DeepSeek适配国产芯片:差异化表现,商用前景各异

在 DeepSeek 热浪的席卷之下,各大国产 GPU 公司纷纷投身适配浪潮。
本文引用地址:https://www.eepw.com.cn/article/202502/467279.htm看似相同的动作,背后却各有千秋。
如今,业内报道多聚焦于适配 DeepSeek 的公司数量,却很少有人去深究这些公司间的差异。究竟是技术路线存在分歧,还是性能表现高低有别?是生态建设各具特色,亦或是应用场景有所不同?
适配模型,选原版还是蒸馏版?
从适配 Deepseek 模型的角度来看,芯片厂商的动作可大致归为两类。一类是对原生 R1 和 V3 模型进行适配,另一类则是适配由 R1 蒸馏而来的小模型。
至于这三者的区别:
Deepseek R1 定位为推理优先的模型,专为需要深度逻辑分析和问题解决的场景而设计。其在数学、编程和推理等多个任务上可达到高性能。
Deepseek V3 定位为通用型的大语言模型,其在多种自然语言处理任务中实现高效、灵活的应用,满足多领域的需求。Deepseek R1/V3 原版模型通常具有较大的参数量,结构相对复杂。
DeepSeek-R1 系列蒸馏模型是基于 DeepSeek R1 进行蒸馏得到的轻量级版本,参数量较少,结构更精简旨在保持一定性能的同时降低资源消耗。适合轻量级部署和资源受限场景,如边缘设备推理、中小企业快速验证 AI 应用。
虽说各家均在抢占适配 Deepseek 的高地,但实际上各家所适配的模型类型也并不相同。
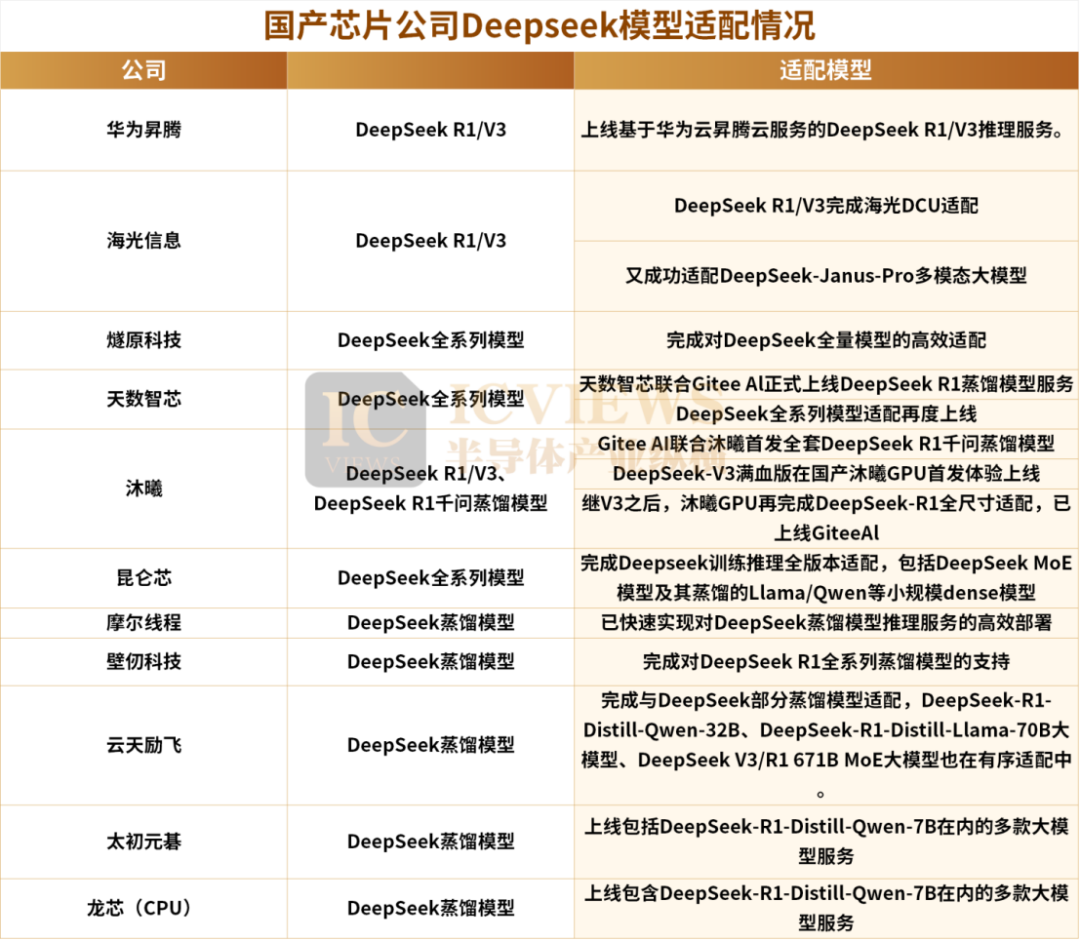
上图可见,虽主流 GPU 厂商均在加速适配 DeepSeek 模型的节奏,但明确宣布适配 DeepSeek R1 及 V3 原版模型的只有一半左右。这类模型对芯片的计算能力、内存带宽以及多卡互联等技术要求极高。其中包括华为昇腾、海光信息。
另一部分厂商则主要支持 DeepSeek-R1 系列蒸馏模型(参数规格在 1.5B - 8B 之间)。这些蒸馏模型的原始模型是通义千问和 LLAMA,因此原本能够支持通义千问和 LLAMA 模型的平台,基本上就能适配这些 DeepSeek 的蒸馏模型,工作量也相对较小。包括摩尔线程、壁仞科技等。
不同大小的模型所适应的场景不一样,云端推理需要模型参数比较大,模型性能最好,主要适配原生 R1 或者 V3 模型;端侧芯片主要适配 1.5B~8B 间的模型,这类模型推理结构非常成熟,无需花费额外的工作。
不同公司,优势何在?
除了所适配的模型种类有别外,各家所选取的技术路线也有所不同,适配时遇到的难度也各不相同。
首先,从当前的技术生态和实际应用场景来看,DeepSeek 模型的运行和适配主要依赖于英伟达的硬件和编程语言,而各家厂商的适配能力则取决于其对原始开发生态的兼容性。
这也意味着,DeepSeek 目前主要适配英伟达芯片,这对其他硬件平台的应用和性能有一定影响。因此是否容易适配基于英伟达 GPU 开发的 DeepSeek 等大模型,与芯片是否兼容 CUDA 有关。能兼容 CUDA 的厂商,彼此间兼容程度也有不同。
其次,从性能表现来看,不同 GPU 的计算能力(如 FLOPS、内存带宽)不同,也直接影响 DeepSeek 在处理大规模深度学习任务时的速度。某些 GPU 可能在能效比上表现更优,适合在低功耗环境下运行 DeepSeek。
接下来,读者不妨看看主流芯片公司在适配 DeepSeek 时,各自具备的优势与面临的挑战。

华为昇腾(Ascend)
昇腾拥有芯片+框架+工具链等全栈 AI 能力,与 DeepSeek 的技术栈适配潜力大。
从硬件方面来看,昇腾 910 芯片针对 AI 训练和推理优化,算力密度高,尤其适合大规模模型训练。
从软件生态方面来看,CANN 异构计算架构和 MindSpore 框架深度绑定,若 DeepSeek 基于 MindSpore 优化,昇腾适配性极强;同时支持 PyTorch/TensorFlow 的迁移工具。
关于昇腾适配 DeepSeek 面临的挑战,若 DeepSeek 依赖 CUDA 生态,需通过华为的兼容层(如昇腾异构计算加速库)转换,可能损失部分性能。
海光信息(DCU)
海光的优势是海光 DCU 兼容通用的「类 CUDA」环境,以及擅长高性能计算。
从硬件方面来看,基于 AMD CDNA 架构的 DCU 系列,兼容 ROCm 生态,对 CUDA 代码迁移友好,适合需兼容现有生态的 DeepSeek 场景。
从场景适配方面来看,在智算中心应用成熟,若 DeepSeek 侧重 HPC+AI 融合场景(如科学计算),海光更具优势。
关于海光适配 DeepSeek 面临的挑战,或许在软件工具链成熟度上。
燧原科技(邃思)
燧原的优势在于云端 AI 训练与推理。
在架构设计方面,邃思芯片针对 Transformer 等大模型优化,计算密度高,适合 DeepSeek 的大规模参数场景。
在软件适配方面,燧原支持 TF/PyTorch 主流框架,提供自动化编译工具,降低 DeepSeek 迁移成本。
关于燧原适配 DeepSeek 面临的挑战,其生态影响力较弱,需依赖客户定制化合作。
沐曦(MXN)
沐曦的优势在于 GPU 通用性与 CUDA 兼容性。
在兼容性方面,MXN 系列兼容 CUDA,若 DeepSeek 重度依赖 CUDA 生态,沐曦的迁移成本相对较低。
在产品性能方面,沐曦 GPU 理论算力对标国际旗舰产品,适合高算力需求场景。
关于沐曦适配 DeepSeek 面临的挑战,产品量产进度和实际落地案例较少,需验证稳定性。
天数智芯(天垓)
天数智芯的优势在于兼容 CUDA 生态。
从生态适配方面,天垓 BI 芯片兼容 CUDA,对已有代码库的 DeepSeek 项目友好。
关于天数智芯适配 DeepSeek 面临的挑战,高端算力不足,支撑千亿级大模型训练存在压力。
壁仞科技(BR 系列)
壁仞科技的单芯片算力峰值高。
从硬件指标来看,高算力峰值使其适合需要极致算力的 DeepSeek 任务。
关于壁仞适配 DeepSeek 面临的挑战,软件栈成熟度待提升。
昆仑芯
与百度 PaddlePaddle 深度绑定,若 DeepSeek 与百度生态协同,适配性较强。
摩尔线程(MTT S 系列)
聚焦图形渲染与 AI 融合场景,适合 DeepSeek 的多模态应用(如 3D 视觉),但通用计算能力有限。
云天励飞/太初元碁
侧重边缘端推理,若 DeepSeek 部署在终端设备,这两家更具优势。
龙芯
龙芯目前以 CPU 为主,GPU 产品处于早期阶段,适配 DeepSeek 暂不成熟。
在近期行业紧锣密鼓地适配 DeepSeek 系列模型后,如何商用成为这一问题的焦点。
DeepSeek 商用,有哪些形式?
云上部署
比如:DeepSeek 模型通过华为云平台提供服务,企业客户可以通过 API 调用或云服务直接使用 DeepSeek 的功能,如图像识别、自然语言处理、语音识别等。企业根据实际使用量(如计算资源、API 调用次数)付费,降低前期投入成本。云服务模式无需企业本地部署硬件,能够快速上线和应用。
本地化部署
一体机形式:目前 DeepSeek 大模型一体机分为推理一体机和训推一体机。DeepSeek 推理一体机内置 DeepSeek-R1 32B、70B、满血版 671B 等不同尺寸模型,价格在几十万到数百万不等,主要面向对数据安全、数据隐私较为敏感的企业用户。而训推一体机的售价更高,用于 DeepSeek-R1 32B 模型的预训练和微调的一体机价格就达到数百万。
企业自行部署:对于对性能要求极高的企业(如自动驾驶、金融风控)或者对安全性需求极高的企业(如政府和金融机构),DeepSeek 模型可以本地部署在 GPU 芯片等硬件上,实现「满血」性能。
从当前的商用模式来看,由于本地部署 GPU 芯片和 DeepSeek 模型的成本较高,企业用户会先在公有云上进行测试,与需求是否适配,再考虑私有云部署、一体机等形式。因此,中小企业可能更倾向于通过云服务使用相关技术。
自然,部分对数据安全高度重视或急需高性能算力的企业,不惜投入十万乃至百万资金,部署一体机以满足自身需求。随着 DeepSeek 开源模型的发展,其私有化部署需求日益凸显,一体机化等相关市场正蓬勃发展,吸引众多企业投身其中。
DeepSeek 商业化,芯片公司谁做的更好?
在 DeepSeek 概念里,昇腾和海光的商业化都取得了不错的进展。
一体机热销,昇腾得到利好
昇腾:70% 的企业将基于昇腾向 DeepSeek 靠拢。
近日,DeepSeek 一体机的发布厂商包括华鲲振宇、宝德、神州鲲泰、长江计算等,均基于昇腾产品构建。
可以看到,随着 DeepSeek 一体机的密集发布,昇腾的产业联盟正在不断扩大。
据悉,目前已有超过 80 家企业基于昇腾快速适配或上线了 DeepSeek 系列模型,并对外提供服务。预计未来两周内,还将有 20 多家企业完成上线。这意味着,国内 70% 的企业将基于昇腾向 DeepSeek 靠拢。
相较于进口 GPU 方案,昇腾芯片的本地化服务和团队对部署 DeepSeek 的效果影响显著。以万卡规模的数据中心为例,MindSpore 工具链的自动并行功能使得分布式训练代码量减少了 70%。
海光:智算中心、金融等多场景渗透
海光与 DeepSeek 的合作覆盖智算中心、金融、智能制造等核心场景。
在智算中心方面,海光信息联合青云科技推出「海光 DCU + 基石智算 + DeepSeek 模型」方案,支持按 Token 计费的灵活调用模式,降低企业 AI 应用门槛。
在金融科技方面,中科金财与海光信息技术股份有限公司联合推出了软硬一体解决方案。该方案融合了自研的多场景多基座大模型引擎与海光 DCU 系列加速卡,并完成了与 DeepSeek 模型的深度适配。
在智能制造方面,海光 DCU 通过适配 DeepSeek-Janus-Pro 多模态模型,赋能工业视觉检测与自动化决策,助力三一重工等企业实现产线智能化升级。
在数据管理方面,空天数智打造的「睿思矩阵数据存管用平台」全面适配海光 DCU,将 DeepSeek 嵌入平台,作为「超级引擎」深入海量数据,为自然资源、能源电力、航空航天等领域提供数据处理支持。
此外,新致软件联合中科海光,正式发布新致信创一体机——以海光 K100 GPU 服务器为算力基石,深度融合新致新知人工智能平台与 DeepSeek 系列大模型,为企业提供从芯片到模型的全栈国产化 AI 解决方案,开启安全、高效、敏捷的智能化转型新时代。
京东云也发布 DeepSeek 大模型一体机,支持华为昇腾、海光等国产 AI 加速芯片。
国产 GPU,机会来了
随着 DeepSeek 一体机等应用的推出和广泛应用,市场对国产芯片的需求正在显著增加。
沐曦科技 CTO 杨建表示,大模型后训练部分预计今年会有更多非英伟达卡加入,DeepSeek 推动的大模型私有化部署,对国产芯片而言也是机会。
「2025 年国产 GPU 的一个机会在于私有化部署,基本上这个市场会以大模型后训练和推理为主。」杨建表示,基于英伟达应用于 AI 领域的 GPU 进入国内市场的方式,英伟达卡在零售市场上基本消失了,而私有化部署较依赖零售市场。若私有化部署市场爆发,国产卡将会有很大机会。
随着海外芯片算力限制带来的难题逼近,全球算力可能会形成两条并行路线,逐渐脱钩。到 2026 年、2027 年,美国预训练和后训练的算力基座预计仍是英伟达,在国内则是有一部分由英伟达承担、一部分由国产芯片承担。其中,后训练部分今年逐渐会有更多非英伟达卡加入,这是因为后训练对集群要求相对较低,不太需要千卡以上集群。
天数智芯相关人士也表示,随着国产模型取得突破,对国产芯片适配需求增加,今年国产芯片有较大发展机会。
DeepSeek 模型的火热也暗含着 AI 应用爆发的机会,芯片厂商将目光转向 AI 应用所需的推理算力。去年国内评测芯片时主要着眼训练,将国产芯片作为英伟达训练的替代品,2025 年开始将有一个变化,即大家会逐渐看国产芯片在推理市场的机会。
上海人工智能研究院数字经济研究中心资深咨询顾问于清扬提到 DeepSeek 对国产芯片的促进。「DeepSeek 通过强化学习机制将模型的无效训练降低 60%,对并行计算的需求较传统架构降低 40%,使国产芯片在特定计算任务中的能效比可达英伟达 GPU 的 75%。」
与此同时,不仅限于 GPU 芯片,在 AI 推理侧有细分优势的 ASIC、FPGA 等芯片也将有丰富的发展机会。值得注意的是,虽然前文所述 DeepSeek 的火热给国产芯片公司带来诸多机遇,但是由于 DeepSeek 对英伟达 CUDA 生态仍有明显的路径依赖,国产芯片公司还需在互联和生态等诸多方面进一步完善。

评论