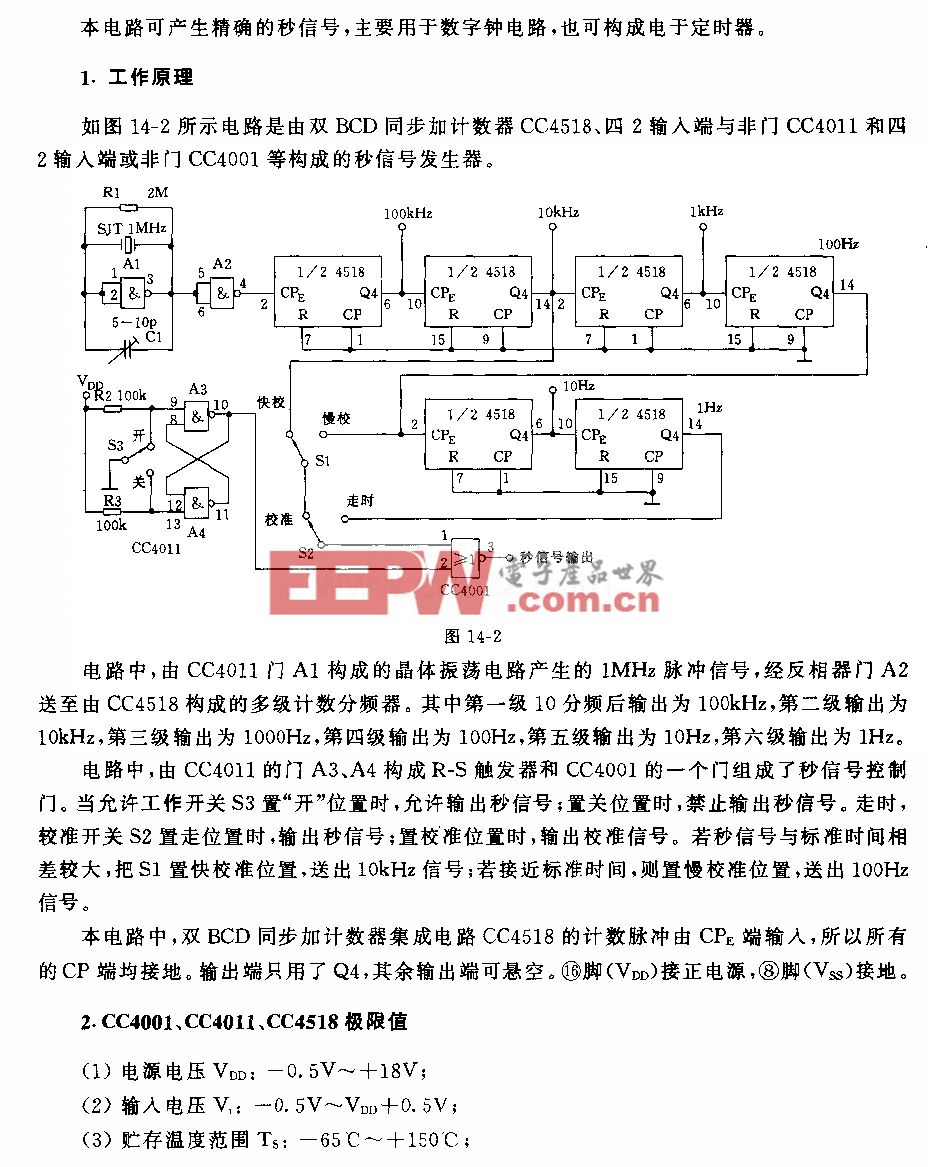
前期工作
为了获得足够的真实数据,作者从野生动物的照片和视频中学习这些模型。这提出了重大的技术挑战,在以前的文献中没有提到过。下面描述已经完成的工作,以及这些方法在哪些地方不足以完成学习动物的详细3D形状任务。
3D扫描的化身:有大量工作是学习人体的三维模型,这些工作起始于很多人在不同姿势下的三维表面扫描,但是不适合动物建模。Zuffi等【1】通过扫描动物玩具解决了这个问题,但是数量和真实性是有限的。在这里,作者的方法超越了以前的工作,并且能够提取与三维形状相关的纹理图,类似的研究很少。
图像中的刚性场景:有大量的工作是从相机图像和视频中恢复刚性场景的形状。经典的立体视觉和SfM方法假设所有的图像都是用同一个相机捕获的,并且当场景是静态的时,相机是移动的。在这里作者做了相同的工作,但是对象是非刚性的、铰链的。
行为捕捉:即立体视觉运用于运动中的人类。有许多方法假定多个静态校准和同步的摄像机,通常都安装在背景和照明可控的环境中,经典的方法包括提取轮廓和使用空间雕刻来提取视觉外壳。作者也使用轮廓,但是只有一个移动的摄像机和一个移动的动物。
动物照片:Cashman和Fitzgibbon【2】通过几张照片学习动物的可变性模型,其他人也做了相似的工作,如下图所示。所有这些模型在模拟动物外形的能力上都是有限的,因为它们不能明确地模拟关节。最终的效果比以前的方法更真实,但过于平滑和通用,不适合个体。

动物视频:视频为动物形状提供了潜在的丰富信息来源。尽管也有大量工作从视频中建模,但是都存在很多缺陷,不能够建立3D网格。这里最相关的是Reinert等【3】的工作,他们展示了从视频中提取粗略动物形状。虽然可以从一个视频帧中恢复纹理图,但不会从多个帧/视图中合并纹理。
从图像中学习3D模型:最近有研究使用cnn从图像中生成3D模型,到目前为止,这些研究集中在像汽车和椅子这样的刚性物体上,它们的训练数据非常丰富。对于动物来说,很少有好的3D关节模型可以用来训练cnn,这就是为什么作者要从图像和视频中恢复它们。
方法
作者使用的SMAL模型可以代表5种来自不同四足科的动物:猫科、犬科、牛科、马科和河马科。动物的形状由一组形状变量表示,这些变量定义了应用于模型模板的顶点变形,以获得特定动物的形状。让β为形状变量的行向量,然后一个特定动物的形状计算为:

其中Vtemplate表示模型的顶点,Bs是变形向量的矩阵。给定一组姿态变量r和全局平移t,模型在需要的姿态下生成三维网格顶点v(β,r, t),并使用线性混合蒙皮算法。
给定一组带有注释标和轮廓的动物图像,就可以得到它的3D形状,如下图所示。首先将SMAL模型与图像对齐,获得每幅图像中动物形状和姿态的估计。其次,优化初始网格的正则化变形,以更好地匹配轮廓和注释。最后,从图像中提取动物的纹理,从而得到一个完整的、有纹理的3D模型。

对图像进行SMAL模型对齐:设I(i)为获得的动物N幅图像的集合,S(i)为通过背景减法或人工分割得到的N幅轮廓图像集合,v(β(i), r(i), t(i))为N个SMAL模型的网格顶点集,K(i)为标志的集合。每个标志都与3D模型上的一组顶点相关联,表示为vK,j,与第j个标志相关的模型顶点数表示为nH(j)。用****投影来建模相机,c(f(i), rc(i)c, tc(i))表示由焦距f、3D旋转r和平移t定义的一组相机。
首先估计沿z轴的平移量:

然后通过解决一个优化问题来获得平移和全局旋转的估计:


将所有模型参数的损失和所有图像的焦距最小化,让Θ(i) = (β(i), r(i), t(i), f(i))为第i幅图像的未知量,目标为:

与其为所有帧估计单个形状,不如为每帧估计不同形状,但在它们的差异上加上惩罚,这样的优化效果会更好,例如将所有帧中的形状规整成相同的形状:

其余各项的详细公式在论文中均有讲解,这里不再赘述,最后获得了所有图像的姿态、平移和形状的估计。
从图像中恢复SMALR形状:通过估算拟合SMAL模型的偏差,从图像中获得更精确的3D形状。对于每一种动物,定义一个顶点位移矢量dv,修改SMAL模型,如下所示:

由于一些符号的滥用,重新定义Ekp和Esil,保持姿势、平移、相机和形状参数固定,设置为前面优化的值。然后,为了顾及dv,取以下表达式的最小值:

一旦解决了dv,就有了动物形状vshape(dv),并再次执行SMAL姿态估计步骤,保持形状固定。最后,在恢复了许多动物的详细形状后,采取新的形状,重新学习SMAL的形状空间,使它能够捕捉更广泛的动物形状。
纹理恢复:为了从图像中恢复动物的纹理,作者为小模型定义了纹理坐标的UV贴图。给定每个图像和相应的估计网格,定义纹理图像和每个纹理的可见性权重。将纹理图进行加权平均,利用SMAL模型的对称性来定义一个对应于对称网格的纹理映射,其中动物的左右两侧被交换。对于对称的纹理图像,可以用两种方式来使用它:为左/右对应的纹理赋于它们的平均值来恢复对称纹理图,或者可以填充在对称纹理图像中没有定义对应值的纹理。
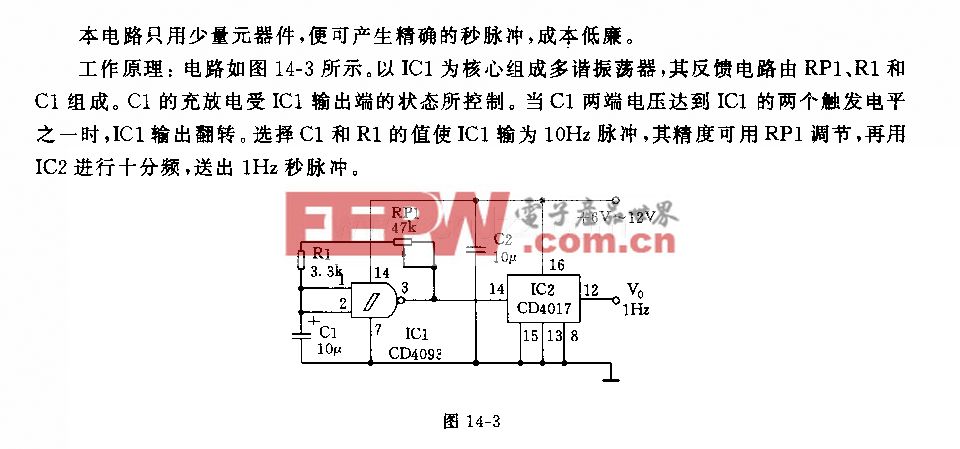
实验效果

右边是输入图像,左边是SMAL模型,中间是SMALR模型,上面是纹理图

中间是SMAL模型,下面是SMALR模型,左上是输入图像,右上是恢复的纹理图
图片
从上往下依次是重建的三维网格、应用纹理的网格和具有相应姿势的图像
参考文献
【1】S. Zuffi, A. Kanazawa, D. Jacobs, and M. J. Black. 3D menagerie: Modeling the 3D shape and pose of animals.In IEEE Conf. on Computer Vision and Pattern Recognition(CVPR), July 2017.
【2】T. J. Cashman and A. W. Fitzgibbon. What shape are dolphins? building 3d morphable models from 2d images. IEEE Transactions on Pattern Analysis and Machine Intelligence,35(1):232–244, Jan 2013.
【3】B. Reinert, T. Ritschel, and H.-P. Seidel. Animated 3D creatures from single-view video by skeletal sketching. In GI’16: Proc. of the 42nd Graphics Interface Conference, 2016.
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。