深度好文:大神解读OpenVIno

这两年人工智慧当道,无人自动驾驶汽车技术也随之兴起,我想超过四十岁的大叔们心中最完美的自驾车莫过于1980 年代电视影集「霹雳游侠」中李麦克开的那台「伙计」了。
「伙计」拥有高度人工智慧,不但可以自动驾驶,遇到状况也会自动闪避,还可以轻松和人对话解决各种问题,李麦克拿起手表还可呼叫「伙计」开到指定地方,简直就是现代人工智慧自驾车及语音助理的最佳范本!
不过自驾车这项技术听起来就很难,那Maker 们有没有机会自己土炮一台呢?
说起自驾车(Autonomous Car)或是先进驾驶辅助系统(Advanced Driver Assistance Systems, ADAS)主要都是希望车辆在没有人为操作下即可自动导航(GPS 卫星定位、路线规画)、避障(闪避车辆、行人或异物)及环境感测(看懂灯号、路标),同时将使用者安全地带到目的地。目前各国争相投入研发资源,大到无人公车、卡车、货柜车,小到无人计程车、送货车、电动轮椅甚至无人农业耕耘机、采收机,就是不想错过新一波的交通革命。
在自驾车众多技术中最不可缺少的一项就是电脑视觉技术,但要搞懂一大堆数学、人工智慧理论、程式撰写方式、系统框架和硬体架构,还得懂得如何建立资料集、训练及优化(加速)模型,这可就难倒大多数人了,难道就不能「快快乐乐学AI」,站在巨人的肩膀上看世界吗?
英特尔(Intel)为了让大家能够快速入门,因此提出了一项免费、跨硬体(CPU、 GPU、FPGA、ASIC)的开放电脑视觉推论及神经网路(深度学习)优化工具包「OpenVINO」( Open Visual Inference & Neural Network Optimization Toolkit),同时提供很多预先训谏及优化好的神经网路模型可供大家直接使用。
影像辨识目标在进入主题之前,首先要先认识一下影像辨识的常见项目及定义,如下图所示:
A. 影像分类:一张影像原则上只能被分到一个类别,所以影像中最好只有一个主要物件。若影像中出现多个物件,那分类时则可能出现多个分类结果,同时会给出每个分类的不同机率,此时误分类的可能性就会大大提升。
B. 物件定位:一张影像中可同时出现多个相同或不同物件,大小不据,辨识后会对每个物件产生一个边界框(Bounding Box),如此即可获得较为准确的物件位置(座标)及尺寸(边界框长宽)。
C. 语义分割:是一种像素级分类,意思就是每个像素都只会被归到某一分类,如此就可取得接近物件真实边界(Edge)。但缺点是多个相同物件类型的像素都会被分到同一类,当物件太靠近或部份重叠时就不易分清楚共有多少物件。
D. 实例分割:这也是一种像素级的分类,和语义分割的差别是相同类型的不同物件所属像素就会被区分成不同分类(颜色),包括物件有部份重叠时,如此就能更正确判别影像中的内容。
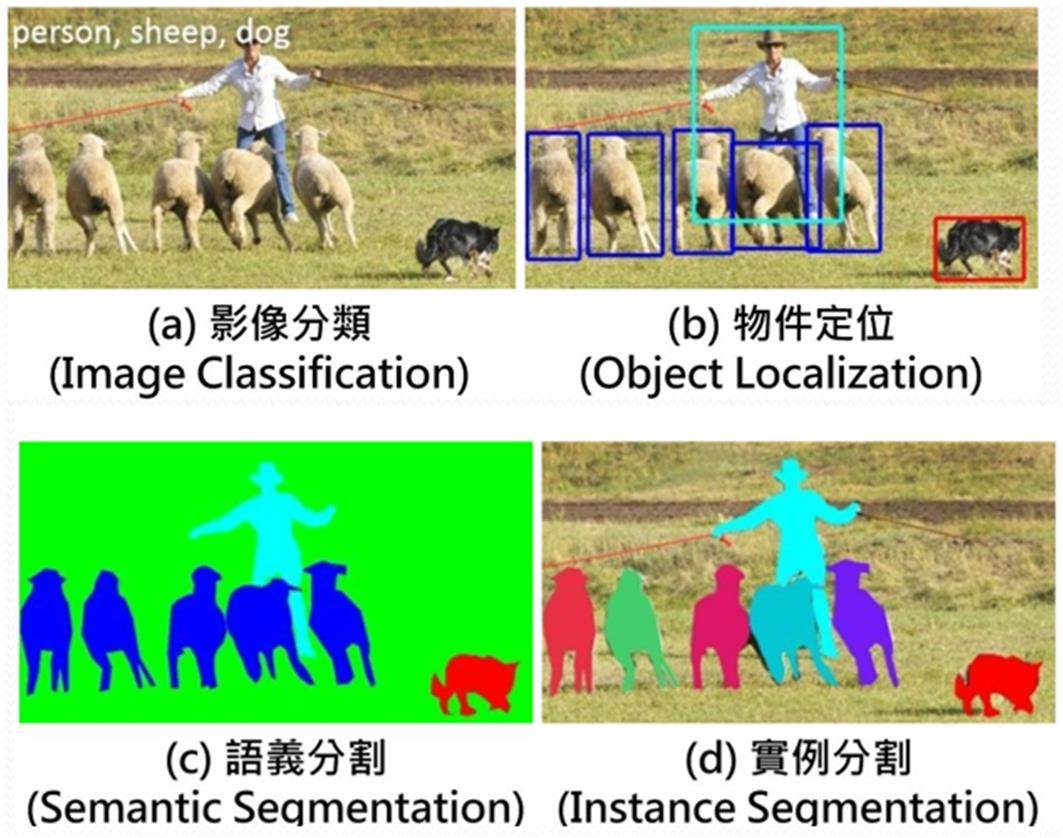
影像辨识的常见项目(图片来源)
以上视觉辨识难度依序递增,同时在样本训练及推论时间也随之巨幅成长。在自驾车领域较常用到「物件定位」,比方说找出前方车辆、行人、号志位置,但当场景较复杂(如市区)时,同一影像中物件数量大增,且边界框大量、大面积重叠,可能会影响辨识结果,因此更需要像语义分割及实例分割这类像素级分类。
不过由于实例分割的计算量大过语义分割许多,且现实中不需要分的如此仔细,所以大部份仅采用语义分割来侦测场景中的多种物件,比方说道路、人行道、地面标线、背景、天空、植物、建物等等,如下图所示:

语义分割应用于自驾车,(a)仅道路,(b)道路、车辆、路标等多物件辨识(图片来源)
Intel OpenVINO简介玩过「电脑视觉」的朋友肯定对开源工具「OpenCV」不会陌生,这个强调不要自己造轮子的开源视觉函式库,是英特尔(Intel)于西元2000 年释出的,不管是个人或商业用途皆可任意使用,不必付任何费用。OpenCV 除了原有对Intel CPU 加速函式库IPP (Integrated Performance Primitives)、 TBB (Threading Building Blocks)的支援外,发展至今已陆续整合进许多绘图晶片(GPU)加速计算的平台,如OpenVX、OpenCL、 CUDA等。
近年来,由于深度学习大量应用于电脑视觉,自OpenCV 3.0版后就加入DNN (Deep Neural Network)模组,3.2版更是加入深度学习常用的Caffe框架及YOLO物件定位模组。今(2018)年Intel更是推出开放(免费)电脑视觉推论及神经网路(深度学习)优化工具包「OpenVINO」(Open Visual Inference & Neural Network Optimization Toolkit)。
OpenVINO整合了OpenCV、 OpenVX、OpenCL 等开源软体工具并支援自家CPU、 GPU、FPGA、ASIC (IPU、VPU)等硬体加速晶片,更可支援Windows、Liunx (Ubuntu、CentOS)等作业系统,更可支援常见Caffe、TensorFlow、Mxnet、ONNX 等深度学习框架所训练好的模型及参数。同时,兼顾传统电脑视觉和深度学习计算,从此不用再纠结到底要选那一种组合来完成电脑视觉系统了。
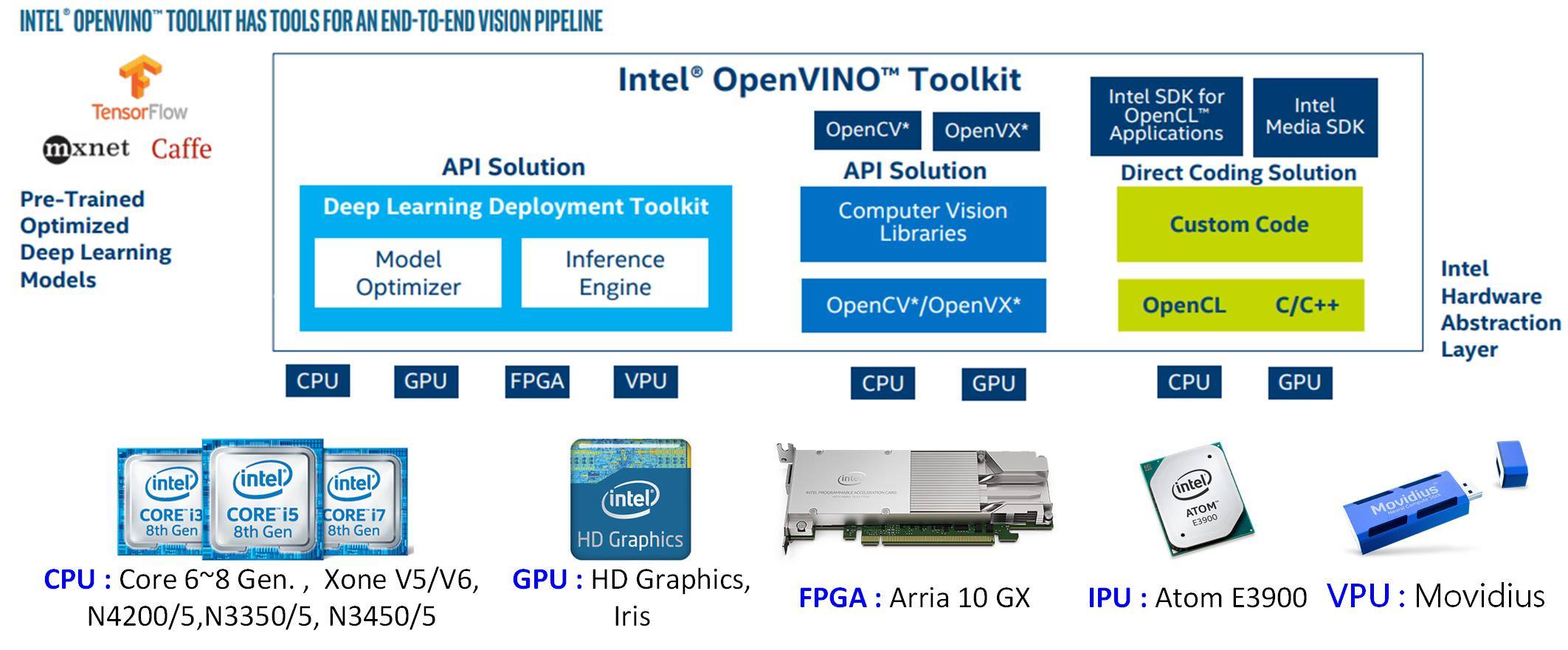
INTEL OpenVINO架构及支援硬体加速装置(图片来源)
OpenVINO 主要是用来推论用的,特定模型的参数必须在其它框架(TensorFlow、Cafee、Mxnet)下训练好才可使用。OpenVINO 除了可提供硬体加速外,更提供模型优化器(Model Optimizer)功能,可协助去除已训练好的模型中的冗余参数,并可将32bits 浮点数的参数降阶,以牺牲数个百分点正确率来换取推论速度提升数十倍到百倍。
优化后,产出二个中间表示(Intermediate Representation、IR)档案(*.bin, *.xml),再交给推论引擎(Inference Engine)依指定的加速硬体(CPU、GPU、FPGA、ASIC)进行推论,如下图所示:
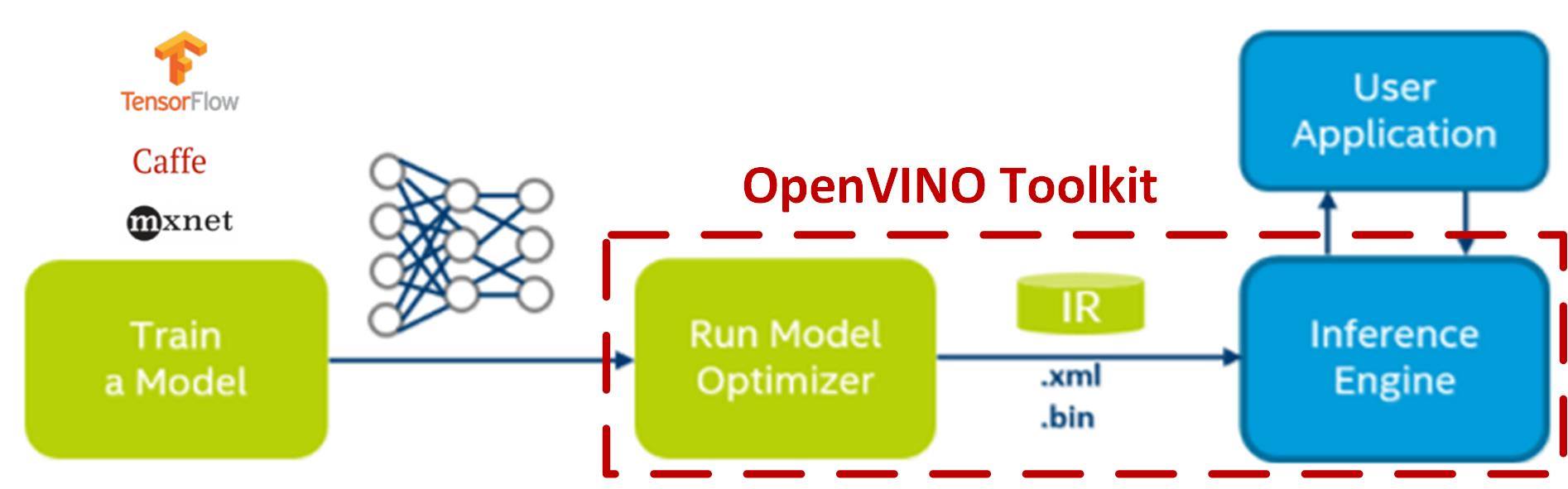
OpenVINO模型优化及推论引擎架构(图片来源)
影像语义分割原理在OpenVINO 中提供了多种预训练及优化好的深度学习模型,包括影像分类(AlexNet、GooLeNet、VGG、SqueezeNet、RestNet)、物件定位(SSD、Tiny YOLO)及一种类似全卷积神经网路(Fully Convolutional Networks、FCN)的语义分割模型(like FCN-8s),接下来就简单说明FCN 的运作原理。
一般传统用于影像分类的卷积神经网路(Convolution Neural Network, CNN)是经过多次卷积层(Convolution Layer)取出特征图(Feature Map)加上池化层(Pooling Layer)令影像缩小一半后,再经过全连结层(Fully Connection Layer)产生不同分类的机率,最后再找出机率最高的分类当作输出结果(如下图上半部)。

影像分类(CNN)与语义分割(FCN)深度学习模型概念(图片来源)
因为全连结层把所有的空间资讯全部压缩掉,因此无法了解到每个像素被分到那个类别。为了,能得到每个像素的分类(语义分割),Jonathan Long在2015年提出 FCN论文解决了这个问题。主要方式是把全连结层也改用卷积层,产出和原影像尺寸相同的热力图(Heatmap),用以表示每个像素属于某一类的机率有多高。
如同上图所显示,最后会产出1000 千张热力图,接着再对1000 张图相同位置像素计算出最大机率的分类,最后将所有分类结果组成一张新的图即为语义分割结果图。
原始影像(image)经多次卷积(conv)及池化(pool),到了pool5 时影像尺寸已到了原尺寸的1/32,此时再经二次卷积(conv6, conv7)后,最后将影像上采样(Upsample)放大32 倍,即可得语义分割结果图FCN-32s(如下图所示)。这样的结果非常粗糙,为了得到更精细结果,可把conv7 结果放大2 倍加上pool4 后再放大16 倍,就可得到更精细的结果图FCN-16s。
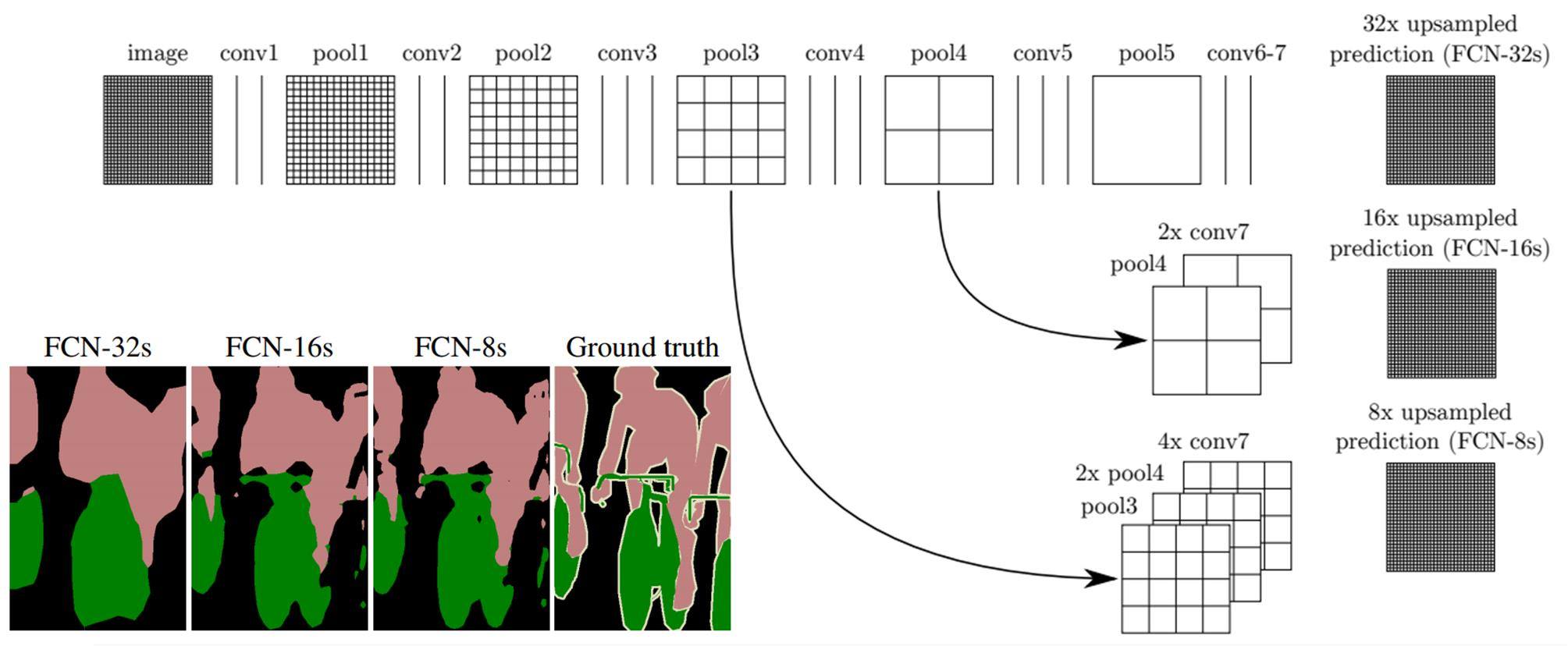
FCN不同上采样语义分割结果(图片来源)
同理,将高(pool3)、中(2 倍pool4)、低(4 倍conv7)解析度的内容加在一起,再放大就可得到FCN-8s 更高精度的语义分割图。虽然FCN 得到的结果和真实内容(Ground truth)分割正确度还有满大的差距,但此方法却是开创以卷积神经网路达成语义分割最具代表性的算法,同时也是电脑视觉最顶级研讨会CVPR 2015 最佳论文。这几年陆续有多种算法被推出,但大部份仍是仿效此种多重解析度整合方式改良而得。
OpenVINO 安装执行接下就开始说明如何以Intel 电脑视觉推论及神经网路(深度学习)优化工具包「OpenVINO」土炮自驾车的视觉系统。首先到OpenVINO 官网,如下图所示,按下左上角黄色按钮,依所需的作业系统(Windows, Liunx)下载工作包并依指示将开发环境(Visual Studio 2015/2017, GCC)安装完成。
虽然官方指定要Windows 10 64bit, Intel Core 6 ~ 8 代CPU 才能执行,经实测在Windows 7 64bit/Intel Core i5 480M (i5 第一代笔电用CPU)、Visual Studio 2017 (含MSBuild)环境下还是可以顺利编译及执行。
以Windows + Visual Studio2017 组合安装为例:
可参考官网提供的****,预设软体开发工具包(SDK)会安装在C:\Intel路径下,而主要开发工具会安装在\computer_vision_sdk_XXXX.X.XXX\deployment_tools\ (XXXX表示版本),其中较重要的内容包括以下四点:
\computer_vision_algorithms 传统视觉算法
\inference_engine 推论引擎及相关范例程式
\intel_models 预先训练模型
\ model_optimizer 模型优化器
安装完成后,开启\inference_engine\samples\build_2017\ALL_BUILD.vcxproj,经编译后即可在\inference_engine\bin\intel64\Release 路径下找到所有编译好的范例执行档。
Intel OpenVINO官网画面(图片来源)
接着可在\inference_engine\samples\segmentation_sample 路径下找到本次土炮自驾车的视觉系统所需用到的范例程式,而程式主要工作内容包括下面步骤:
载入推论引擎插件(Plugin)
读取由模型优化产出的中间档(*.xml, *.bin)
配置输入和输出内容
载入模型给插件
产生推论需求
准备输入
进行推论
处理输出
若不想了解程式码及工作细节的人亦可直接拿来用,只要准备好输入的影像即可得到已做好语义分割的结果影像。目前OpenVINO 提供二种预先训练及优化好的语义分割模型,分别为\deployment_tools \intel_models\ 路径下的semantic-segmentation-adas-0001 (20 类)和road-segmentation-adas-0001 (4 类)。
前者提供较多的分类包括道路、人行道、建物、墙壁、篱笆、电线杆、红绿灯、交通号志、植物、地面、天空、行人、骑士、汽车、卡车、公车、列车、机车、自行车、自己的车头等20 类;后者仅分道路、人行道、标线和背景共4 类;单纯使用CPU 时,前者推论时间约为后者十倍左右。
使用时主要有两个参数,-i 输入影像名称,-m 模型名称,指定时须包含完整路径。另外预设是使用CPU 计算,所以只接受32bit 浮点数(FP32)而不接受16bit 浮点数(FP16)。输入影像尺寸不据,而在20 类语义分割时输出影像尺寸为2048×1024 像素,而4 分类时为896×512 像素。输出档名固定为out_0.bmp(如下图所示)。
自驾车影像语义分割范例执行结果(图片来源:Jack 提供)
由于CPU 计算时会受作业系统是否忙碌影响,所以同一张影像计算每次推论时间都会有所不同。当在Windows 7 64bit/Intel Core i5 480M 2.6GHz CPU/2GB RAM 环境下测试时,20 分类推论时间大约在3.7~4.3 秒,4 分类则在0.3~0.4 秒左右,推论时间和影像内容复杂度无关。后续若改成高阶CPU 或GPU 后相信推论时间肯定能大幅缩短。完整执行范例指令如下所示。
20类语义分割指令:
segmentation_sample -i C:\Intel\sample_pic\input_image.bmp -m
C:\Intel\computer_vision_sdk_XXXX.X.XXX\deployment_tools\intel_models\semantic-segmentation-adas-0001\FP32\semantic-segmentation-
adas-0001.xml
4类语义分割指令:
segmentation_sample -i C:\Intel\sample_pic\input_image.bmp -m
C:\Intel\computer_vision_sdk_
XXXX.X.XXX\deployment_tools\intel_models\road-segmentation-adas-0001\FP32\road-segmentation
-adas-0001.xml
接着,在网路上随机收集一些道路影像,包括白天、晚上、郊区、市区、远近镜头等,并用二种模型进行测试影像语义分割,其结果如下图所示,左为原始影像,中为20分类,右为4 分类。从结果来看,大致还分得还不错,像(b)中图汽车和卡车重叠及自身车头,(c)的道路和人行道虽然颜色及纹理很像,都能分得很好。不过晚上的影像就有些小误判,可能和影像过暗及物件过小影响。

自驾车影像语义分割测试结果。左为原始影像,中为20 分类,右为4 分类(图片来源:Jack 提供)
为了进一步了解这两种模型对类似道路场景是否能适用,另外收集了公园步道(g)、卖场弯道(h)、客厅走道(i)、百货公司走道(j)、候机室走道(k )进行测试(结果如下图所示)。由测试结果来看,在20 分类时(g)的天空、地面、植物、建物算是正确分辨,而红黑砖路则被当成人行道(浅紫色),(h)、(k)勉强能分出道路(深紫色), (i)、(j)则把道路当成人行道(浅紫色)也勉强可以算对,(j)、(k)中的行人(暗红色)都有正确被辨别出,但(i)的沙发则被误判为行人和汽车(蓝色)。
在4 分类时(g)、(h)、(k)比较能分辨出道路(浅紫色),(h)甚至还能正确认出地面标线(暗蓝色),而(i)、(j )则是完全无法辨识,全部都被当成背景(深紫色)。所以当测试影像是室内或非正常道路时,误判率明显提高,归究其原因应该是训练的资料集中并没有这些类型的影像,加上室内光滑地面有大量反光及摆放大量物件造成影响。若想应用这些模型在室内场景,则需要另外大量收集相关影像重新标注后再重新训练,才能让正确率有所提升。

非标准道路影像语义分割测试结果。左为原始影像,中为20 分类,右为4 分类(图片来源:Jack 提供)
小结Intel 所提供的开放(免费)电脑视觉推论及神经网路(深度学习)优化工具包「OpenVINO」让不懂电脑视觉和深度学习原理的小白可以在很短的时间上手,不必担心如何建置开发平台、选择深度学习框架、训练及优化模型和硬体加速等问题,只需利用预先训练及优化过的语义分割模型,瞬间就可土炮出一组看起来很专业的自驾车视觉分析系统。
若觉得执行效能不佳,未来还可轻松从CPU 移植到GPU、FPGA 甚至Maker 最爱的Movidius 神经计算棒(VPU),实在让使用者方便许多,而其它更多更方便的功能就有赖大家亲自体验一下啰!
作者:许哲豪Jack
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。