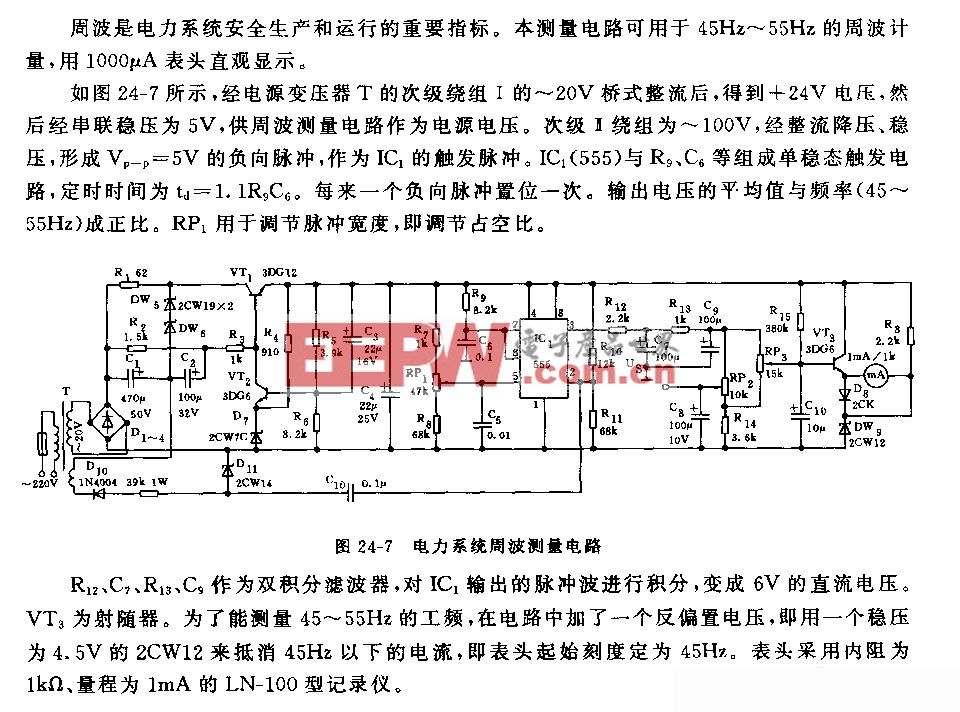
十字链表在电力系统潮流计算中的应用

在上海电力局2020年规划设计中,要对多种运行方式及网架结构进行计算。在计算过程中发现:如果采用通常的压缩数组存储方法,需要进行大量的修改工作。因此本文提出十字链表方法,将网络的拓扑结构与数值信息存于十字链表中,使其独立于计算,能保证数据的可重用性和灵活性。这种方法适用于与拓扑相关密切的电力系统计算,本文就潮流计算作简单介绍。
1十字链表
1.1十字链表简介
稀疏矩阵的十字链表(orthogonallinkedlist)表示法是用多重链表来存储稀疏矩阵的。稀疏矩阵中的每一个非零元素用一个结点来表示。一般结点由5个域组成。如图1(a)所示,其中行(row)、列(col)、值域(val)分别表示某非零元素所在行号、列号和数值。向下指针(down)用以链接同一列中表示下一个非零元素的结点,向右指针(right)用以链接同一行中表示下一个非零元素的结点。这样,表示每一行中非零元素的结点之间构成一个循环链表,表示每一列中的非零元素的结点之间也构成一个循环链表。同时,每行、每列的循环链接表都有一个表头结点,以利于结点的插入和删除等操作。表头结点的行号、列号以及数值域都没有用。为节约存储,可将这两组空表头结点合用。每一个表头结点的向下指针链接对应列的非零元素结点,向右指针用以链接相应行的非零元素结点。此外,借用数值域来作为将各个空表头结点也链接成一个链表的指针。整个表有一个总的空表头指针,在一般结点标以行号、列号处标以矩阵行数m、列数n。有一个指针(root)指向这个总表头结点。由于总表头结点链接着各行列的表头结点,所以由这个指向总表头结点的指针就可以逐步访问到此矩阵的所有非零元素。
1.2潮流中十字链表的形成
在潮流计算中,考虑到电力系统的特殊性,对十字链表进行了部分简化。
(1)每个链表为单向链表,链表中的非零元素按其行号大小排序。
(2)非零元素省略其向下指针及行值,省略列表头结点。
(3)行表头结点省略其行、列及值域,增加对角元指针指向矩阵对角元,总表头结点就是行表头结点链表的表头。
如果表头结点在表头结点链表中的位置为nCol,则此行链接的非零元素链表中的结点都是与第nCol结点相关联的。
表头结点中有两个非零元素结点的指针和一个表头结点指针。第一个非零元素结点指针mpRight指向本行链表中第一个非零元素,第二个非零元素结点指针mpCorner指向本行链表中与对应行具有相同行号的非零元素,即对角元。表头结点指针指向下一行的表头结点。
结点有3个成员,指针mpRight指向下一个与本行表头结点相关联的结点,Data包含着与这种关联对应的数值或某种结构体。本文中包含导纳,mnCol则是此非零元素结点的结点号。
2十字链表潮流方法
2.1导纳矩阵的形成
在一般的潮流计算中,形成导纳矩阵的要预先在程序中开出足够大的数组。虽然采用了压缩存储技术,但是静态数组的缺点无法克服。程序无法确切知道所需内存空间的大小,只得开出比较大的数组。这样节点数比较小时,内存空间浪费了;节点数大时,程序无法处理。十字链表的优点在于,所有结点所需内存都是动态申请的,包括表头结点(其多少由节点数决定)和非零元素结点(其多少由支路数决定)。
在此矩阵中,对角元的Data为节点自导纳,非对角元的Data为该非零元素对应节点与其表头结点对应节点之间的互导。
读入节点数之后,程序即对表头结点链表初始化。表头结点数目比节点数大一,最后一个表头结点链接的链表存储节点对地导纳。随后每读入一个节点,就在对应的表头结点后插入一个对角元,并将对角元指针指向它;每读入一条支路,如果是一条新的支路,就在此支路的每一个节点对应的表头结点后都插入一个对应另一个节点的非零元素结点,然后修改这两个节点的互导,否则直接修改互导。所有互导形成完后,就可计算每个节点的自导了。方法是累加本表头结点后的链表中的所有非零元素的Data值,然后乘以-1。节点的对地导纳可将这一部分计算在内。root指针指向总表头结点即表头结点链表中的第一个结点。
这个导纳矩阵中包含了网架的拓扑结构和与此相关的数值。程序中这个矩阵是基本不变的。原始数据存储在这个矩阵中具有相对独立性。
2.2B1,B2的形成
本文中潮流计算采用PQ分解法。
矩阵B1是原导纳矩阵去掉松弛节点形成的矩阵,B1矩阵的所有数据均取自原导纳矩阵,所不同的是节点的行号。导纳矩阵中节点的行号是原有节点的节点号,而B1矩阵中节点的行号是导纳矩阵中去掉松弛节点后重新排成的节点号。程序必须记录这种节点号的对应关系。矩阵B2是原导纳矩阵去掉松弛节点和PQ 节点后形成的矩阵。同理,程序也必须记录B2矩阵的节点号与原导纳矩阵节点号的对应。若考虑节点的对地导纳,只需访问表头结点链表中对地导纳对应的链表,按行号搜寻即可得到相应的对地导纳。
PQ分解法中B1,B2矩阵每次只需形成一次。实际上如果使用牛顿法,每次都需要形成雅可比矩阵,这时导纳矩阵的相对独立性就显得较有优势。
十字链表法把网架拓扑结构与相关数值一起存储,其存储结构提供了将数学上的解方程方法与网络分析相分离的基矗以下几个步骤就是纯数学问题了。
2.3最优排序及其它一些问题
最优排序与其它存储结构的方法原理是一致的,但注入元的处理方法不一样。静态数组的压缩存储对注入元的处理方法是每行末尾预留空间,其缺陷也在于预留空间大小的设定。在十字链表方法中,注入元的处理就十分方便了。如果排序时产生了注入元,只需在对应行各插入一个新的结点就可以了。这样对注入元的处理只需在排序时考虑,而无需在形成矩阵或在系统分析时考虑了。
当B1,B2矩阵形成并排过序后,就需要解方程了。主要是因子表的形成与消元和回代。可以采用LU分解法求因子表。原理相同,只需注意十字链表的存储结构。形成了因子表并消元回代之后,方程解出了。
然后按照流程,进行反复迭代。功率偏差量小于收敛精度时,就可结束计算了。
3算例
根据IEEE14节点模型计算的导纳矩阵(只列出部分,导纳矩阵实部略),原始数据中没有计入第9号节点的对地导纳。
如上所示,导纳矩阵输出时先输出对角元(访问对角元指针即可得),其后的数据是按照十字链表中的顺序输出的。
4结论
通常的数组存储方法属于静态数据结构,必须在程序的说明部分给出其类型定义或变量说明。某些程序中使用malloc函数或new操作符动态申请数组,但其数组仍然是空间预留的一种实现,也就仍然存在静态数组的缺点。十字链表属于动态数据结构,它的规模大小在程序执行时是可以变化的。十字链表中结点的数目是在程序执行时动态增长的,导纳矩阵随着数据的输入逐步形成。使用十字链表的存储可使存储的分配较为灵活,更充分的利用内存。
对应于电力系统中节点、线路的增加或删除等的结点操作,利用十字链表法比静态数组实现起来要方便而且快速。十字链表法中导纳矩阵的形成本身就是结点的插入操作的结果。例如添加线路的方法与读入数据时添加线路的方法就是完全一样的。
通常的处理方法是将拓扑结构与网架数据分开存储在两个数组里。再利用另一个数组作为索引来访问拓扑结构和数据。十字链表的存储方法将网架的拓扑结构与数据存储在一起。于是,潮流计算中系统分析方法与数学处理方法就能分离开来,各种数据的处理实现模块化。
如果在C++中封装十字链表,可以把对十字链表的访问变得如同访问一个二维数组一样方便。封装的十字链表将具有很强的可重用性,作为一种自定义的数据类型,可使程序具有很强的可读性,便于程序的编制和维护。

c++相关文章:c++教程

评论