核心路由器中多端口线卡调度的设计与实现

线路接口卡是核心路由器访问线路与访问设备间的一种设备接口,主要实现路由器接口上物理层和链路层的功能,必须实现无丢包线速处理,是路由器的关键部件之一。线卡主要关注以下几个方面:排队(如FIFO、Modified Deficit Round Robin)、拥塞控制(如加权随机早期检测)及其它特性(如访问列表、访问速率、数据流统计)。
IPv6路由器系统结构主要由线路接口、多功能转发处理、高速交换网络、内部通信、主控和网管等部分组成。ATM多端口线卡作为IPv6核心路由器的重要线路接口,需要提供8个双向的155MbpsATM光接口,支持64个永久虚连接。多端口线卡中多路数据的合路与分路需要建立一个良好的调度机制来保证数据包的线速处理与每一路数据的公平性。本文对ATM多端口线卡输入和输出两个流向上的数据包调度进行了研究,提出了一种具有一定通用性的多端口线卡调度策略的设计实现方案。
输入处理流向的调度策略
在对多端口线卡输入处理流向调度策略的分析中,我们以ATM多端口线卡为研究对象。ATM多端口线卡支持8个ATM155M光接口,其中每接口支持 8个永久虚连接。
为了保证8路64个虚连接的ATM信元传送及处理的公平性,满足路由器整包处理的需求,提出了基于信元的公平分片轮询调度(Cell Round Robin Scheduling;CRR)和逐包轮询调度(Packet Round Robin Scheduling;PRR)相结合的调度策略,如图1所示。

图1 输入链路控制电路中的调度策略
采取基于信元的公平分片轮询调度主要基于三方面考虑:一是基于信元操作,符合AAL5处理的需求;二是在采用ATM方式时,PM5380内部的 FIFO只能够缓存4个信元,深度有限;三是固定长度包的轮询调度,其理论研究较成熟,也较易于实现,相比不定长包调度可以避免更多的意外情况,能够确保较好的性能。
采取逐包轮询调度,是为了解决AAL5中信元的处理机制路由器系统整包处理的机制之间的矛盾。在信元输入处理时,将信元净荷按其所属的虚连接在相应的虚连接FIFO中依次缓存,直到虚连接FIFO中至少有一个完整CPCS-PDU才能被读取;在虚连接FIFO的输出侧,采用逐包轮询调度的方式对64 个虚连接FIFO进行读取。在输入流向的处理中,我们通过信元净荷在虚连接FIFO中缓存,待完整CPCS-PDU构成后再逐包轮询调度输出的方式解决了上述问题。
整个输入调度的实现参照图1,逐个轮询调度左侧PM5380内部的8个队列,采用分片轮询的方式,若轮询到某一队列时,其队列深度大于53个字节 (信元长度),且对应的虚连接FIFO未满,则输出,否则该队列轮空,切换到下一个队列;同时轮询调度右边的64个队列,采用逐包轮询调度的方法,在64 个虚连接FIFO的输出侧进行高速切换读取数据。
ATM多端口线卡输入处理流向的调度策略具有一定的通用性,可以根据实际的情况,对于支持的ATM接口和虚连接数量进行改变:输入的8个信元流可根据需要支持的接口数量由ATM接口中的8个变成16个、32个甚至更多,对更多接口的输入信元流同样能够采用分片轮询调度,根据不同虚连接提取出信元净荷在虚连接FIFO中进行缓存;而虚连接FIFO的数量也可以根据我们需要支持的虚连接数量进行改变,采用逐包轮询调度同样能够支持更多的虚连接。
输出流向的调度策略
在ATM多端口线卡输出处理流向上,由高速交换网络送来的数据传送速率最高可达2.5Gbit/s,远大于线路接口输出速率1244Mbit/s (8155Mbit/s)。以往的解决方案对这一问题进行了回避,采用“不能处理则丢包”的方法。这样虽然降低了实现的难度,但对于高速交换网络满负荷传送数据的情况,显得无能为力,无法满足QoS要求和对实时业务提供支持。由此可见,缓存管理机制和调度策略在此的重要性。
我们在以往解决方案的基础上进行了改进,提出了基于门限的调度策略(Threshold Based Scheduling Policy;TBSP)、带有优先级的逐包轮询调策略(Racket Round Robinwith Priority;PPRR)、分类随机早期探测机制(Classification Based Random Early Detection;CBRED)和公平分片轮询调度策略(Cell Round Robin Scheduling;CRR)相结合的方案。
如图2所示,图左侧是输出缓存中数据包队列,图右侧是本接口的8个线路接口FIFO,用于存储去往各个线路接口的数据包,数据包队列和线路接口 FIFO中间是调度机。根据数据包头所带的线路接口指示,数据包被送往相应的FIFO中。假设输出缓存队列队头的数据包要送往FIFO01,而FIFO1 已满不让写入,就会发生队头阻塞。此时若是采取等待直到FIFO1允
(1)在输出缓存中设置门限T;
(2)当队列深度小于T时,若发生队头阻塞,数据包暂时存放在输入缓存中;
(3)在队列深度到达T时若队头对应的FIFO满指示失效,则读出数据包并写入相应FIFO;
(4)当队列深度到达T时若队头对应的FIFO满指示依然有效,读出该数据包并丢弃。
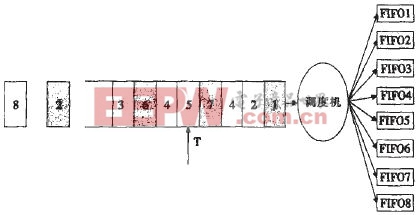
图2 TBSP调度示意图
以上只是解决了输出缓存中数据包的输出调度问题,而处理机过来的协议包也要经过调度送往不同线路接口。由于协议包的速度远远小于数据包的速度,也小于线路接口的传输速度,因此不存在丢包问题。但考虑到协议包要优先发送,我们便提出了带有优先级的逐包轮询调度策略(Racket Round Robinwith Priority;PPRR)。
完成优先轮询调度的合路数据包需在队列里进行缓存,而传统的先进先出(FIFO)队列管理使用简单的尾丢弃策略,使得队列长度成波浪形变化,导致路由器的吞吐量降低和通信的延迟抖动非常大。为避免这种情况发生,因此输出缓存管理采用了分类随机早期探测机制(Classification Based Random Early Detection;CBRED),其原理如图3所示。根据Diff-Serv模型的丢包策略,在多端口线卡中将所有业务根据其对包丢失率的要求分为三类,分别为低优先级、中优先级和高优先级。

图3 分类随机早期探测(CBRED)原理示意图
在输出缓存中设立两个门限M1、M2(M1 整个输出链路控制电路设计采取的存储器管理机制和调度策略如图4所示(队列0表示输入缓存中的单播数据包,队列1表示组播数据包,队列2表示协议包),其描述如下: (1)队列0、队列1或队列2每读出一个整包后,优先查询队列2,其次是队列0,队列1的优先级最低; 在优先逐包轮询调度的实现中,我们设置了一系列的组合逻辑来完成上述的功能,如图5所示。协议数据、单播和组播FIFO的读取优先级由优先调度控制,当协议FIFO中有完整包时且对应接口FIFO未满,则输出该协议包,直到协议FIFO中无完整包或对应接口FIFO已满,将优先级交给单播 FIFO;如果单播FIFO内有完整包且对应接口FIFO未满,则输出一个完整的单播包;如果对应FIFO满,则由门限设置单元提供的门限T分别与单播 FIFO内数据深度比较,决定当查询到单播FIFO时,是否进行读取或丢包操作。我们采用比较器来实现深度的比较,比较器的输出为3位,每一位指示一种状态,即单播FIFO内数据深度是大于、小于或等于门限T。如果小于T,对应的接口FIFO满,则等待,将优先级交给组播FIFO;如果大于或等于T,对应接口FIFO满失效,则输出该FIFO的一个包,将优先级交给组播FIFO,否则丢弃当前的数据包,也将优先级交给组播FIFO。 对组播FIFO执行的操作与单播的情况类似,在这不再赘述。循环一圈后,优先级又交还给协议FIFO,重新开始上述操作。TBSP门限T的设置需基于两方面的综合考虑:网络中各种包长的分布和本模块要求的处理时间。在实现中,我们使用了FPGA片内的2块BLOCKSelectRAM组成TBSPFIFO(TBSPFIFO的位宽为36位,深度为1000),通过实际中多次的单板调试和系统联调,并对测试结果进行分析比较后,我们把T的门限设为640,这是队列深度为1000的时候,实际运行中的最优值。 图5 优先逐包轮询调度实现流程 在分类随机早期探测机制的具体电路实现中,我们根据两级丢包门限M1、M2控制QoSFIFO的写入操作,以保证更高优先级包的可靠传输。如图6所示,我们在对QoSF 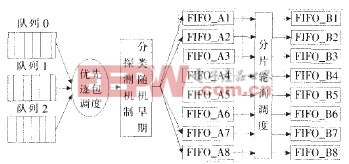
图4 输出存储器管理机制与调度策略
(2)若队列2有整包指示且相应FIFO满指示无效,则读出整包并写入相应FIFO;
(3)若队列2有整包指示但相应FIFO满指示有效,先查询队列0状态,队列0的包调度也采取TBSP策略,如果队列0仍未被读取,则查询队列1状态,队列1的包调度同样采取TBSP策略;
(4)优先逐包轮询调度后的合路包在输出缓存中进行缓存,采用分类随机早期探测机制对缓存进行管理;
(5)输出链路中的8个FIFO与商用芯片之间采用CRR调度策略。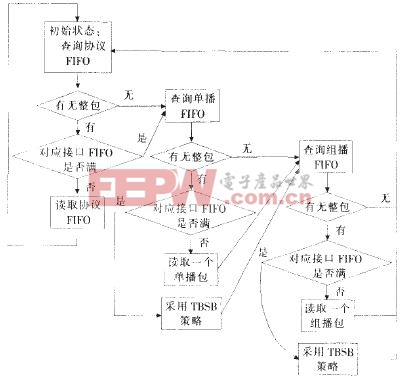
IFO进行写入整包的之前监控QoSFIFO内有效数据的长度,与门限M1、M2比较,根据比较的结果结合当前包内部格式头部的优先级字段(包优先级由转发处理提供,并在ATM接口将8个优先级转化为3个丢包优先级),决定当前数据包是否写入QoSFIFO。若当QoSFIFO内缓存队列深度不超过门限M1时,所有到达的包均写入QoSFIFO;当缓存队列的深度超过门限M1但不超过门限M2时,丢弃低优先级的包,中、高优先级的包仍写入QoSFIFO;若一个缓存队列的深度已超过门限M2,但缓存队列未满时,丢弃低、中优先级的包,高优先级的包仍写入QoSFIFO;一旦缓存队列满时,丢弃所有包。QoSFIFO的写使能信号是控制写入数据和丢弃数据的关键,我们采用比较结果和优先级字段结合的方式,由包头信号同步置位,包尾信号延迟一个周期同步清零产生一个数据包长的高电平,与写入判决信号和延迟一个周期的包尾信号共同产生的写允许信号相与产生FIFO的写使能。这样就实现了写入或丢弃的数据正好是一个整包,避免影响对其它数据包的正常操作。关于CBRED机制的两个门限M1和M2,对此仅作定性考虑,结合工程经验,设置M1= L/2,M2=3L/4,其中L=2000(所选FIFO的深度)。这一结果是在实际测试中,通过不断的分析比较得出的最优值。
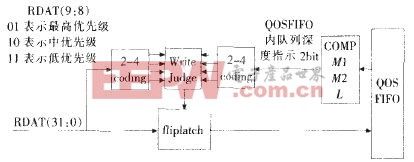
图6 分类随机早期探测实现示意图
ATM多端口线卡输出处理流向的调度策略同样具有一定的通用性,可以根据实际的情况,对优先逐包调度队列数量和输出接口数量进行改变,满足多种需求。
测试结果与分析
ATM多端口线卡参加了国家863“十五”期间重大课题“高性能IPv6路由器基础平台及实验系统”的系统测试,为高性能IPv6路由器提供ATM信元与IP数据包的数据格式转换的功能,其吞吐量测试结果见图7。根据测试结果,当接口平均速率小于1244Mbit/s时,在测试中各种包长的条件下(40byte~1518byte),ATM多端口线卡实现了无丢包线速处理。
ATM多端口线卡的输入链路控制电路中应用并实现了分片轮询调度和逐包轮询调度相结合的策略,结合整个线卡的测试结果,充分证明这种策略是切实可行的,且能保证效率;输出链路控制电路中将TBSP策略与CBRED机制有机地结合起来,可以较好提高系统吞吐量和降低丢包率,实现QoS和实时业务的时延控制,并且在工程上是易于实现的。
小结
本文中,为了保证一定的公平性,满足整包处理的需要,提出了公平的分片轮询(CRR)和即时的逐包轮询(PRR)相结合的调度策略;分析了多端口线卡调度和存储器管理中存在的问题,提出了一种基于门限的调度策略(TBSP),较好地解决了降低系统丢包率和提高吞吐量的问题;为了满足QoS要求和保证实时业务的时延特性,将TBSP策略与CBRED机制有机地结合起来,可以降低系统丢包率,而且能够在一定程度上满足不同业务的QoS要求。本文中存储器管理机制和调度策略均在ATM多端口线卡中得以工程实现,且具有通用性,在支持的输入接口和连接数量上进行增减,可以满足多种多端口线卡的调度需求。


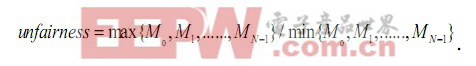





评论